 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Systems as Boosting Weak Reasoning Models
May 13, 2026Can a committee of weak reasoning-model calls reach the performance of much stronger models? We study verifier-backed committee search as inference-time boosting for reasoning language models. The mechanism is not simply that ``more agents help'': samples expose latent correct solutions, while critics and comparators must recover them without access to the hidden verifier. We formalize this view by separating proposal coverage, local identifiability, progress, and diversity. We prove that coverage can be amplified by repeated sampling, but cannot by itself create useful critics or comparators; reliable amplification requires an additional local soundness signal, such as execution, proof checking, type checking, tests, or constraint solving. We give rank-based bounds showing when local selection errors compose into reliable trajectories, and characterize the proposer-side ceiling: oracle best-of-\(k\) converges only to the mass of task slices on which the proposal system assigns nonzero useful probability. Empirically, on SWE-bench Verified, a single \texttt{GPT-5.4 nano} proposal solves \(67.0\%\) of tasks. Using the same nano model, our critic--comparator orchestration reaches \(76.4\%\) with \(k=8\) proposals, matching the standalone performance of \texttt{Gemini 3 Pro} and \texttt{Claude Opus 4.5} Thinking and approaching the \(79.0\%\) oracle best-of-\(8\) upper bound. Thus, many correct patches are already present in weak-model proposal pools; the main challenge is selecting them. The remaining failures are mostly proposal-coverage failures, indicating shared blind spots that stronger selection alone cannot close.
Distribution-Aware Algorithm Design with LLM Agents
May 13, 2026We study learning when the learned object is executable solver code rather than a predictor. In this setting, correctness is not enough: two solvers may both return valid solutions on the deployment distribution while differing substantially in runtime. Given samples from an unknown task distribution, the learner returns code evaluated on fresh instances by both solution quality and execution time. Our central abstraction is a \emph{solver hint}: reusable structure inferred from samples and compiled into specialized solver code. We prove that the empirically fastest sample-consistent solver from a fixed library generalizes in both correctness and runtime, and that statistically identifiable hints can be recovered and compiled from polynomially many samples. Empirically, we instantiate the framework with LLM code agents on \(21\) structured combinatorial-optimization target distributions across seven problem classes. The synthesized solvers reach mean normalized quality \(0.971\), improve by \(+0.224\) over the average heuristic pool and by \(+0.098\) over the highest-quality heuristic, and are \(336.9\times\), \(342.8\times\), and \(16.1\times\) faster than the quality-best heuristic, Gurobi, and the selected time-limited exact backend, respectively. On released PACE 2025 Dominating Set private instances, the synthesized solver is valid on all \(100\) graphs and runs about two orders of magnitude faster than top competition solvers, with a moderate quality gap. Inspection shows that many gains come from changing the computational scale: replacing ambient exponential search or general-purpose optimization with compiled distribution-specific computation.
Directional Neural Collapse Explains Few-Shot Transfer in Self-Supervised Learning
Mar 03, 2026Frozen self-supervised representations often transfer well with only a few labels across many semantic tasks. We argue that a single geometric quantity, \emph{directional} CDNV (decision-axis variance), sits at the core of two favorable behaviors: strong few-shot transfer within a task, and low interference across many tasks. We show that both emerge when variability \emph{along} class-separating directions is small. First, we prove sharp non-asymptotic multiclass generalization bounds for downstream classification whose leading term is the directional CDNV. The bounds include finite-shot corrections that cleanly separate intrinsic decision-axis variability from centroid-estimation error. Second, we link decision-axis collapse to multitask geometry: for independent balanced labelings, small directional CDNV across tasks forces the corresponding decision axes to be nearly orthogonal, helping a single representation support many tasks with minimal interference. Empirically, across SSL objectives, directional CDNV collapses during pretraining even when classical CDNV remains large, and our bounds closely track few-shot error at practical shot sizes. Additionally, on synthetic multitask data, we verify that SSL learns representations whose induced decision axes are nearly orthogonal. The code and project page of the paper are available at [\href{https://dlfundamentals.github.io/directional-neural-collapse/}{project page}].
