 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes SGD Seek Flatness or Sharpness? An Exactly Solvable Model
Feb 04, 2026A large body of theory and empirical work hypothesizes a connection between the flatness of a neural network's loss landscape during training and its performance. However, there have been conceptually opposite pieces of evidence regarding when SGD prefers flatter or sharper solutions during training. In this work, we partially but causally clarify the flatness-seeking behavior of SGD by identifying and exactly solving an analytically solvable model that exhibits both flattening and sharpening behavior during training. In this model, the SGD training has no \textit{a priori} preference for flatness, but only a preference for minimal gradient fluctuations. This leads to the insight that, at least within this model, it is data distribution that uniquely determines the sharpness at convergence, and that a flat minimum is preferred if and only if the noise in the labels is isotropic across all output dimensions. When the noise in the labels is anisotropic, the model instead prefers sharpness and can converge to an arbitrarily sharp solution, depending on the imbalance in the noise in the labels spectrum. We reproduce this key insight in controlled settings with different model architectures such as MLP, RNN, and transformers.
Gradient Descent Converges Linearly to Flatter Minima than Gradient Flow in Shallow Linear Networks
Jan 15, 2025We study the gradient descent (GD) dynamics of a depth-2 linear neural network with a single input and output. We show that GD converges at an explicit linear rate to a global minimum of the training loss, even with a large stepsize -- about $2/\textrm{sharpness}$. It still converges for even larger stepsizes, but may do so very slowly. We also characterize the solution to which GD converges, which has lower norm and sharpness than the gradient flow solution. Our analysis reveals a trade off between the speed of convergence and the magnitude of implicit regularization. This sheds light on the benefits of training at the ``Edge of Stability'', which induces additional regularization by delaying convergence and may have implications for training more complex models.
Edge of Stochastic Stability: Revisiting the Edge of Stability for SGD
Dec 29, 2024Recent findings by Cohen et al., 2021, demonstrate that when training neural networks with full-batch gradient descent at a step size of $\eta$, the sharpness--defined as the largest eigenvalue of the full batch Hessian--consistently stabilizes at $2/\eta$. These results have significant implications for convergence and generalization. Unfortunately, this was observed not to be the case for mini-batch stochastic gradient descent (SGD), thus limiting the broader applicability of these findings. We show that SGD trains in a different regime we call Edge of Stochastic Stability. In this regime, what hovers at $2/\eta$ is, instead, the average over the batches of the largest eigenvalue of the Hessian of the mini batch (MiniBS) loss--which is always bigger than the sharpness. This implies that the sharpness is generally lower when training with smaller batches or bigger learning rate, providing a basis for the observed implicit regularization effect of SGD towards flatter minima and a number of well established empirical phenomena. Additionally, we quantify the gap between the MiniBS and the sharpness, further characterizing this distinct training regime.
How Neural Networks Learn the Support is an Implicit Regularization Effect of SGD
Jun 17, 2024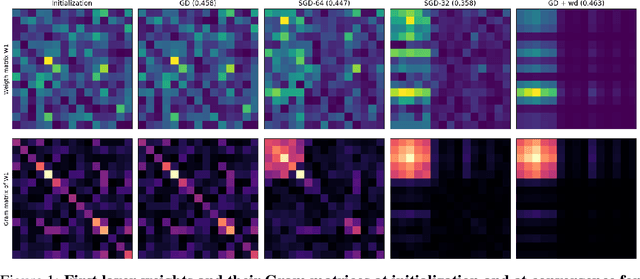


We investigate the ability of deep neural networks to identify the support of the target function. Our findings reveal that mini-batch SGD effectively learns the support in the first layer of the network by shrinking to zero the weights associated with irrelevant components of input. In contrast, we demonstrate that while vanilla GD also approximates the target function, it requires an explicit regularization term to learn the support in the first layer. We prove that this property of mini-batch SGD is due to a second-order implicit regularization effect which is proportional to $\eta / b$ (step size / batch size). Our results are not only another proof that implicit regularization has a significant impact on training optimization dynamics but they also shed light on the structure of the features that are learned by the network. Additionally, they suggest that smaller batches enhance feature interpretability and reduce dependency on initialization.
