 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpanding-and-Shrinking Binary Neural Networks
Mar 31, 2025While binary neural networks (BNNs) offer significant benefits in terms of speed, memory and energy, they encounter substantial accuracy degradation in challenging tasks compared to their real-valued counterparts. Due to the binarization of weights and activations, the possible values of each entry in the feature maps generated by BNNs are strongly constrained. To tackle this limitation, we propose the expanding-and-shrinking operation, which enhances binary feature maps with negligible increase of computation complexity, thereby strengthening the representation capacity. Extensive experiments conducted on multiple benchmarks reveal that our approach generalizes well across diverse applications ranging from image classification, object detection to generative diffusion model, while also achieving remarkable improvement over various leading binarization algorithms based on different architectures including both CNNs and Transformers.
Improving Decoupled Posterior Sampling for Inverse Problems using Data Consistency Constraint
Dec 01, 2024



Diffusion models have shown strong performances in solving inverse problems through posterior sampling while they suffer from errors during earlier steps. To mitigate this issue, several Decoupled Posterior Sampling methods have been recently proposed. However, the reverse process in these methods ignores measurement information, leading to errors that impede effective optimization in subsequent steps. To solve this problem, we propose Guided Decoupled Posterior Sampling (GDPS) by integrating a data consistency constraint in the reverse process. The constraint performs a smoother transition within the optimization process, facilitating a more effective convergence toward the target distribution. Furthermore, we extend our method to latent diffusion models and Tweedie's formula, demonstrating its scalability. We evaluate GDPS on the FFHQ and ImageNet datasets across various linear and nonlinear tasks under both standard and challenging conditions. Experimental results demonstrate that GDPS achieves state-of-the-art performance, improving accuracy over existing methods.
RepBNN: towards a precise Binary Neural Network with Enhanced Feature Map via Repeating
Jul 19, 2022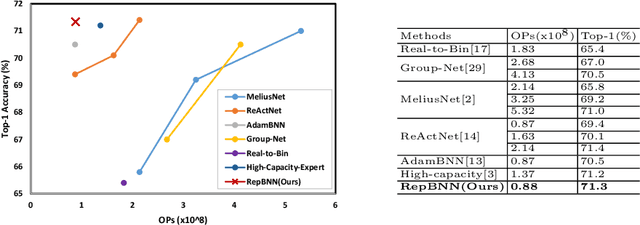

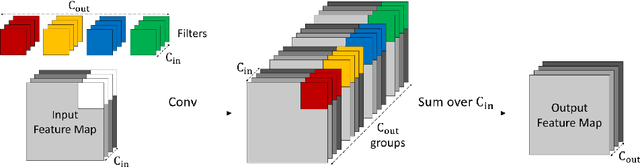

Binary neural network (BNN) is an extreme quantization version of convolutional neural networks (CNNs) with all features and weights mapped to just 1-bit. Although BNN saves a lot of memory and computation demand to make CNN applicable on edge or mobile devices, BNN suffers the drop of network performance due to the reduced representation capability after binarization. In this paper, we propose a new replaceable and easy-to-use convolution module RepConv, which enhances feature maps through replicating input or output along channel dimension by $\beta$ times without extra cost on the number of parameters and convolutional computation. We also define a set of RepTran rules to use RepConv throughout BNN modules like binary convolution, fully connected layer and batch normalization. Experiments demonstrate that after the RepTran transformation, a set of highly cited BNNs have achieved universally better performance than the original BNN versions. For example, the Top-1 accuracy of Rep-ReCU-ResNet-20, i.e., a RepBconv enhanced ReCU-ResNet-20, reaches 88.97% on CIFAR-10, which is 1.47% higher than that of the original network. And Rep-AdamBNN-ReActNet-A achieves 71.342% Top-1 accuracy on ImageNet, a fresh state-of-the-art result of BNNs. Code and models are available at:https://github.com/imfinethanks/Rep_AdamBNN.
