 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster-Level Attention-Guided Parallel Decoding for Masked Diffusion Language Models
May 28, 2026Masked diffusion language models (MDLMs) enable parallel decoding by predicting all masked positions at each denoising step, yet existing training-free samplers usually decide which positions to commit at token-level granularity. We revisit this granularity and observe that reliable predictions often emerge as contiguous high-confidence spans, suggesting that the unit of parallel commitment can be larger than a single token. We first group adjacent high-confidence candidates into confidence-induced clusters (CICs) as span-level update units. We then use self-attention maps from the same forward pass to estimate inter-cluster dependencies, enabling conflict-aware selection of mutually compatible CICs for parallel commitment. This yields CLAD (Cluster-Level Attention-Guided Decoding), a training-free cluster-level decoder for MDLMs. Experiments on LLaDA and Dream model families across four reasoning and code-generation benchmarks show that CLAD achieves 1.77x--8.47x speedups over Vanilla decoding while maintaining broadly comparable task accuracy in most settings.
Visual-Redundancy-Controlled Parallel Decoding for Diffusion-Based Multimodal Large Language Models
May 25, 2026Diffusion-based multimodal large language models (dMLLMs) decode by iteratively predicting tokens at multiple masked positions in parallel. This turns each decoding step into a position-selection problem: the model must choose not only which predictions are reliable in isolation, but also which positions should be committed together as context for later decoding steps. Existing confidence-based decoding ranks masked positions independently and commits the top-K positions, largely ignoring whether the committed tokens provide complementary visual grounding. We identify a step-level limitation of this strategy in multimodal settings: high-confidence tokens selected in the same step can rely on overlapping visual grounding, introducing visual redundancy among the committed tokens and leaving less complementary visual grounding available for later decoding. To quantify this effect, we introduce the Visual Redundancy Index (VRI), which measures visual grounding overlap among tokens committed in parallel. To control this redundancy during decoding, we propose Visual-Redundancy-Controlled Decoding (VRCD), a training-free inference-time decoding method that uses token-to-image attention to prioritize visually complementary positions. Across diverse multimodal benchmarks, VRCD reduces visual redundancy and remaining-position entropy with modest runtime overhead. In longer decoding experiments, it also achieves relative accuracy gains of up to 18.8% on M^3CoT and 6.9% on MMBench over confidence-based decoding. Code will be released at https://github.com/infiniteYuanyl/VRCD.
Multi-Agent Conditional Diffusion Model with Mean Field Communication as Wireless Resource Allocation Planner
Oct 27, 2025In wireless communication systems, efficient and adaptive resource allocation plays a crucial role in enhancing overall Quality of Service (QoS). While centralized Multi-Agent Reinforcement Learning (MARL) frameworks rely on a central coordinator for policy training and resource scheduling, they suffer from scalability issues and privacy risks. In contrast, the Distributed Training with Decentralized Execution (DTDE) paradigm enables distributed learning and decision-making, but it struggles with non-stationarity and limited inter-agent cooperation, which can severely degrade system performance. To overcome these challenges, we propose the Multi-Agent Conditional Diffusion Model Planner (MA-CDMP) for decentralized communication resource management. Built upon the Model-Based Reinforcement Learning (MBRL) paradigm, MA-CDMP employs Diffusion Models (DMs) to capture environment dynamics and plan future trajectories, while an inverse dynamics model guides action generation, thereby alleviating the sample inefficiency and slow convergence of conventional DTDE methods. Moreover, to approximate large-scale agent interactions, a Mean-Field (MF) mechanism is introduced as an assistance to the classifier in DMs. This design mitigates inter-agent non-stationarity and enhances cooperation with minimal communication overhead in distributed settings. We further theoretically establish an upper bound on the distributional approximation error introduced by the MF-based diffusion generation, guaranteeing convergence stability and reliable modeling of multi-agent stochastic dynamics. Extensive experiments demonstrate that MA-CDMP consistently outperforms existing MARL baselines in terms of average reward and QoS metrics, showcasing its scalability and practicality for real-world wireless network optimization.
UST-SSM: Unified Spatio-Temporal State Space Models for Point Cloud Video Modeling
Aug 20, 2025


