 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing the State-of-the-Art in Empirical Privacy Auditing
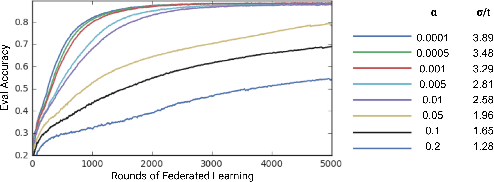
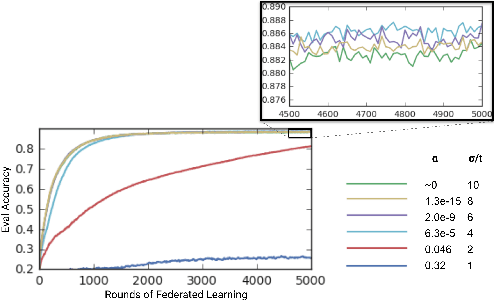
Jun 09, 2026Parameter-efficient fine-tuning of large language models (LLMs) can exhibit problematic memorization of individual training examples. Empirical privacy auditing (EPA) quantifies this risk by measuring realistic data leakage on membership inference (MI) or reconstruction attacks. A key challenge in EPA is designing ``canary'' examples that are mixed with the privacy-sensitive training data. We propose generating synthetic canaries via high-temperature sampling ($T \geq 0.8$) from LLMs, using prompts tailored to the privacy-sensitive training data. These canaries act as high-influence outliers, ensuring high identifiability and hence strong audits. Further, since the canaries are themselves non-private, they are inspectable and can be inserted with repetition without jeopardizing the privacy of the real data. An important use of models fine-tuned on privacy-sensitive data is the generation of synthetic data. This also comes with privacy risk. We introduce a powerful synthetic data audit based on fine-tuning an auxiliary model on the synthetic data. Auditing the auxiliary model for the original canaries then provides a strong estimate of the privacy leakage through the synthetic data. Finally, leveraging our strong auditing methodologies, we perform a systematic investigation into the interacting effects of model capacity and canary entropy on memorization.
On Design Principles for Private Adaptive Optimizers
Jul 01, 2025The spherical noise added to gradients in differentially private (DP) training undermines the performance of adaptive optimizers like AdaGrad and Adam, and hence many recent works have proposed algorithms to address this challenge. However, the empirical results in these works focus on simple tasks and models and the conclusions may not generalize to model training in practice. In this paper we survey several of these variants, and develop better theoretical intuition for them as well as perform empirical studies comparing them. We find that a common intuition of aiming for unbiased estimates of second moments of gradients in adaptive optimizers is misguided, and instead that a simple technique called scale-then-privatize (which does not achieve unbiased second moments) has more desirable theoretical behaviors and outperforms all other variants we study on a small-scale language model training task. We additionally argue that scale-then-privatize causes the noise addition to better match the application of correlated noise mechanisms which are more desirable to use in practice.
It's My Data Too: Private ML for Datasets with Multi-User Training Examples
Mar 05, 2025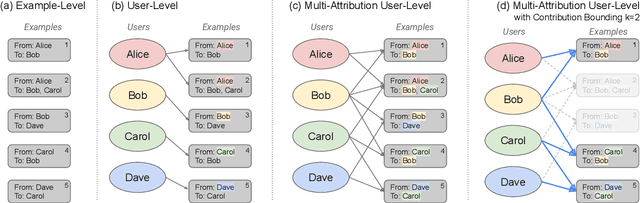
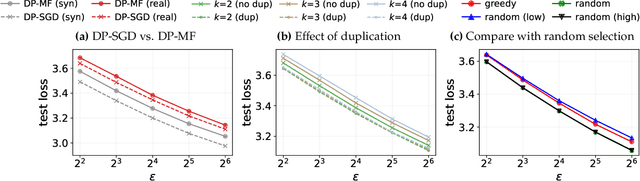
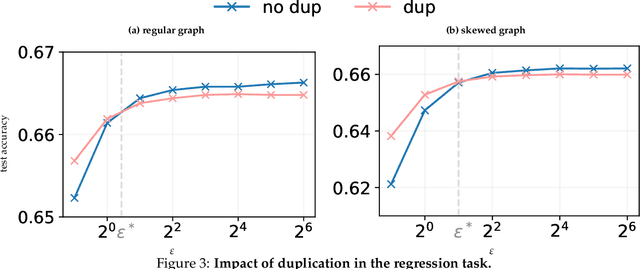
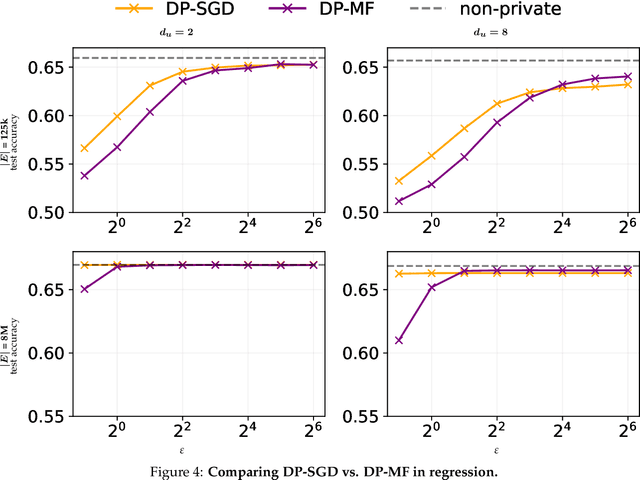