LPC-AD: Fast and Accurate Multivariate Time Series Anomaly Detection via Latent Predictive Coding
May 05, 2022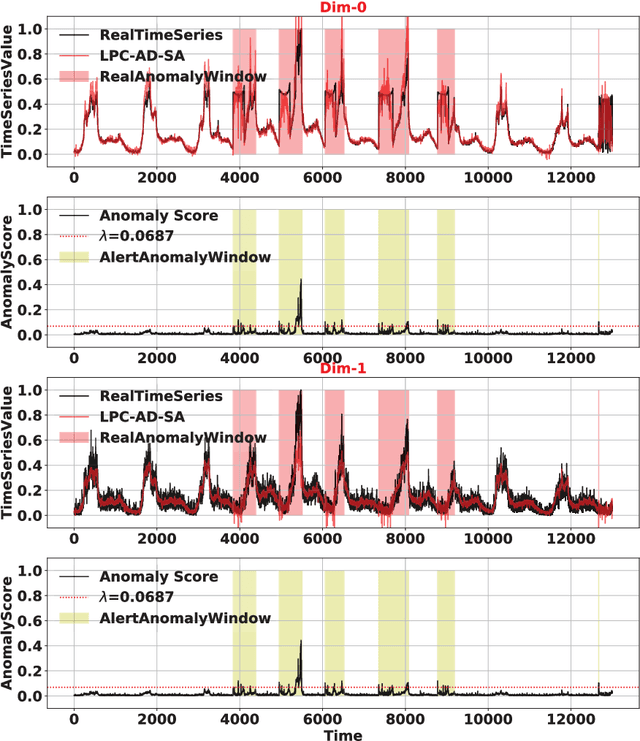
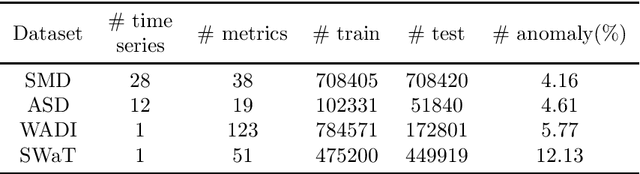
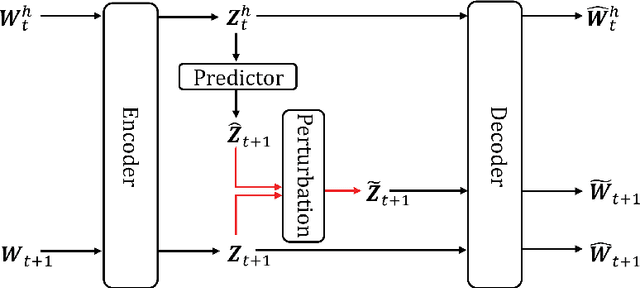
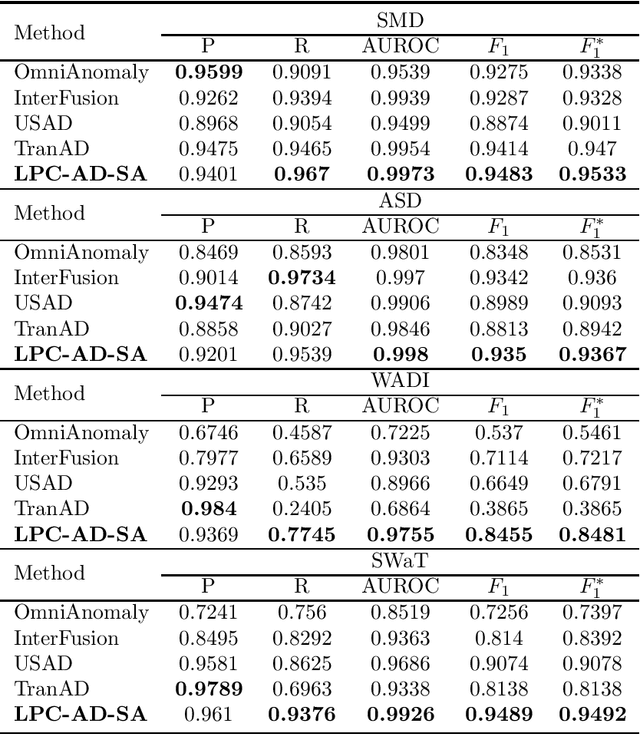
This paper proposes LPC-AD, a fast and accurate multivariate time series (MTS) anomaly detection method. LPC-AD is motivated by the ever-increasing needs for fast and accurate MTS anomaly detection methods to support fast troubleshooting in cloud computing, micro-service systems, etc. LPC-AD is fast in the sense that its reduces the training time by as high as 38.2% compared to the state-of-the-art (SOTA) deep learning methods that focus on training speed. LPC-AD is accurate in the sense that it improves the detection accuracy by as high as 18.9% compared to SOTA sophisticated deep learning methods that focus on enhancing detection accuracy. Methodologically, LPC-AD contributes a generic architecture LPC-Reconstruct for one to attain different trade-offs between training speed and detection accuracy. More specifically, LPC-Reconstruct is built on ideas from autoencoder for reducing redundancy in time series, latent predictive coding for capturing temporal dependence in MTS, and randomized perturbation for avoiding overfitting of anomalous dependence in the training data. We present simple instantiations of LPC-Reconstruct to attain fast training speed, where we propose a simple randomized perturbation method. The superior performance of LPC-AD over SOTA methods is validated by extensive experiments on four large real-world datasets. Experiment results also show the necessity and benefit of each component of the LPC-Reconstruct architecture and that LPC-AD is robust to hyper parameters.
