 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled DiLoCo for Resilient Distributed Pre-training
Apr 23, 2026Modern large-scale language model pre-training relies heavily on the single program multiple data (SPMD) paradigm, which requires tight coupling across accelerators. Due to this coupling, transient slowdowns, hardware failures, and synchronization overhead stall the entire computation, wasting significant compute time at scale. While recent distributed methods like DiLoCo reduced communication bandwidth, they remained fundamentally synchronous and vulnerable to these system stalls. To address this, we introduce Decoupled DiLoCo, an evolution of the DiLoCo framework designed to break the lock-step synchronization barrier and go beyond SPMD to maximize training goodput. Decoupled DiLoCo partitions compute across multiple independent ``learners'' that execute local inner optimization steps. These learners asynchronously communicate parameter fragments to a central synchronizer, which circumvents failed or straggling learners by aggregating updates using a minimum quorum, an adaptive grace window, and dynamic token-weighted merging. Inspired by ``chaos engineering'', we achieve significantly improved training efficiency in failure-prone environments with millions of simulated chips with strictly zero global downtime, while maintaining competitive model performance across text and vision tasks, for both dense and mixture-of-expert architectures.
Local Steps Speed Up Local GD for Heterogeneous Distributed Logistic Regression
Jan 23, 2025


We analyze two variants of Local Gradient Descent applied to distributed logistic regression with heterogeneous, separable data and show convergence at the rate $O(1/KR)$ for $K$ local steps and sufficiently large $R$ communication rounds. In contrast, all existing convergence guarantees for Local GD applied to any problem are at least $\Omega(1/R)$, meaning they fail to show the benefit of local updates. The key to our improved guarantee is showing progress on the logistic regression objective when using a large stepsize $\eta \gg 1/K$, whereas prior analysis depends on $\eta \leq 1/K$.
Gradient Descent Converges Linearly to Flatter Minima than Gradient Flow in Shallow Linear Networks
Jan 15, 2025We study the gradient descent (GD) dynamics of a depth-2 linear neural network with a single input and output. We show that GD converges at an explicit linear rate to a global minimum of the training loss, even with a large stepsize -- about $2/\textrm{sharpness}$. It still converges for even larger stepsizes, but may do so very slowly. We also characterize the solution to which GD converges, which has lower norm and sharpness than the gradient flow solution. Our analysis reveals a trade off between the speed of convergence and the magnitude of implicit regularization. This sheds light on the benefits of training at the ``Edge of Stability'', which induces additional regularization by delaying convergence and may have implications for training more complex models.
Two Losses Are Better Than One: Faster Optimization Using a Cheaper Proxy
Feb 07, 2023We present an algorithm for minimizing an objective with hard-to-compute gradients by using a related, easier-to-access function as a proxy. Our algorithm is based on approximate proximal point iterations on the proxy combined with relatively few stochastic gradients from the objective. When the difference between the objective and the proxy is $\delta$-smooth, our algorithm guarantees convergence at a rate matching stochastic gradient descent on a $\delta$-smooth objective, which can lead to substantially better sample efficiency. Our algorithm has many potential applications in machine learning, and provides a principled means of leveraging synthetic data, physics simulators, mixed public and private data, and more.
Asynchronous SGD Beats Minibatch SGD Under Arbitrary Delays
Jun 15, 2022
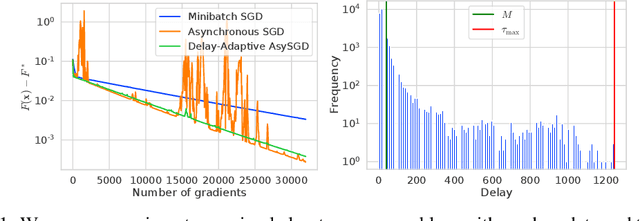