Tool Building as a Path to "Superintelligence"
Feb 24, 2026The Diligent Learner framework suggests LLMs can achieve superintelligence via test-time search, provided a sufficient step-success probability $γ$. In this work, we design a benchmark to measure $γ$ on logical out-of-distribution inference. We construct a class of tasks involving GF(2) circuit reconstruction that grow more difficult with each reasoning step, and that are, from an information-theoretic standpoint, impossible to reliably solve unless the LLM carefully integrates all of the information provided. Our analysis demonstrates that while the $γ$ value for small LLMs declines superlinearly as depth increases, frontier models exhibit partial robustness on this task. Furthermore, we find that successful reasoning at scale is contingent upon precise tool calls, identifying tool design as a critical capability for LLMs to achieve general superintelligence through the Diligent Learner framework.
LLM-ERM: Sample-Efficient Program Learning via LLM-Guided Search
Oct 16, 2025We seek algorithms for program learning that are both sample-efficient and computationally feasible. Classical results show that targets admitting short program descriptions (e.g., with short ``python code'') can be learned with a ``small'' number of examples (scaling with the size of the code) via length-first program enumeration, but the search is exponential in description length. Consequently, Gradient-based training avoids this cost yet can require exponentially many samples on certain short-program families. To address this gap, we introduce LLM-ERM, a propose-and-verify framework that replaces exhaustive enumeration with an LLM-guided search over candidate programs while retaining ERM-style selection on held-out data. Specifically, we draw $k$ candidates with a pretrained reasoning-augmented LLM, compile and check each on the data, and return the best verified hypothesis, with no feedback, adaptivity, or gradients. Theoretically, we show that coordinate-wise online mini-batch SGD requires many samples to learn certain short programs. {\em Empirically, LLM-ERM solves tasks such as parity variants, pattern matching, and primality testing with as few as 200 samples, while SGD-trained transformers overfit even with 100,000 samples}. These results indicate that language-guided program synthesis recovers much of the statistical efficiency of finite-class ERM while remaining computationally tractable, offering a practical route to learning succinct hypotheses beyond the reach of gradient-based training.
Self-Supervised Contrastive Learning is Approximately Supervised Contrastive Learning
Jun 04, 2025

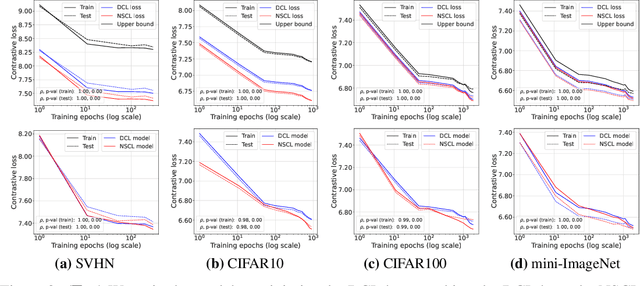

Despite its empirical success, the theoretical foundations of self-supervised contrastive learning (CL) are not yet fully established. In this work, we address this gap by showing that standard CL objectives implicitly approximate a supervised variant we call the negatives-only supervised contrastive loss (NSCL), which excludes same-class contrasts. We prove that the gap between the CL and NSCL losses vanishes as the number of semantic classes increases, under a bound that is both label-agnostic and architecture-independent. We characterize the geometric structure of the global minimizers of the NSCL loss: the learned representations exhibit augmentation collapse, within-class collapse, and class centers that form a simplex equiangular tight frame. We further introduce a new bound on the few-shot error of linear-probing. This bound depends on two measures of feature variability--within-class dispersion and variation along the line between class centers. We show that directional variation dominates the bound and that the within-class dispersion's effect diminishes as the number of labeled samples increases. These properties enable CL and NSCL-trained representations to support accurate few-shot label recovery using simple linear probes. Finally, we empirically validate our theoretical findings: the gap between CL and NSCL losses decays at a rate of $\mathcal{O}(\frac{1}{\#\text{classes}})$; the two losses are highly correlated; minimizing the CL loss implicitly brings the NSCL loss close to the value achieved by direct minimization; and the proposed few-shot error bound provides a tight estimate of probing performance in practice.