We initiate a study of algorithms for model training with user-level differential privacy (DP), where each example may be attributed to multiple users, which we call the multi-attribution model. We first provide a carefully chosen definition of user-level DP under the multi-attribution model. Training in the multi-attribution model is facilitated by solving the contribution bounding problem, i.e. the problem of selecting a subset of the dataset for which each user is associated with a limited number of examples. We propose a greedy baseline algorithm for the contribution bounding problem. We then empirically study this algorithm for a synthetic logistic regression task and a transformer training task, including studying variants of this baseline algorithm that optimize the subset chosen using different techniques and criteria. We find that the baseline algorithm remains competitive with its variants in most settings, and build a better understanding of the practical importance of a bias-variance tradeoff inherent in solutions to the contribution bounding problem.
Confidential Federated Computations
Apr 16, 2024Federated Learning and Analytics (FLA) have seen widespread adoption by technology platforms for processing sensitive on-device data. However, basic FLA systems have privacy limitations: they do not necessarily require anonymization mechanisms like differential privacy (DP), and provide limited protections against a potentially malicious service provider. Adding DP to a basic FLA system currently requires either adding excessive noise to each device's updates, or assuming an honest service provider that correctly implements the mechanism and only uses the privatized outputs. Secure multiparty computation (SMPC) -based oblivious aggregations can limit the service provider's access to individual user updates and improve DP tradeoffs, but the tradeoffs are still suboptimal, and they suffer from scalability challenges and susceptibility to Sybil attacks. This paper introduces a novel system architecture that leverages trusted execution environments (TEEs) and open-sourcing to both ensure confidentiality of server-side computations and provide externally verifiable privacy properties, bolstering the robustness and trustworthiness of private federated computations.
Convergence of Gradient Descent with Linearly Correlated Noise and Applications to Differentially Private Learning
Feb 02, 2023



We study stochastic optimization with linearly correlated noise. Our study is motivated by recent methods for optimization with differential privacy (DP), such as DP-FTRL, which inject noise via matrix factorization mechanisms. We propose an optimization problem that distils key facets of these DP methods and that involves perturbing gradients by linearly correlated noise. We derive improved convergence rates for gradient descent in this framework for convex and non-convex loss functions. Our theoretical analysis is novel and might be of independent interest. We use these convergence rates to develop new, effective matrix factorizations for differentially private optimization, and highlight the benefits of these factorizations theoretically and empirically.
