 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Explicit Scheme for Pathwise XVA Computations
Jan 24, 2024Motivated by the equations of cross valuation adjustments (XVAs) in the realistic case where capital is deemed fungible as a source of funding for variation margin, we introduce a simulation/regression scheme for a class of anticipated BSDEs, where the coefficient entails a conditional expected shortfall of the martingale part of the solution. The scheme is explicit in time and uses neural network least-squares and quantile regressions for the embedded conditional expectations and expected shortfall computations. An a posteriori Monte Carlo validation procedure allows assessing the regression error of the scheme at each time step. The superiority of this scheme with respect to Picard iterations is illustrated in a high-dimensional and hybrid market/default risks XVA use-case.
The Probabilistic Stability of Stochastic Gradient Descent
Mar 23, 2023

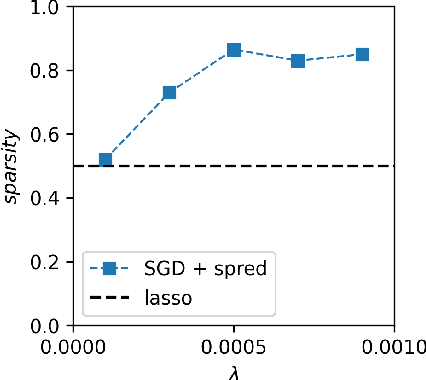

A fundamental open problem in deep learning theory is how to define and understand the stability of stochastic gradient descent (SGD) close to a fixed point. Conventional literature relies on the convergence of statistical moments, esp., the variance, of the parameters to quantify the stability. We revisit the definition of stability for SGD and use the \textit{convergence in probability} condition to define the \textit{probabilistic stability} of SGD. The proposed stability directly answers a fundamental question in deep learning theory: how SGD selects a meaningful solution for a neural network from an enormous number of solutions that may overfit badly. To achieve this, we show that only under the lens of probabilistic stability does SGD exhibit rich and practically relevant phases of learning, such as the phases of the complete loss of stability, incorrect learning, convergence to low-rank saddles, and correct learning. When applied to a neural network, these phase diagrams imply that SGD prefers low-rank saddles when the underlying gradient is noisy, thereby improving the learning performance. This result is in sharp contrast to the conventional wisdom that SGD prefers flatter minima to sharp ones, which we find insufficient to explain the experimental data. We also prove that the probabilistic stability of SGD can be quantified by the Lyapunov exponents of the SGD dynamics, which can easily be measured in practice. Our work potentially opens a new venue for addressing the fundamental question of how the learning algorithm affects the learning outcome in deep learning.
Exact Solutions of a Deep Linear Network
Feb 14, 2022
This work finds the exact solutions to a deep linear network with weight decay and stochastic neurons, a fundamental model for understanding the landscape of neural networks. Our result implies that weight decay strongly interacts with the model architecture and can create bad minima in a network with more than $1$ hidden layer, qualitatively different for a network with only $1$ hidden layer. As an application, we also analyze stochastic nets and show that their prediction variance vanishes to zero as the stochasticity, the width, or the depth tends to infinity.
SGD May Never Escape Saddle Points
Jul 25, 2021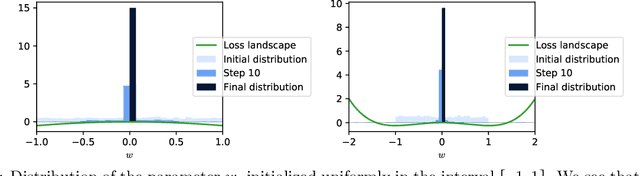
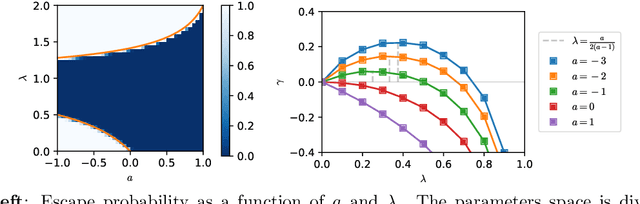


Stochastic gradient descent (SGD) has been deployed to solve highly non-linear and non-convex machine learning problems such as the training of deep neural networks. However, previous works on SGD often rely on highly restrictive and unrealistic assumptions about the nature of noise in SGD. In this work, we mathematically construct examples that defy previous understandings of SGD. For example, our constructions show that: (1) SGD may converge to a local maximum; (2) SGD may escape a saddle point arbitrarily slowly; (3) SGD may prefer sharp minima over the flat ones; and (4) AMSGrad may converge to a local maximum. Our result suggests that the noise structure of SGD might be more important than the loss landscape in neural network training and that future research should focus on deriving the actual noise structure in deep learning.