On the Trajectories of SGD Without Replacement
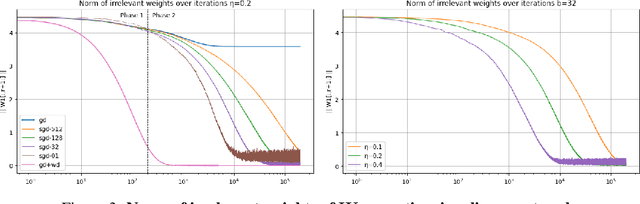
Dec 26, 2023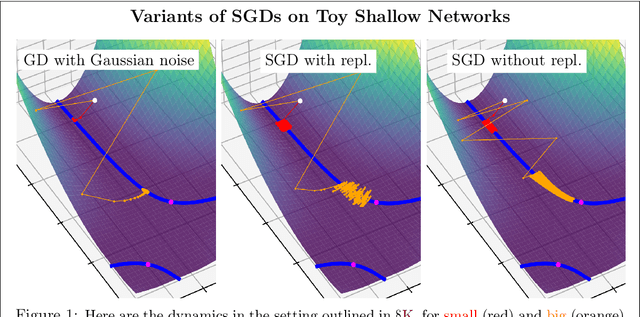
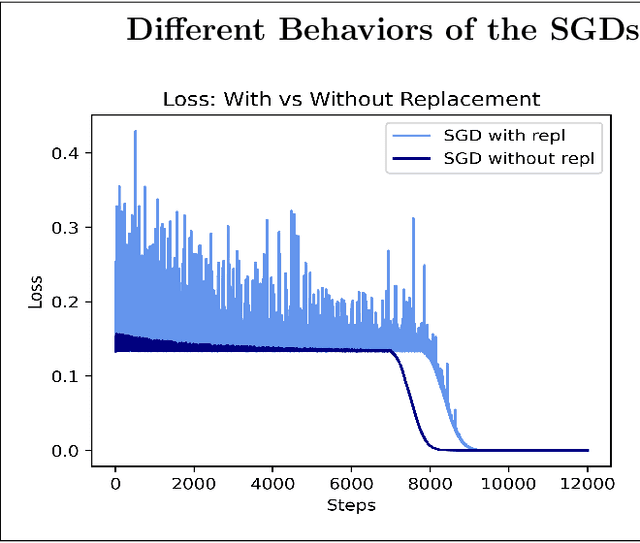
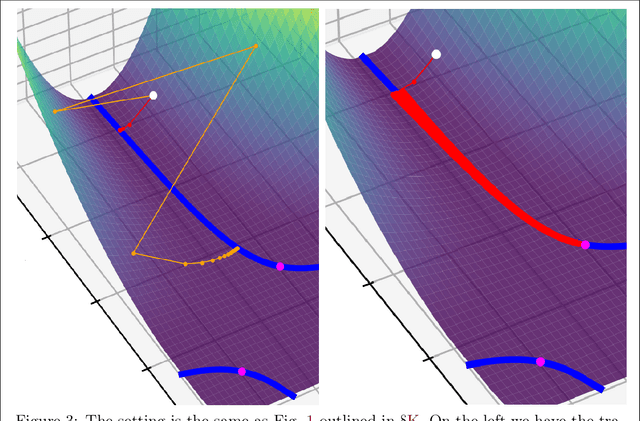
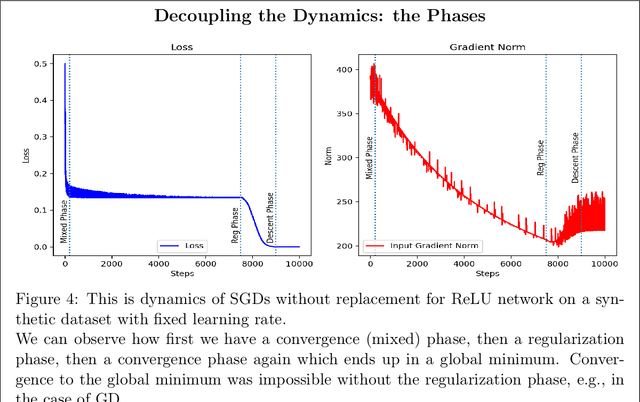
This article examines the implicit regularization effect of Stochastic Gradient Descent (SGD). We consider the case of SGD without replacement, the variant typically used to optimize large-scale neural networks. We analyze this algorithm in a more realistic regime than typically considered in theoretical works on SGD, as, e.g., we allow the product of the learning rate and Hessian to be $O(1)$. Our core theoretical result is that optimizing with SGD without replacement is locally equivalent to making an additional step on a novel regularizer. This implies that the trajectory of SGD without replacement diverges from both noise-injected GD and SGD with replacement (in which batches are sampled i.i.d.). Indeed, the two SGDs travel flat regions of the loss landscape in distinct directions and at different speeds. In expectation, SGD without replacement may escape saddles significantly faster and present a smaller variance. Moreover, we find that SGD implicitly regularizes the trace of the noise covariance in the eigendirections of small and negative Hessian eigenvalues. This coincides with penalizing a weighted trace of the Fisher Matrix and the Hessian on several vision tasks, thus encouraging sparsity in the spectrum of the Hessian of the loss in line with empirical observations from prior work. We also propose an explanation for why SGD does not train at the edge of stability (as opposed to GD).