 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Specific Task Similarity for Vision Language Model Selection via Layer Conductance
Feb 01, 2026While open sourced Vision-Language Models (VLMs) have proliferated, selecting the optimal pretrained model for a specific downstream task remains challenging. Exhaustive evaluation is often infeasible due to computational constraints and data limitations in few shot scenarios. Existing selection methods fail to fully address this: they either rely on data-intensive proxies or use symmetric textual descriptors that neglect the inherently directional and model-specific nature of transferability. To address this problem, we propose a framework that grounds model selection in the internal functional dynamics of the visual encoder. Our approach represents each task via layer wise conductance and derives a target-conditioned block importance distribution through entropy regularized alignment. Building on this, we introduce Directional Conductance Divergence (DCD), an asymmetric metric that quantifies how effectively a source task covers the target's salient functional blocks. This allows for predicting target model rankings by aggregating source task ranks without direct inference. Experimental results on 48 VLMs across 21 datasets demonstrate that our method outperforms state-of-the-art baselines, achieving a 14.7% improvement in NDCG@5 over SWAB.
Demystifying Design Choices of Reinforcement Fine-tuning: A Batched Contextual Bandit Learning Perspective
Jan 30, 2026The reinforcement fine-tuning area is undergoing an explosion papers largely on optimizing design choices. Though performance gains are often claimed, inconsistent conclusions also arise from time to time, making the progress illusive. Reflecting on this illusion, we still lack principled answers to two fundamental questions: 1) what is the role of each design choice? 2) which ones are critical? This paper aims to shed light on them. The underlying challenge is that design choices are entangled together, making their contribution to learning and generalization difficult to attribute. To address this challenge, we first construct a minimalist baseline for disentangling factors: one rollout per query in each round, the outcome reward serving as the training signal without any advantage trick, and a batch size of thirty-two. This baseline connects to batched contextual bandit learning, which facilitates experimental analysis. Centering around this baseline, we design an experiment pipeline, examining the marginal gains of factors like advantage, number of rollouts, etc. Experiments on three base models and two datasets, not only reveal new understanding on the role of various design choices on learning and generalization dynamics, but also identify critical ones that deserve more effort.
Rethinking Reinforcement fine-tuning of LLMs: A Multi-armed Bandit Learning Perspective
Jan 21, 2026A large number of heuristics have been proposed to optimize the reinforcement fine-tuning of LLMs. However, inconsistent claims are made from time to time, making this area elusive. Reflecting on this situation, two fundamental questions still lack a clear understanding: 1) what is the role of each optimizing choice? 2) which ones are the bottlenecks? This paper aims to shed light on them, and it faces the challenge of several entangled confounding factors in the fine-tuning process. To tackle this challenge, we propose a bottom-up experiment pipeline. The bottom layer is composed of a minimalist configuration: one training data, one rollout per round and the reward directly serve as the learning signal without advantage function design. This minimalist configuration connects to multi-armed bandit learning with extremely large discrete action space, which offers theories to corroborate the experiment findings. The up procedure of the experiment pipeline expanding the minimalist configuration layer by layer, examining the role of each design choice. Experimental results on three LLMs and two reasoning datasets not only reveal new understanding of the design choice but also yield essential insights to shape the area.
LLM Cache Bandit Revisited: Addressing Query Heterogeneity for Cost-Effective LLM Inference
Sep 19, 2025This paper revisits the LLM cache bandit problem, with a special focus on addressing the query heterogeneity for cost-effective LLM inference. Previous works often assume uniform query sizes. Heterogeneous query sizes introduce a combinatorial structure for cache selection, making the cache replacement process more computationally and statistically challenging. We treat optimal cache selection as a knapsack problem and employ an accumulation-based strategy to effectively balance computational overhead and cache updates. In theoretical analysis, we prove that the regret of our algorithm achieves an $O(\sqrt{MNT})$ bound, improving the coefficient of $\sqrt{MN}$ compared to the $O(MN\sqrt{T})$ result in Berkeley, where $N$ is the total number of queries and $M$ is the cache size. Additionally, we also provide a problem-dependent bound, which was absent in previous works. The experiment rely on real-world data show that our algorithm reduces the total cost by approximately 12\%.
