 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Federated Learning at Scale: System Design
Mar 22, 2019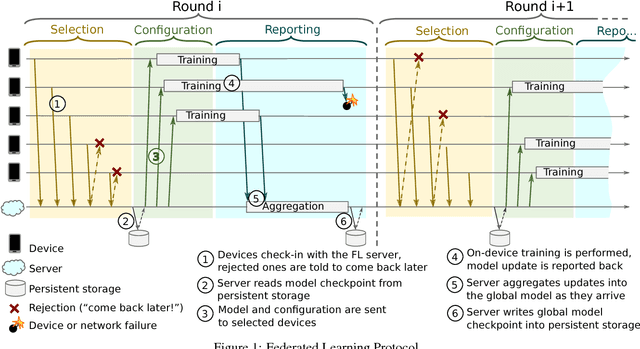
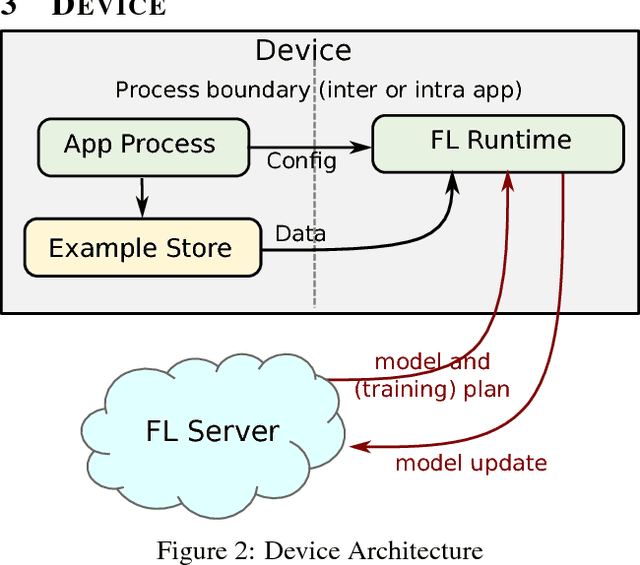
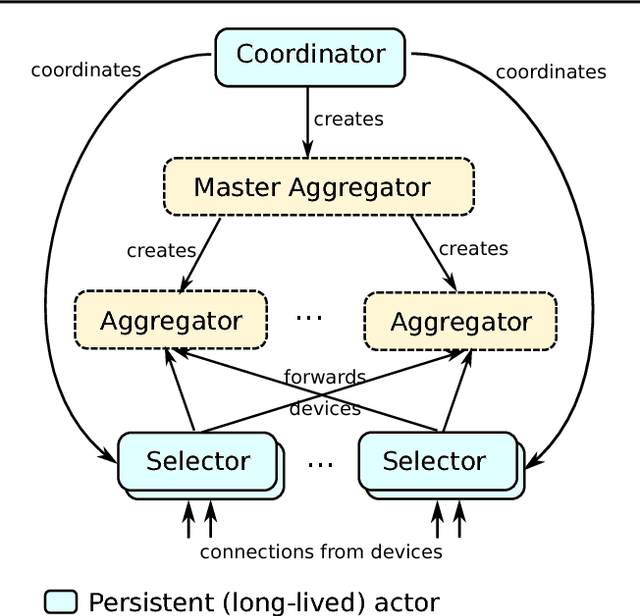
Federated Learning is a distributed machine learning approach which enables model training on a large corpus of decentralized data. We have built a scalable production system for Federated Learning in the domain of mobile devices, based on TensorFlow. In this paper, we describe the resulting high-level design, sketch some of the challenges and their solutions, and touch upon the open problems and future directions.
YouTube-BoundingBoxes: A Large High-Precision Human-Annotated Data Set for Object Detection in Video
Mar 24, 2017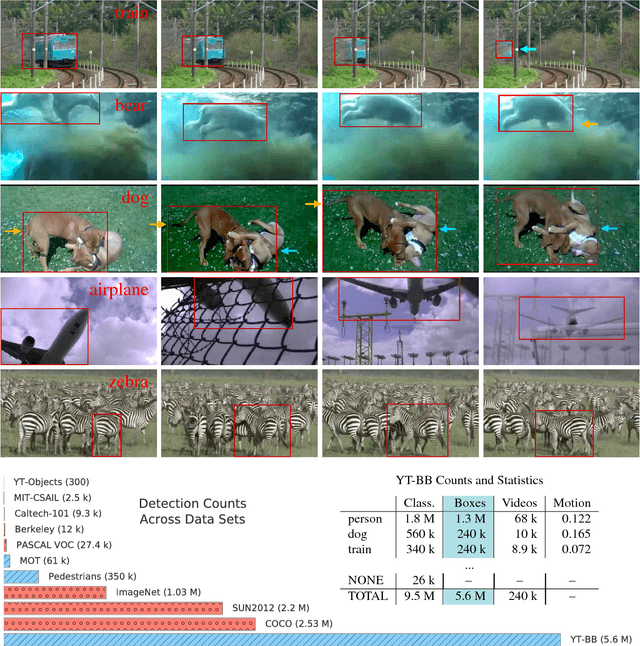
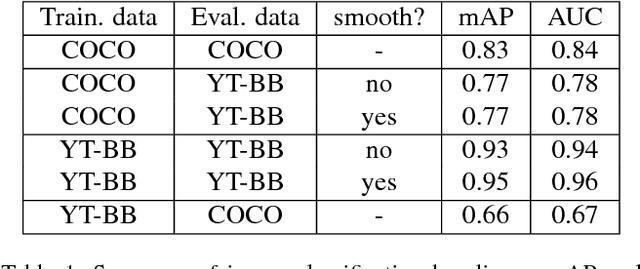


We introduce a new large-scale data set of video URLs with densely-sampled object bounding box annotations called YouTube-BoundingBoxes (YT-BB). The data set consists of approximately 380,000 video segments about 19s long, automatically selected to feature objects in natural settings without editing or post-processing, with a recording quality often akin to that of a hand-held cell phone camera. The objects represent a subset of the MS COCO label set. All video segments were human-annotated with high-precision classification labels and bounding boxes at 1 frame per second. The use of a cascade of increasingly precise human annotations ensures a label accuracy above 95% for every class and tight bounding boxes. Finally, we train and evaluate well-known deep network architectures and report baseline figures for per-frame classification and localization to provide a point of comparison for future work. We also demonstrate how the temporal contiguity of video can potentially be used to improve such inferences. Please see the PDF file to find the URL to download the data. We hope the availability of such large curated corpus will spur new advances in video object detection and tracking.