 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances and Open Problems in Federated Learning
Dec 10, 2019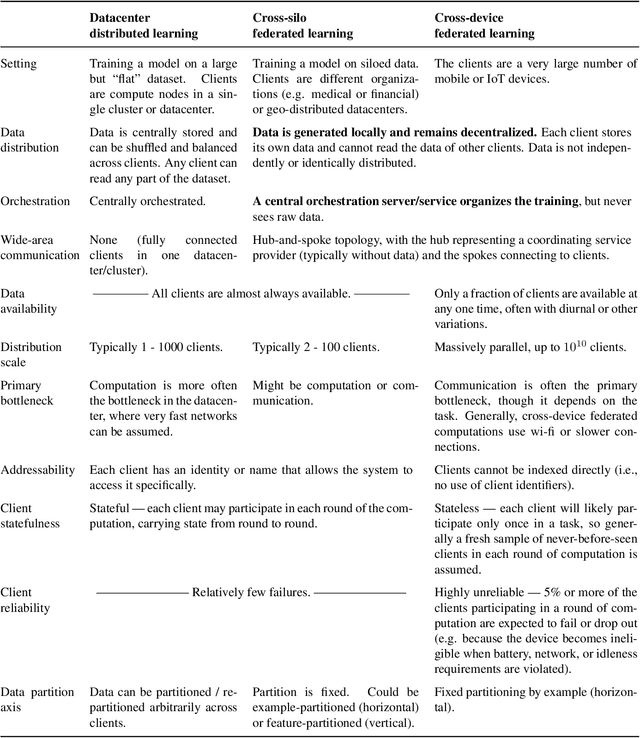

Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning and data science approaches. Motivated by the explosive growth in FL research, this paper discusses recent advances and presents an extensive collection of open problems and challenges.
Federated Learning with Autotuned Communication-Efficient Secure Aggregation
Nov 30, 2019
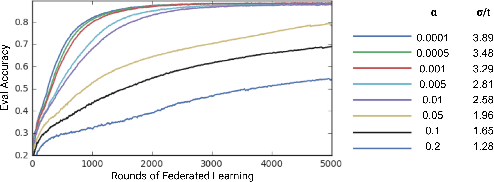
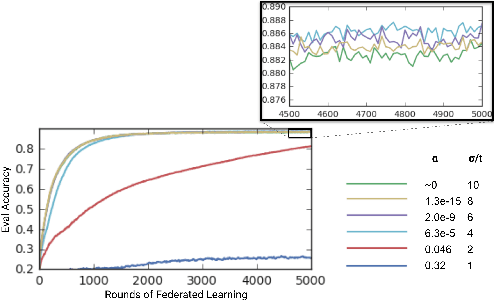
Federated Learning enables mobile devices to collaboratively learn a shared inference model while keeping all the training data on a user's device, decoupling the ability to do machine learning from the need to store the data in the cloud. Existing work on federated learning with limited communication demonstrates how random rotation can enable users' model updates to be quantized much more efficiently, reducing the communication cost between users and the server. Meanwhile, secure aggregation enables the server to learn an aggregate of at least a threshold number of device's model contributions without observing any individual device's contribution in unaggregated form. In this paper, we highlight some of the challenges of setting the parameters for secure aggregation to achieve communication efficiency, especially in the context of the aggressively quantized inputs enabled by random rotation. We then develop a recipe for auto-tuning communication-efficient secure aggregation, based on specific properties of random rotation and secure aggregation -- namely, the predictable distribution of vector entries post-rotation and the modular wrapping inherent in secure aggregation. We present both theoretical results and initial experiments.
Context-Aware Local Differential Privacy
Oct 31, 2019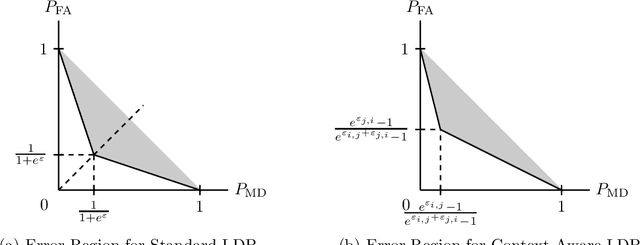
Local differential privacy (LDP) is a strong notion of privacy for individual users that often comes at the expense of a significant drop in utility. The classical definition of LDP assumes that all elements in the data domain are equally sensitive. However, in many applications, some symbols are more sensitive than others. This work proposes a context-aware framework of local differential privacy that allows a privacy designer to incorporate the application's context into the privacy definition. For binary data domains, we provide a universally optimal privatization scheme and highlight its connections to Warner's randomized response (RR) and Mangat's improved response. Motivated by geolocation and web search applications, for $k$-ary data domains, we consider two special cases of context-aware LDP: block-structured LDP and high-low LDP. We study discrete distribution estimation and provide communication-efficient, sample-optimal schemes and information-theoretic lower bounds for both models. We show that using contextual information can require fewer samples than classical LDP to achieve the same accuracy.