Advancing and Benchmarking Personalized Tool Invocation for LLMs
May 07, 2025Tool invocation is a crucial mechanism for extending the capabilities of Large Language Models (LLMs) and has recently garnered significant attention. It enables LLMs to solve complex problems through tool calls while accessing up-to-date world knowledge. However, existing work primarily focuses on the fundamental ability of LLMs to invoke tools for problem-solving, without considering personalized constraints in tool invocation. In this work, we introduce the concept of Personalized Tool Invocation and define two key tasks: Tool Preference and Profile-dependent Query. Tool Preference addresses user preferences when selecting among functionally similar tools, while Profile-dependent Query considers cases where a user query lacks certain tool parameters, requiring the model to infer them from the user profile. To tackle these challenges, we propose PTool, a data synthesis framework designed for personalized tool invocation. Additionally, we construct \textbf{PTBench}, the first benchmark for evaluating personalized tool invocation. We then fine-tune various open-source models, demonstrating the effectiveness of our framework and providing valuable insights. Our benchmark is public at https://github.com/hyfshadow/PTBench.
CasualHDRSplat: Robust High Dynamic Range 3D Gaussian Splatting from Casually Captured Videos
Apr 24, 2025



Recently, photo-realistic novel view synthesis from multi-view images, such as neural radiance field (NeRF) and 3D Gaussian Splatting (3DGS), have garnered widespread attention due to their superior performance. However, most works rely on low dynamic range (LDR) images, which limits the capturing of richer scene details. Some prior works have focused on high dynamic range (HDR) scene reconstruction, typically require capturing of multi-view sharp images with different exposure times at fixed camera positions during exposure times, which is time-consuming and challenging in practice. For a more flexible data acquisition, we propose a one-stage method: \textbf{CasualHDRSplat} to easily and robustly reconstruct the 3D HDR scene from casually captured videos with auto-exposure enabled, even in the presence of severe motion blur and varying unknown exposure time. \textbf{CasualHDRSplat} contains a unified differentiable physical imaging model which first applies continuous-time trajectory constraint to imaging process so that we can jointly optimize exposure time, camera response function (CRF), camera poses, and sharp 3D HDR scene. Extensive experiments demonstrate that our approach outperforms existing methods in terms of robustness and rendering quality. Our source code will be available at https://github.com/WU-CVGL/CasualHDRSplat
General Time-series Model for Universal Knowledge Representation of Multivariate Time-Series data
Feb 05, 2025



Universal knowledge representation is a central problem for multivariate time series(MTS) foundation models and yet remains open. This paper investigates this problem from the first principle and it makes four folds of contributions. First, a new empirical finding is revealed: time series with different time granularities (or corresponding frequency resolutions) exhibit distinct joint distributions in the frequency domain. This implies a crucial aspect of learning universal knowledge, one that has been overlooked by previous studies. Second, a novel Fourier knowledge attention mechanism is proposed to enable learning time granularity-aware representations from both the temporal and frequency domains. Third, an autoregressive blank infilling pre-training framework is incorporated to time series analysis for the first time, leading to a generative tasks agnostic pre-training strategy. To this end, we develop the General Time-series Model (GTM), a unified MTS foundation model that addresses the limitation of contemporary time series models, which often require token, pre-training, or model-level customizations for downstream tasks adaption. Fourth, extensive experiments show that GTM outperforms state-of-the-art (SOTA) methods across all generative tasks, including long-term forecasting, anomaly detection, and imputation.
