 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdditive decomposition of one-dimensional signals using Transformers
Jun 06, 2025One-dimensional signal decomposition is a well-established and widely used technique across various scientific fields. It serves as a highly valuable pre-processing step for data analysis. While traditional decomposition techniques often rely on mathematical models, recent research suggests that applying the latest deep learning models to this problem presents an exciting, unexplored area with promising potential. This work presents a novel method for the additive decomposition of one-dimensional signals. We leverage the Transformer architecture to decompose signals into their constituent components: piece-wise constant, smooth (low-frequency oscillatory), textured (high-frequency oscillatory), and a noise component. Our model, trained on synthetic data, achieves excellent accuracy in modeling and decomposing input signals from the same distribution, as demonstrated by the experimental results.
On Generalization Bounds for Neural Networks with Low Rank Layers
Nov 20, 2024
While previous optimization results have suggested that deep neural networks tend to favour low-rank weight matrices, the implications of this inductive bias on generalization bounds remain underexplored. In this paper, we apply Maurer's chain rule for Gaussian complexity to analyze how low-rank layers in deep networks can prevent the accumulation of rank and dimensionality factors that typically multiply across layers. This approach yields generalization bounds for rank and spectral norm constrained networks. We compare our results to prior generalization bounds for deep networks, highlighting how deep networks with low-rank layers can achieve better generalization than those with full-rank layers. Additionally, we discuss how this framework provides new perspectives on the generalization capabilities of deep networks exhibiting neural collapse.
The Fair Language Model Paradox
Oct 15, 2024



Large Language Models (LLMs) are widely deployed in real-world applications, yet little is known about their training dynamics at the token level. Evaluation typically relies on aggregated training loss, measured at the batch level, which overlooks subtle per-token biases arising from (i) varying token-level dynamics and (ii) structural biases introduced by hyperparameters. While weight decay is commonly used to stabilize training, we reveal that it silently introduces performance biases detectable only at the token level. In fact, we empirically show across different dataset sizes, model architectures and sizes ranging from 270M to 3B parameters that as weight decay increases, low-frequency tokens are disproportionately depreciated. This is particularly concerning, as these neglected low-frequency tokens represent the vast majority of the token distribution in most languages, calling for novel regularization techniques that ensure fairness across all available tokens.
How Neural Networks Learn the Support is an Implicit Regularization Effect of SGD
Jun 17, 2024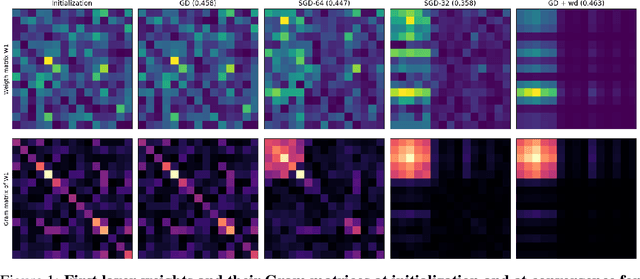

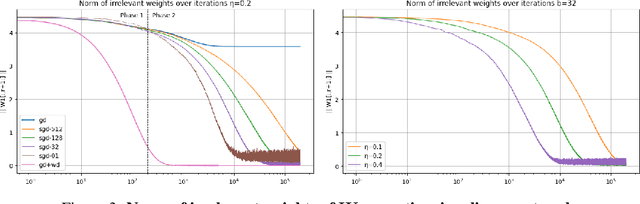

We investigate the ability of deep neural networks to identify the support of the target function. Our findings reveal that mini-batch SGD effectively learns the support in the first layer of the network by shrinking to zero the weights associated with irrelevant components of input. In contrast, we demonstrate that while vanilla GD also approximates the target function, it requires an explicit regularization term to learn the support in the first layer. We prove that this property of mini-batch SGD is due to a second-order implicit regularization effect which is proportional to $\eta / b$ (step size / batch size). Our results are not only another proof that implicit regularization has a significant impact on training optimization dynamics but they also shed light on the structure of the features that are learned by the network. Additionally, they suggest that smaller batches enhance feature interpretability and reduce dependency on initialization.
Privacy and Efficiency of Communications in Federated Split Learning
Jan 07, 2023



Everyday, large amounts of sensitive data is distributed across mobile phones, wearable devices, and other sensors. Traditionally, these enormous datasets have been processed on a single system, with complex models being trained to make valuable predictions. Distributed machine learning techniques such as Federated and Split Learning have recently been developed to protect user data and privacy better while ensuring high performance. Both of these distributed learning architectures have advantages and disadvantages. In this paper, we examine these tradeoffs and suggest a new hybrid Federated Split Learning architecture that combines the efficiency and privacy benefits of both. Our evaluation demonstrates how our hybrid Federated Split Learning approach can lower the amount of processing power required by each client running a distributed learning system, reduce training and inference time while keeping a similar accuracy. We also discuss the resiliency of our approach to deep learning privacy inference attacks and compare our solution to other recently proposed benchmarks.
The effectiveness of factorization and similarity blending
Sep 16, 2022
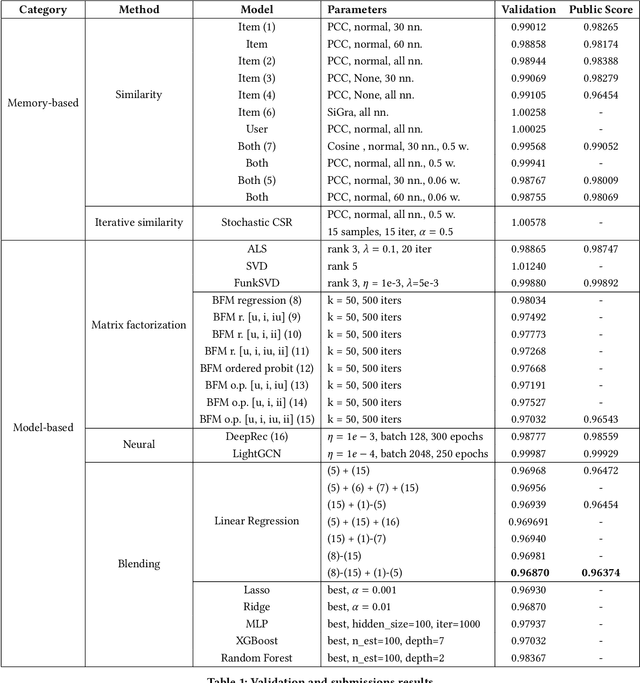
Collaborative Filtering (CF) is a widely used technique which allows to leverage past users' preferences data to identify behavioural patterns and exploit them to predict custom recommendations. In this work, we illustrate our review of different CF techniques in the context of the Computational Intelligence Lab (CIL) CF project at ETH Z\"urich. After evaluating the performances of the individual models, we show that blending factorization-based and similarity-based approaches can lead to a significant error decrease (-9.4%) on the best-performing stand-alone model. Moreover, we propose a novel stochastic extension of a similarity model, SCSR, which consistently reduce the asymptotic complexity of the original algorithm.