Federated Select: A Primitive for Communication- and Memory-Efficient Federated Learning
Aug 19, 2022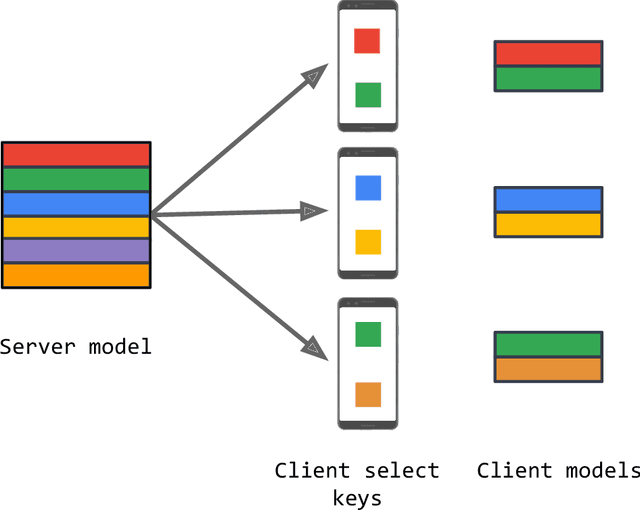

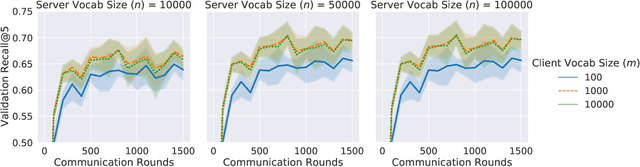
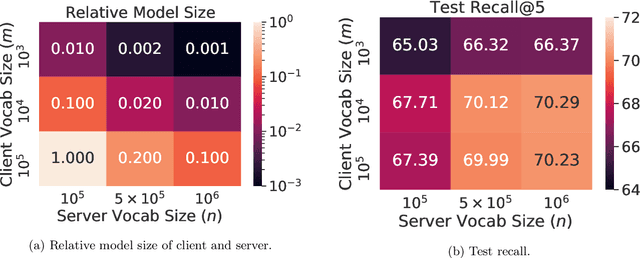
Federated learning (FL) is a framework for machine learning across heterogeneous client devices in a privacy-preserving fashion. To date, most FL algorithms learn a "global" server model across multiple rounds. At each round, the same server model is broadcast to all participating clients, updated locally, and then aggregated across clients. In this work, we propose a more general procedure in which clients "select" what values are sent to them. Notably, this allows clients to operate on smaller, data-dependent slices. In order to make this practical, we outline a primitive, federated select, which enables client-specific selection in realistic FL systems. We discuss how to use federated select for model training and show that it can lead to drastic reductions in communication and client memory usage, potentially enabling the training of models too large to fit on-device. We also discuss the implications of federated select on privacy and trust, which in turn affect possible system constraints and design. Finally, we discuss open questions concerning model architectures, privacy-preserving technologies, and practical FL systems.
Private Online Prefix Sums via Optimal Matrix Factorizations
Feb 16, 2022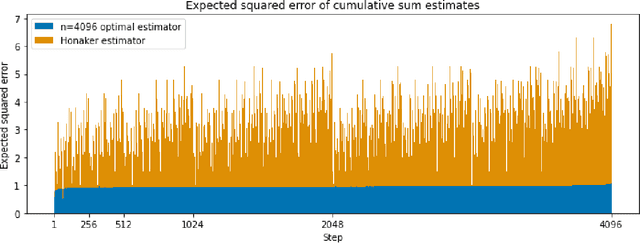
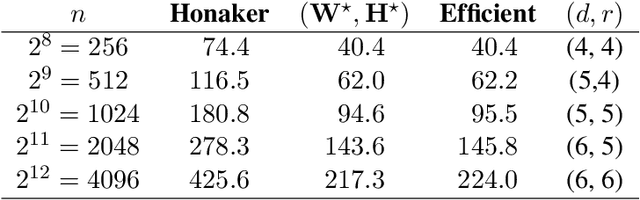
Motivated by differentially-private (DP) training of machine learning models and other applications, we investigate the problem of computing prefix sums in the online (streaming) setting with DP. This problem has previously been addressed by special-purpose tree aggregation schemes with hand-crafted estimators. We show that these previous schemes can all be viewed as specific instances of a broad class of matrix-factorization-based DP mechanisms, and that in fact much better mechanisms exist in this class. In particular, we characterize optimal factorizations of linear queries under online constraints, deriving existence, uniqueness, and explicit expressions that allow us to efficiently compute optimal mechanisms, including for online prefix sums. These solutions improve over the existing state-of-the-art by a significant constant factor, and avoid some of the artifacts introduced by the use of the tree data structure.