Tortho-Gaussian: Splatting True Digital Orthophoto Maps
Nov 29, 2024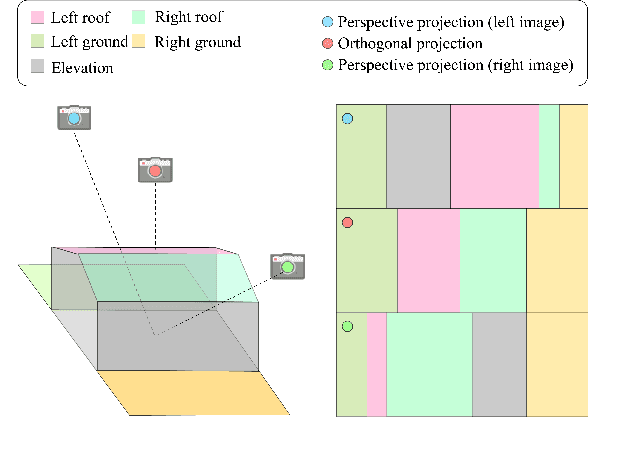

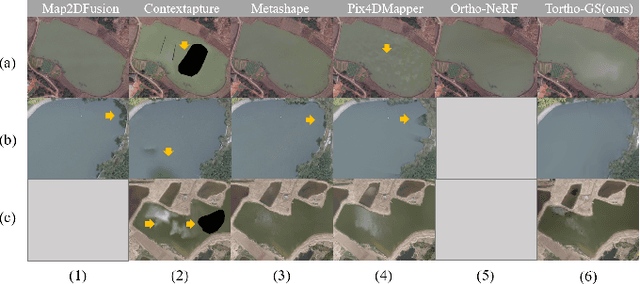

True Digital Orthophoto Maps (TDOMs) are essential products for digital twins and Geographic Information Systems (GIS). Traditionally, TDOM generation involves a complex set of traditional photogrammetric process, which may deteriorate due to various challenges, including inaccurate Digital Surface Model (DSM), degenerated occlusion detections, and visual artifacts in weak texture regions and reflective surfaces, etc. To address these challenges, we introduce TOrtho-Gaussian, a novel method inspired by 3D Gaussian Splatting (3DGS) that generates TDOMs through orthogonal splatting of optimized anisotropic Gaussian kernel. More specifically, we first simplify the orthophoto generation by orthographically splatting the Gaussian kernels onto 2D image planes, formulating a geometrically elegant solution that avoids the need for explicit DSM and occlusion detection. Second, to produce TDOM of large-scale area, a divide-and-conquer strategy is adopted to optimize memory usage and time efficiency of training and rendering for 3DGS. Lastly, we design a fully anisotropic Gaussian kernel that adapts to the varying characteristics of different regions, particularly improving the rendering quality of reflective surfaces and slender structures. Extensive experimental evaluations demonstrate that our method outperforms existing commercial software in several aspects, including the accuracy of building boundaries, the visual quality of low-texture regions and building facades. These results underscore the potential of our approach for large-scale urban scene reconstruction, offering a robust alternative for enhancing TDOM quality and scalability.
Micro-Structures Graph-Based Point Cloud Registration for Balancing Efficiency and Accuracy
Oct 29, 2024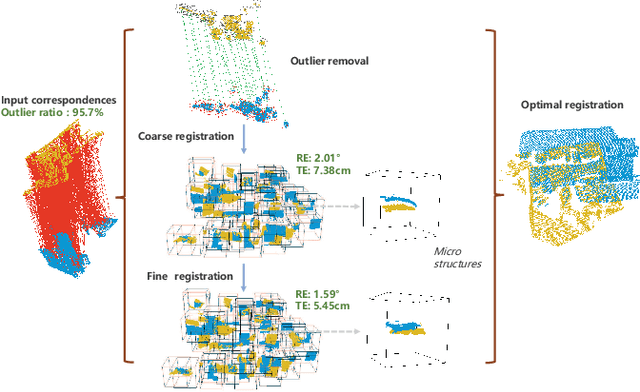
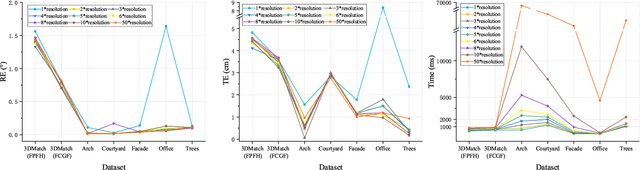
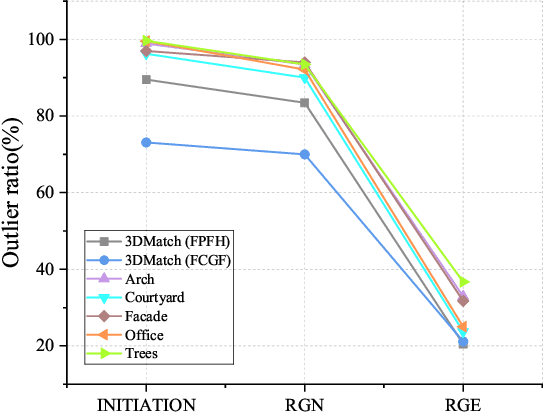
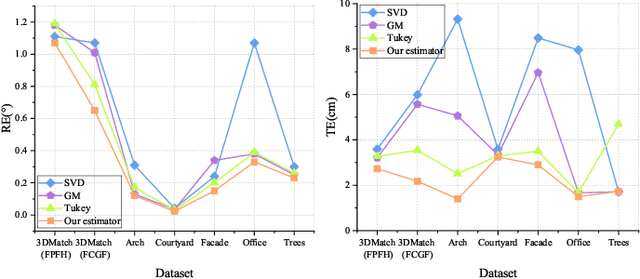
Point Cloud Registration (PCR) is a fundamental and significant issue in photogrammetry and remote sensing, aiming to seek the optimal rigid transformation between sets of points. Achieving efficient and precise PCR poses a considerable challenge. We propose a novel micro-structures graph-based global point cloud registration method. The overall method is comprised of two stages. 1) Coarse registration (CR): We develop a graph incorporating micro-structures, employing an efficient graph-based hierarchical strategy to remove outliers for obtaining the maximal consensus set. We propose a robust GNC-Welsch estimator for optimization derived from a robust estimator to the outlier process in the Lie algebra space, achieving fast and robust alignment. 