DisCO: Reinforcing Large Reasoning Models with Discriminative Constrained Optimization
May 18, 2025The recent success and openness of DeepSeek-R1 have brought widespread attention to Group Relative Policy Optimization (GRPO) as a reinforcement learning method for large reasoning models (LRMs). In this work, we analyze the GRPO objective under a binary reward setting and reveal an inherent limitation of question-level difficulty bias. We also identify a connection between GRPO and traditional discriminative methods in supervised learning. Motivated by these insights, we introduce a new Discriminative Constrained Optimization (DisCO) framework for reinforcing LRMs, grounded in the principle of discriminative learning. The main differences between DisCO and GRPO and its recent variants are: (1) it replaces the group relative objective with a discriminative objective defined by a scoring function; (2) it abandons clipping-based surrogates in favor of non-clipping RL surrogate objectives used as scoring functions; (3) it employs a simple yet effective constrained optimization approach to enforce the KL divergence constraint, ensuring stable training. As a result, DisCO offers notable advantages over GRPO and its variants: (i) it completely eliminates difficulty bias by adopting discriminative objectives; (ii) it addresses the entropy instability in GRPO and its variants through the use of non-clipping scoring functions and a constrained optimization approach; (iii) it allows the incorporation of advanced discriminative learning techniques to address data imbalance, where a significant number of questions have more negative than positive generated answers during training. Our experiments on enhancing the mathematical reasoning capabilities of SFT-finetuned models show that DisCO significantly outperforms GRPO and its improved variants such as DAPO, achieving average gains of 7\% over GRPO and 6\% over DAPO across six benchmark tasks for an 1.5B model.
The Fair Language Model Paradox
Oct 15, 2024



Large Language Models (LLMs) are widely deployed in real-world applications, yet little is known about their training dynamics at the token level. Evaluation typically relies on aggregated training loss, measured at the batch level, which overlooks subtle per-token biases arising from (i) varying token-level dynamics and (ii) structural biases introduced by hyperparameters. While weight decay is commonly used to stabilize training, we reveal that it silently introduces performance biases detectable only at the token level. In fact, we empirically show across different dataset sizes, model architectures and sizes ranging from 270M to 3B parameters that as weight decay increases, low-frequency tokens are disproportionately depreciated. This is particularly concerning, as these neglected low-frequency tokens represent the vast majority of the token distribution in most languages, calling for novel regularization techniques that ensure fairness across all available tokens.
Formation of Representations in Neural Networks
Oct 03, 2024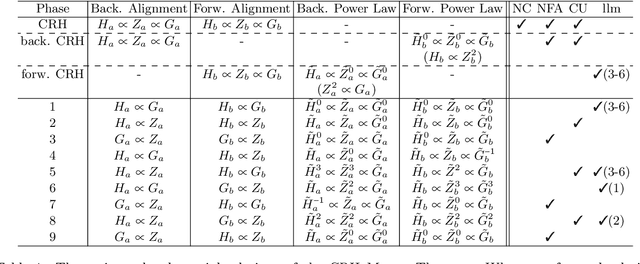
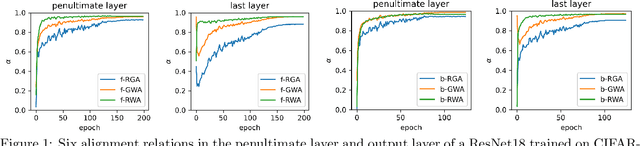
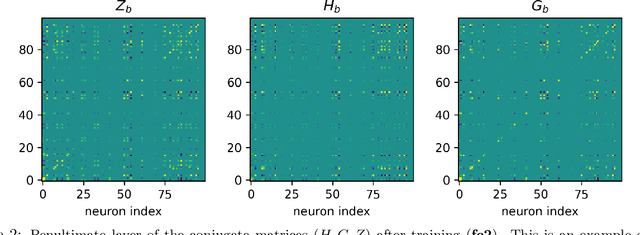

Understanding neural representations will help open the black box of neural networks and advance our scientific understanding of modern AI systems. However, how complex, structured, and transferable representations emerge in modern neural networks has remained a mystery. Building on previous results, we propose the Canonical Representation Hypothesis (CRH), which posits a set of six alignment relations to universally govern the formation of representations in most hidden layers of a neural network. Under the CRH, the latent representations (R), weights (W), and neuron gradients (G) become mutually aligned during training. This alignment implies that neural networks naturally learn compact representations, where neurons and weights are invariant to task-irrelevant transformations. We then show that the breaking of CRH leads to the emergence of reciprocal power-law relations between R, W, and G, which we refer to as the Polynomial Alignment Hypothesis (PAH). We present a minimal-assumption theory demonstrating that the balance between gradient noise and regularization is crucial for the emergence the canonical representation. The CRH and PAH lead to an exciting possibility of unifying major key deep learning phenomena, including neural collapse and the neural feature ansatz, in a single framework.