Practical and Private (Deep) Learning without Sampling or Shuffling
Feb 26, 2021
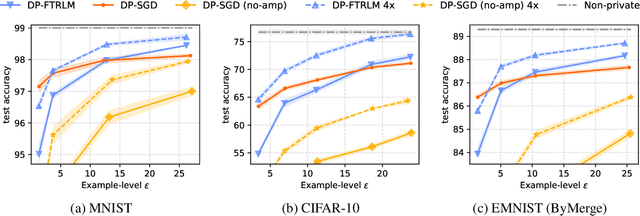
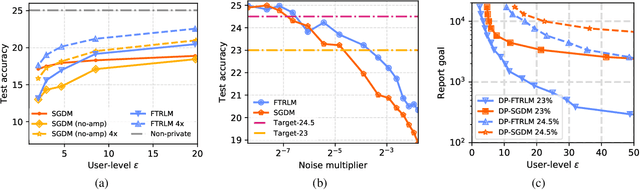
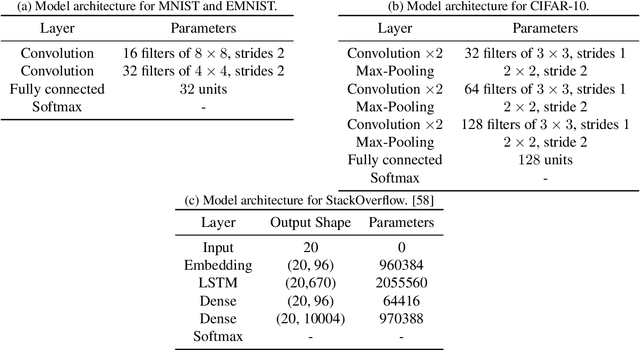
We consider training models with differential privacy (DP) using mini-batch gradients. The existing state-of-the-art, Differentially Private Stochastic Gradient Descent (DP-SGD), requires privacy amplification by sampling or shuffling to obtain the best privacy/accuracy/computation trade-offs. Unfortunately, the precise requirements on exact sampling and shuffling can be hard to obtain in important practical scenarios, particularly federated learning (FL). We design and analyze a DP variant of Follow-The-Regularized-Leader (DP-FTRL) that compares favorably (both theoretically and empirically) to amplified DP-SGD, while allowing for much more flexible data access patterns. DP-FTRL does not use any form of privacy amplification.
Federated Learning with Autotuned Communication-Efficient Secure Aggregation
Nov 30, 2019
Federated Learning enables mobile devices to collaboratively learn a shared inference model while keeping all the training data on a user's device, decoupling the ability to do machine learning from the need to store the data in the cloud. Existing work on federated learning with limited communication demonstrates how random rotation can enable users' model updates to be quantized much more efficiently, reducing the communication cost between users and the server. Meanwhile, secure aggregation enables the server to learn an aggregate of at least a threshold number of device's model contributions without observing any individual device's contribution in unaggregated form. In this paper, we highlight some of the challenges of setting the parameters for secure aggregation to achieve communication efficiency, especially in the context of the aggressively quantized inputs enabled by random rotation. We then develop a recipe for auto-tuning communication-efficient secure aggregation, based on specific properties of random rotation and secure aggregation -- namely, the predictable distribution of vector entries post-rotation and the modular wrapping inherent in secure aggregation. We present both theoretical results and initial experiments.
Graph Oracle Models, Lower Bounds, and Gaps for Parallel Stochastic Optimization
Jul 31, 2018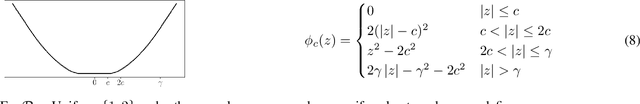
We suggest a general oracle-based framework that captures different parallel stochastic optimization settings described by a dependency graph, and derive generic lower bounds in terms of this graph. We then use the framework and derive lower bounds for several specific parallel optimization settings, including delayed updates and parallel processing with intermittent communication. We highlight gaps between lower and upper bounds on the oracle complexity, and cases where the "natural" algorithms are not known to be optimal.