2) Fine registration (FR): To refine local alignment further, we use the octree approach to adaptive search plane features in the micro-structures. By minimizing the distance from the point-to-plane, we can obtain a more precise local alignment, and the process will also be addressed effectively by being treated as a planar adjustment algorithm combined with Anderson accelerated optimization (PA-AA). After extensive experiments on real data, our proposed method performs well on the 3DMatch and ETH datasets compared to the most advanced methods, achieving higher accuracy metrics and reducing the time cost by at least one-third.
BFA-YOLO: Balanced multiscale object detection network for multi-view building facade attachments detection
Sep 06, 2024

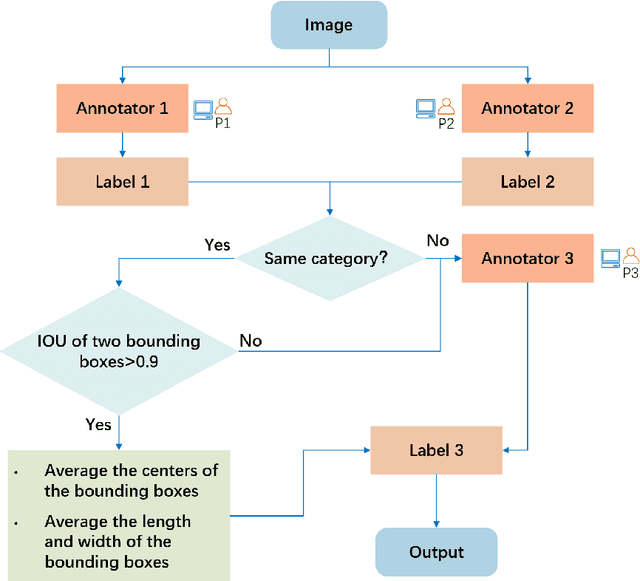

Detection of building facade attachments such as doors, windows, balconies, air conditioner units, billboards, and glass curtain walls plays a pivotal role in numerous applications. Building facade attachments detection aids in vbuilding information modeling (BIM) construction and meeting Level of Detail 3 (LOD3) standards. Yet, it faces challenges like uneven object distribution, small object detection difficulty, and background interference. To counter these, we propose BFA-YOLO, a model for detecting facade attachments in multi-view images. BFA-YOLO incorporates three novel innovations: the Feature Balanced Spindle Module (FBSM) for addressing uneven distribution, the Target Dynamic Alignment Task Detection Head (TDATH) aimed at improving small object detection, and the Position Memory Enhanced Self-Attention Mechanism (PMESA) to combat background interference, with each component specifically designed to solve its corresponding challenge. Detection efficacy of deep network models deeply depends on the dataset's characteristics. Existing open source datasets related to building facades are limited by their single perspective, small image pool, and incomplete category coverage. We propose a novel method for building facade attachments detection dataset construction and construct the BFA-3D dataset for facade attachments detection. The BFA-3D dataset features multi-view, accurate labels, diverse categories, and detailed classification. BFA-YOLO surpasses YOLOv8 by 1.8% and 2.9% in mAP@0.5 on the multi-view BFA-3D and street-view Facade-WHU datasets, respectively. These results underscore BFA-YOLO's superior performance in detecting facade attachments.