The existing analysis of asynchronous stochastic gradient descent (SGD) degrades dramatically when any delay is large, giving the impression that performance depends primarily on the delay. On the contrary, we prove much better guarantees for the same asynchronous SGD algorithm regardless of the delays in the gradients, depending instead just on the number of parallel devices used to implement the algorithm. Our guarantees are strictly better than the existing analyses, and we also argue that asynchronous SGD outperforms synchronous minibatch SGD in the settings we consider. For our analysis, we introduce a novel recursion based on "virtual iterates" and delay-adaptive stepsizes, which allow us to derive state-of-the-art guarantees for both convex and non-convex objectives.
Non-Convex Optimization with Certificates and Fast Rates Through Kernel Sums of Squares
Apr 11, 2022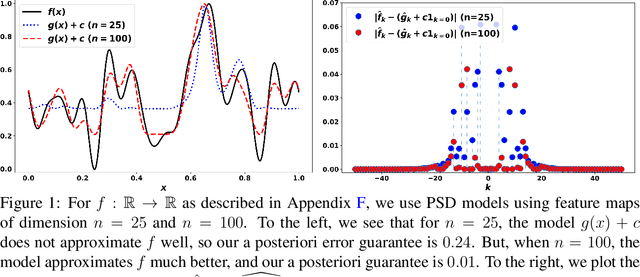
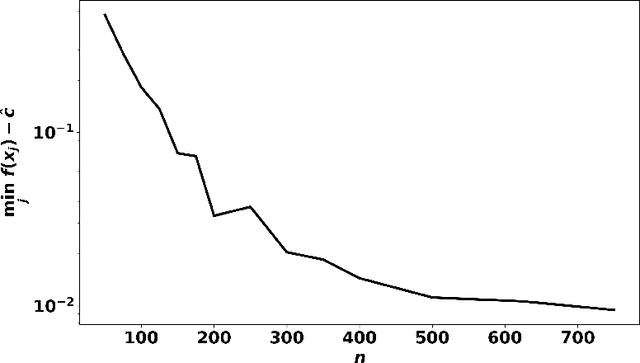
We consider potentially non-convex optimization problems, for which optimal rates of approximation depend on the dimension of the parameter space and the smoothness of the function to be optimized. In this paper, we propose an algorithm that achieves close to optimal a priori computational guarantees, while also providing a posteriori certificates of optimality. Our general formulation builds on infinite-dimensional sums-of-squares and Fourier analysis, and is instantiated on the minimization of multivariate periodic functions.
A Stochastic Newton Algorithm for Distributed Convex Optimization
Oct 07, 2021
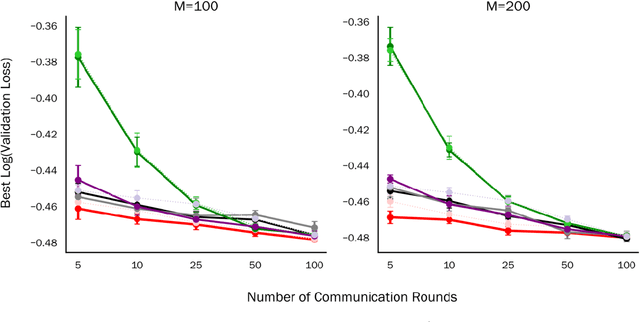

We propose and analyze a stochastic Newton algorithm for homogeneous distributed stochastic convex optimization, where each machine can calculate stochastic gradients of the same population objective, as well as stochastic Hessian-vector products (products of an independent unbiased estimator of the Hessian of the population objective with arbitrary vectors), with many such stochastic computations performed between rounds of communication. We show that our method can reduce the number, and frequency, of required communication rounds compared to existing methods without hurting performance, by proving convergence guarantees for quasi-self-concordant objectives (e.g., logistic regression), alongside empirical evidence.
The Minimax Complexity of Distributed Optimization
Sep 01, 2021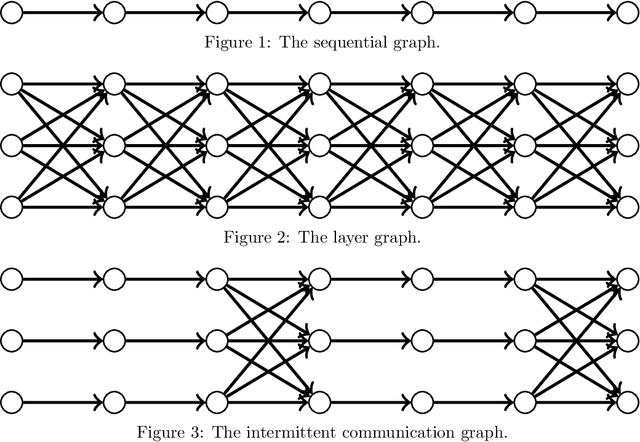