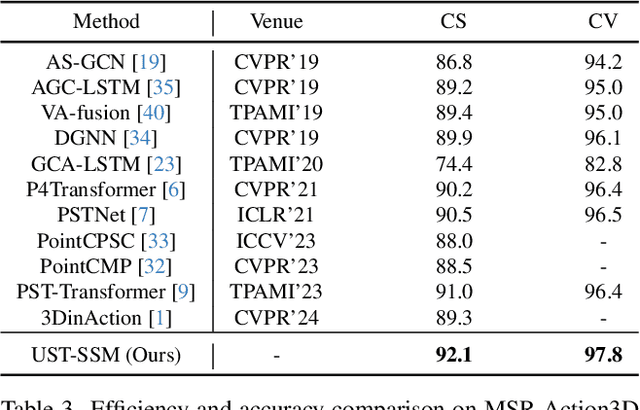
Point cloud videos capture dynamic 3D motion while reducing the effects of lighting and viewpoint variations, making them highly effective for recognizing subtle and continuous human actions. Although Selective State Space Models (SSMs) have shown good performance in sequence modeling with linear complexity, the spatio-temporal disorder of point cloud videos hinders their unidirectional modeling when directly unfolding the point cloud video into a 1D sequence through temporally sequential scanning. To address this challenge, we propose the Unified Spatio-Temporal State Space Model (UST-SSM), which extends the latest advancements in SSMs to point cloud videos. Specifically, we introduce Spatial-Temporal Selection Scanning (STSS), which reorganizes unordered points into semantic-aware sequences through prompt-guided clustering, thereby enabling the effective utilization of points that are spatially and temporally distant yet similar within the sequence. For missing 4D geometric and motion details, Spatio-Temporal Structure Aggregation (STSA) aggregates spatio-temporal features and compensates. To improve temporal interaction within the sampled sequence, Temporal Interaction Sampling (TIS) enhances fine-grained temporal dependencies through non-anchor frame utilization and expanded receptive fields. Experimental results on the MSR-Action3D, NTU RGB+D, and Synthia 4D datasets validate the effectiveness of our method. Our code is available at https://github.com/wangzy01/UST-SSM.
SCSA: A Plug-and-Play Semantic Continuous-Sparse Attention for Arbitrary Semantic Style Transfer
Mar 06, 2025Attention-based arbitrary style transfer methods, including CNN-based, Transformer-based, and Diffusion-based, have flourished and produced high-quality stylized images. However, they perform poorly on the content and style images with the same semantics, i.e., the style of the corresponding semantic region of the generated stylized image is inconsistent with that of the style image. We argue that the root cause lies in their failure to consider the relationship between local regions and semantic regions. To address this issue, we propose a plug-and-play semantic continuous-sparse attention, dubbed SCSA, for arbitrary semantic style transfer -- each query point considers certain key points in the corresponding semantic region. Specifically, semantic continuous attention ensures each query point fully attends to all the continuous key points in the same semantic region that reflect the overall style characteristics of that region; Semantic sparse attention allows each query point to focus on the most similar sparse key point in the same semantic region that exhibits the specific stylistic texture of that region. By combining the two modules, the resulting SCSA aligns the overall style of the corresponding semantic regions while transferring the vivid textures of these regions. Qualitative and quantitative results prove that SCSA enables attention-based arbitrary style transfer methods to produce high-quality semantic stylized images.
Improving Decoupled Posterior Sampling for Inverse Problems using Data Consistency Constraint
Dec 01, 2024



Diffusion models have shown strong performances in solving inverse problems through posterior sampling while they suffer from errors during earlier steps. To mitigate this issue, several Decoupled Posterior Sampling methods have been recently proposed. However, the reverse process in these methods ignores measurement information, leading to errors that impede effective optimization in subsequent steps. To solve this problem, we propose Guided Decoupled Posterior Sampling (GDPS) by integrating a data consistency constraint in the reverse process. The constraint performs a smoother transition within the optimization process, facilitating a more effective convergence toward the target distribution. Furthermore, we extend our method to latent diffusion models and Tweedie's formula, demonstrating its scalability. We evaluate GDPS on the FFHQ and ImageNet datasets across various linear and nonlinear tasks under both standard and challenging conditions. Experimental results demonstrate that GDPS achieves state-of-the-art performance, improving accuracy over existing methods.
Average case analysis of Lasso under ultra-sparse conditions
Feb 25, 2023