Towards Federated Learning at Scale: System Design
Mar 22, 2019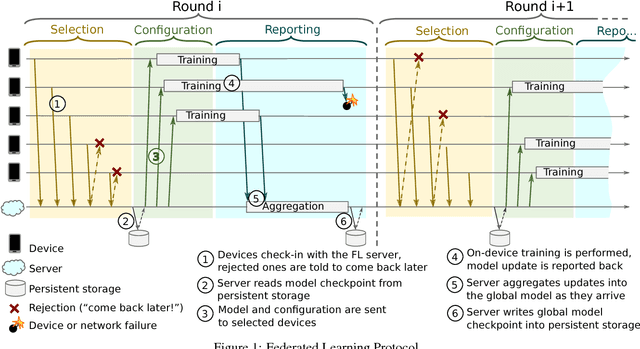
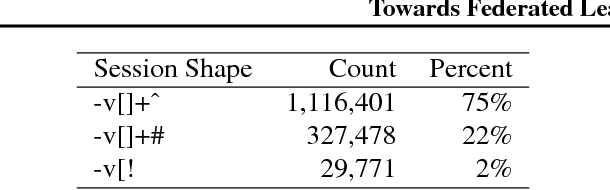
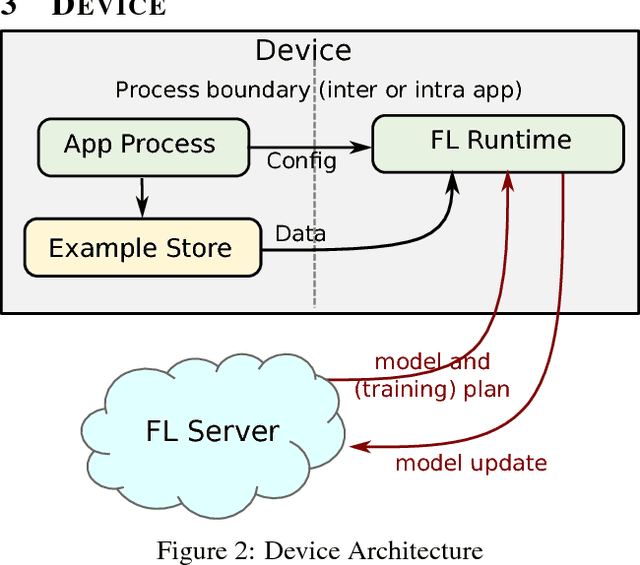
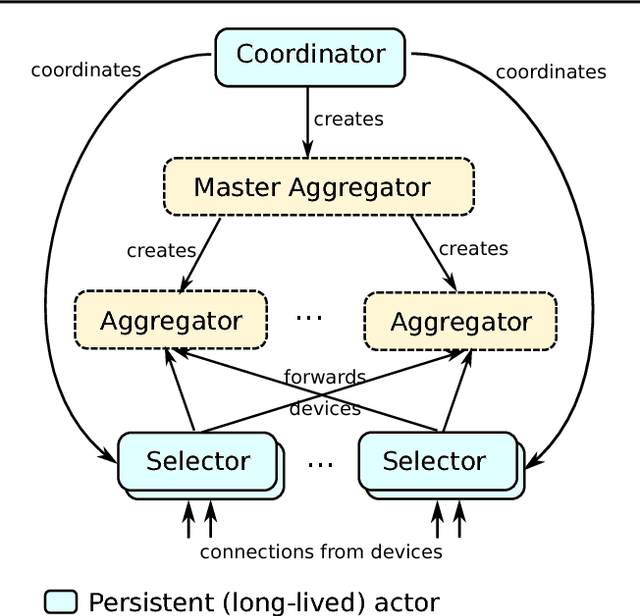
Federated Learning is a distributed machine learning approach which enables model training on a large corpus of decentralized data. We have built a scalable production system for Federated Learning in the domain of mobile devices, based on TensorFlow. In this paper, we describe the resulting high-level design, sketch some of the challenges and their solutions, and touch upon the open problems and future directions.