Arrhythmia Classifier Using Convolutional Neural Network with Adaptive Loss-aware Multi-bit Networks Quantization
Feb 27, 2022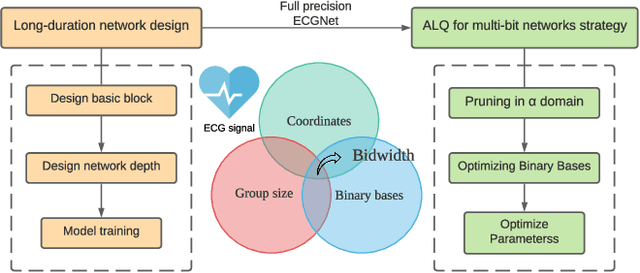
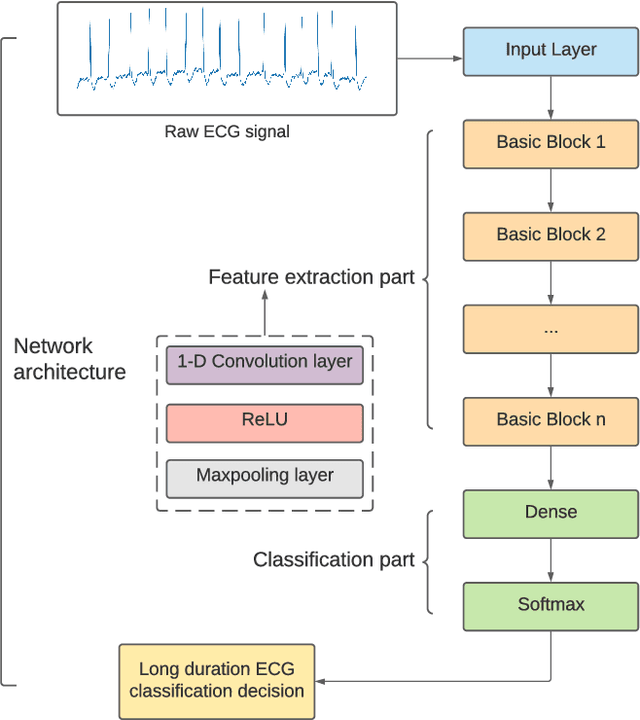


Cardiovascular disease (CVDs) is one of the universal deadly diseases, and the detection of it in the early stage is a challenging task to tackle. Recently, deep learning and convolutional neural networks have been employed widely for the classification of objects. Moreover, it is promising that lots of networks can be deployed on wearable devices. An increasing number of methods can be used to realize ECG signal classification for the sake of arrhythmia detection. However, the existing neural networks proposed for arrhythmia detection are not hardware-friendly enough due to a remarkable quantity of parameters resulting in memory and power consumption. In this paper, we present a 1-D adaptive loss-aware quantization, achieving a high compression rate that reduces memory consumption by 23.36 times. In order to adapt to our compression method, we need a smaller and simpler network. We propose a 17 layer end-to-end neural network classifier to classify 17 different rhythm classes trained on the MIT-BIH dataset, realizing a classification accuracy of 93.5%, which is higher than most existing methods. Due to the adaptive bitwidth method making important layers get more attention and offered a chance to prune useless parameters, the proposed quantization method avoids accuracy degradation. It even improves the accuracy rate, which is 95.84%, 2.34% higher than before. Our study achieves a 1-D convolutional neural network with high performance and low resources consumption, which is hardware-friendly and illustrates the possibility of deployment on wearable devices to realize a real-time arrhythmia diagnosis.