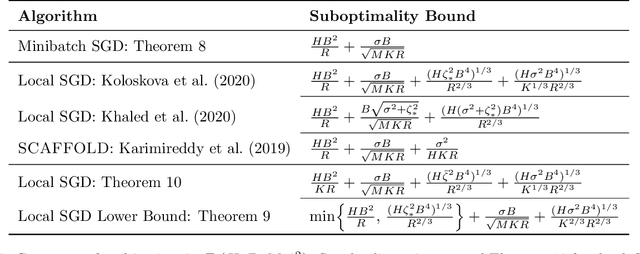

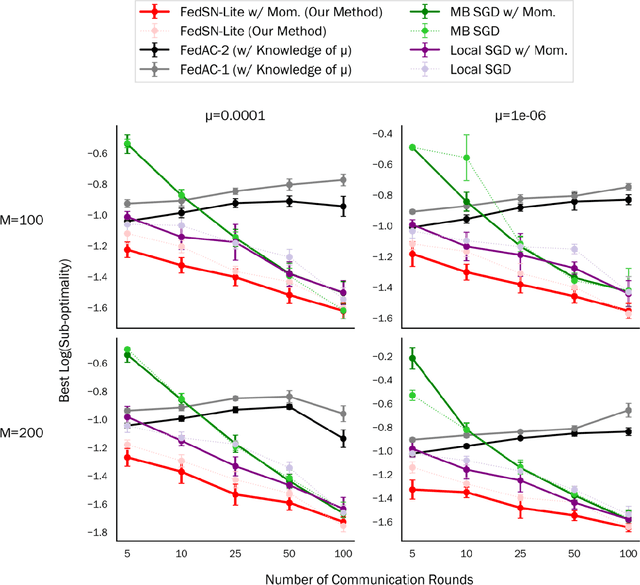
In this thesis, I study the minimax oracle complexity of distributed stochastic optimization. First, I present the "graph oracle model", an extension of the classic oracle complexity framework that can be applied to study distributed optimization algorithms. Next, I describe a general approach to proving optimization lower bounds for arbitrary randomized algorithms (as opposed to more restricted classes of algorithms, e.g., deterministic or "zero-respecting" algorithms), which is used extensively throughout the thesis. For the remainder of the thesis, I focus on the specific case of the "intermittent communication setting", where multiple computing devices work in parallel with limited communication amongst themselves. In this setting, I analyze the theoretical properties of the popular Local Stochastic Gradient Descent (SGD) algorithm in convex setting, both for homogeneous and heterogeneous objectives. I provide the first guarantees for Local SGD that improve over simple baseline methods, but show that Local SGD is not optimal in general. In pursuit of optimal methods in the intermittent communication setting, I then show matching upper and lower bounds for the intermittent communication setting with homogeneous convex, heterogeneous convex, and homogeneous non-convex objectives. These upper bounds are attained by simple variants of SGD which are therefore optimal. Finally, I discuss several additional assumptions about the objective or more powerful oracles that might be exploitable in order to develop better intermittent communication algorithms with better guarantees than our lower bounds allow.
A Field Guide to Federated Optimization
Jul 14, 2021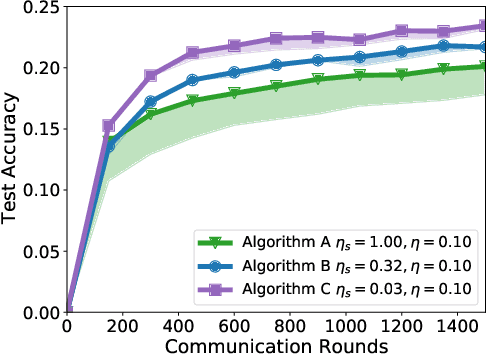


Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.
An Even More Optimal Stochastic Optimization Algorithm: Minibatching and Interpolation Learning
Jun 04, 2021We present and analyze an algorithm for optimizing smooth and convex or strongly convex objectives using minibatch stochastic gradient estimates. The algorithm is optimal with respect to its dependence on both the minibatch size and minimum expected loss simultaneously. This improves over the optimal method of Lan (2012), which is insensitive to the minimum expected loss; over the optimistic acceleration of Cotter et al. (2011), which has suboptimal dependence on the minibatch size; and over the algorithm of Liu and Belkin (2018), which is limited to least squares problems and is also similarly suboptimal with respect to the minibatch size. Applied to interpolation learning, the improvement over Cotter et al. and Liu and Belkin translates to a linear, rather than square-root, parallelization speedup.