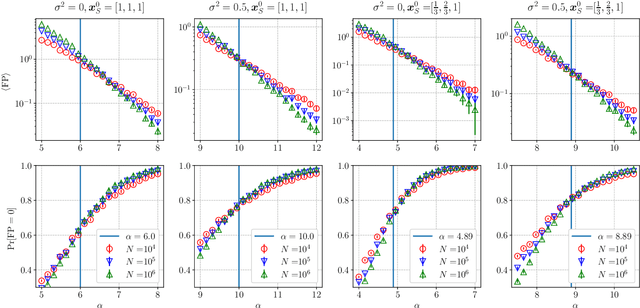

We analyze the performance of the least absolute shrinkage and selection operator (Lasso) for the linear model when the number of regressors $N$ grows larger keeping the true support size $d$ finite, i.e., the ultra-sparse case. The result is based on a novel treatment of the non-rigorous replica method in statistical physics, which has been applied only to problem settings where $N$ ,$d$ and the number of observations $M$ tend to infinity at the same rate. Our analysis makes it possible to assess the average performance of Lasso with Gaussian sensing matrices without assumptions on the scaling of $N$ and $M$, the noise distribution, and the profile of the true signal. Under mild conditions on the noise distribution, the analysis also offers a lower bound on the sample complexity necessary for partial and perfect support recovery when $M$ diverges as $M = O(\log N)$. The obtained bound for perfect support recovery is a generalization of that given in previous literature, which only considers the case of Gaussian noise and diverging $d$. Extensive numerical experiments strongly support our analysis.
QCM-SGM+: Improved Quantized Compressed Sensing With Score-Based Generative Models for General Sensing Matrices
Feb 02, 2023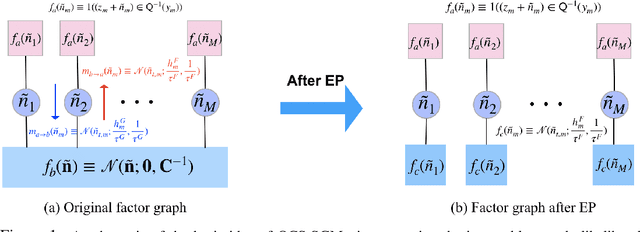



In realistic compressed sensing (CS) scenarios, the obtained measurements usually have to be quantized to a finite number of bits before transmission and/or storage, thus posing a challenge in recovery, especially for extremely coarse quantization such as 1-bit sign measurements. Recently Meng & Kabashima proposed an efficient quantized compressed sensing algorithm called QCS-SGM using the score-based generative models as an implicit prior. Thanks to the power of score-based generative models in capturing the rich structure of the prior, QCS-SGM achieves remarkably better performances than previous quantized CS methods. However, QCS-SGM is restricted to (approximately) row-orthogonal sensing matrices since otherwise the likelihood score becomes intractable. To address this challenging problem, in this paper we propose an improved version of QCS-SGM, which we call QCS-SGM+, which also works well for general matrices. The key idea is a Bayesian inference perspective of the likelihood score computation, whereby an expectation propagation algorithm is proposed to approximately compute the likelihood score. Experiments on a variety of baseline datasets demonstrate that the proposed QCS-SGM+ outperforms QCS-SGM by a large margin when sensing matrices are far from row-orthogonal.
Diffusion Model Based Posterior Sampling for Noisy Linear Inverse Problems
Nov 20, 2022

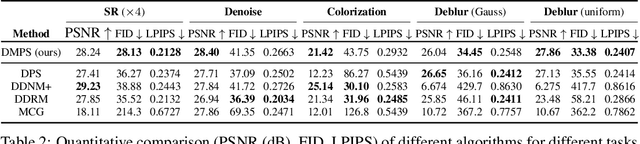

We consider the ubiquitous linear inverse problems with additive Gaussian noise and propose an unsupervised general-purpose sampling approach called diffusion model based posterior sampling (DMPS) to reconstruct the unknown signal from noisy linear measurements. Specifically, the prior of the unknown signal is implicitly modeled by one pre-trained diffusion model (DM). In posterior sampling, to address the intractability of exact noise-perturbed likelihood score, a simple yet effective noise-perturbed pseudo-likelihood score is introduced under the uninformative prior assumption. While DMPS applies to any kind of DM with proper modifications, we focus on the ablated diffusion model (ADM) as one specific example and evaluate its efficacy on a variety of linear inverse problems such as image super-resolution, denoising, deblurring, colorization. Experimental results demonstrate that, for both in-distribution and out-of-distribution samples, DMPS achieves highly competitive or even better performances on various tasks while being 3 times faster than the leading competitor. The code to reproduce the results is available at https://github.com/mengxiangming/dmps.
A Unitary Transform Based Generalized Approximate Message Passing
Oct 17, 2022


We consider the problem of recovering an unknown signal ${\mathbf x}\in {\mathbb R}^n$ from general nonlinear measurements obtained through a generalized linear model (GLM), i.e., ${\mathbf y}= f\left({\mathbf A}{\mathbf x}+{\mathbf w}\right)$, where $f(\cdot)$ is a componentwise nonlinear function. Based on the unitary transform approximate message passing (UAMP) and expectation propagation, a unitary transform based generalized approximate message passing (GUAMP) algorithm is proposed for general measurement matrices $\bf{A}$, in particular highly correlated matrices. Experimental results on quantized compressed sensing demonstrate that the proposed GUAMP significantly outperforms state-of-the-art GAMP and GVAMP under correlated matrices $\bf{A}$.