On the Power of Decision Trees in Auto-Regressive Language Modeling
Sep 27, 2024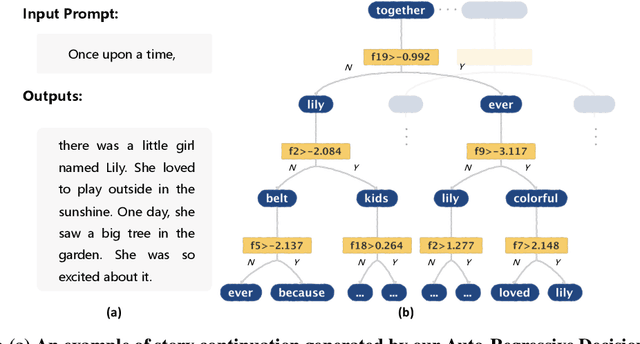
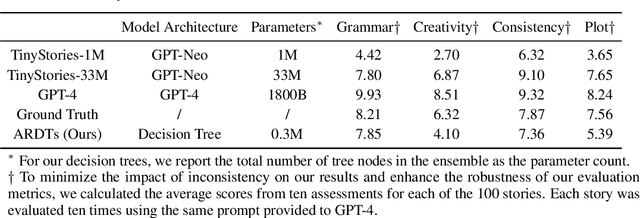
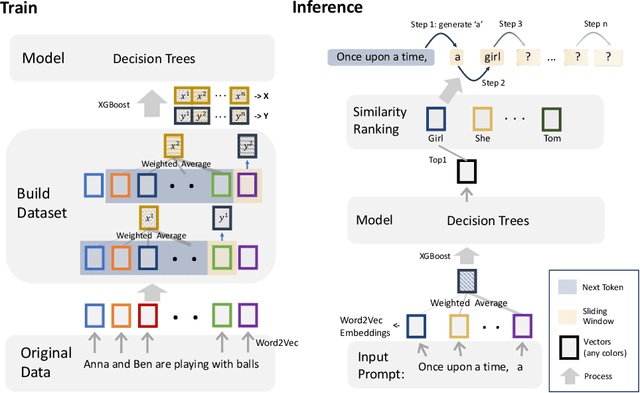
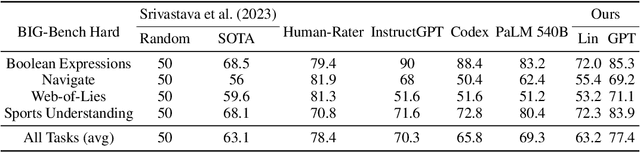
Originally proposed for handling time series data, Auto-regressive Decision Trees (ARDTs) have not yet been explored for language modeling. This paper delves into both the theoretical and practical applications of ARDTs in this new context. We theoretically demonstrate that ARDTs can compute complex functions, such as simulating automata, Turing machines, and sparse circuits, by leveraging "chain-of-thought" computations. Our analysis provides bounds on the size, depth, and computational efficiency of ARDTs, highlighting their surprising computational power. Empirically, we train ARDTs on simple language generation tasks, showing that they can learn to generate coherent and grammatically correct text on par with a smaller Transformer model. Additionally, we show that ARDTs can be used on top of transformer representations to solve complex reasoning tasks. This research reveals the unique computational abilities of ARDTs, aiming to broaden the architectural diversity in language model development.