Practical Secure Aggregation for Federated Learning on User-Held Data
Nov 14, 2016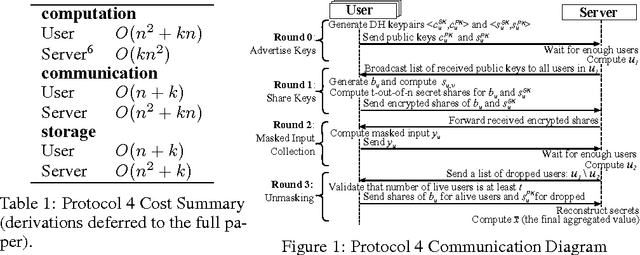
Secure Aggregation protocols allow a collection of mutually distrust parties, each holding a private value, to collaboratively compute the sum of those values without revealing the values themselves. We consider training a deep neural network in the Federated Learning model, using distributed stochastic gradient descent across user-held training data on mobile devices, wherein Secure Aggregation protects each user's model gradient. We design a novel, communication-efficient Secure Aggregation protocol for high-dimensional data that tolerates up to 1/3 users failing to complete the protocol. For 16-bit input values, our protocol offers 1.73x communication expansion for $2^{10}$ users and $2^{20}$-dimensional vectors, and 1.98x expansion for $2^{14}$ users and $2^{24}$ dimensional vectors.
Discrete Distribution Estimation under Local Privacy
Jun 15, 2016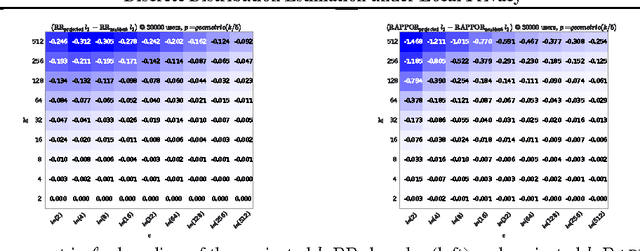
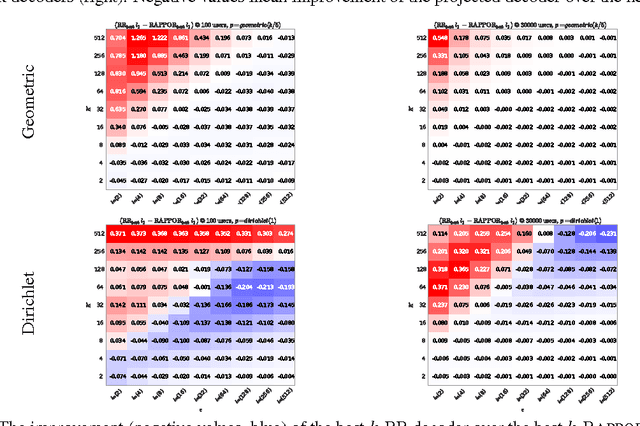
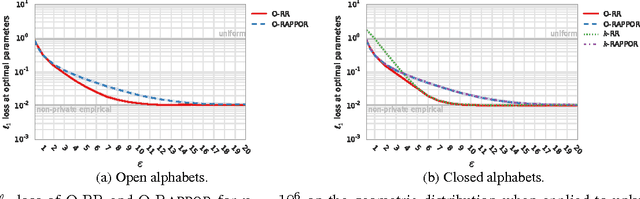
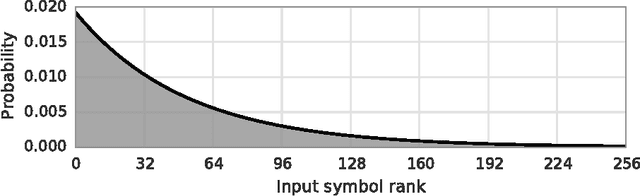
The collection and analysis of user data drives improvements in the app and web ecosystems, but comes with risks to privacy. This paper examines discrete distribution estimation under local privacy, a setting wherein service providers can learn the distribution of a categorical statistic of interest without collecting the underlying data. We present new mechanisms, including hashed K-ary Randomized Response (KRR), that empirically meet or exceed the utility of existing mechanisms at all privacy levels. New theoretical results demonstrate the order-optimality of KRR and the existing RAPPOR mechanism at different privacy regimes.
Church: a language for generative models
Jul 15, 2014

We introduce Church, a universal language for describing stochastic generative processes. Church is based on the Lisp model of lambda calculus, containing a pure Lisp as its deterministic subset. The semantics of Church is defined in terms of evaluation histories and conditional distributions on such histories. Church also includes a novel language construct, the stochastic memoizer, which enables simple description of many complex non-parametric models. We illustrate language features through several examples, including: a generalized Bayes net in which parameters cluster over trials, infinite PCFGs, planning by inference, and various non-parametric clustering models. Finally, we show how to implement query on any Church program, exactly and approximately, using Monte Carlo techniques.