 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Reasoning Patterns in the Generalization Discrepancy of Long Chain-of-Thought Supervised Fine-Tuning
Apr 02, 2026Supervised Fine-Tuning (SFT) on long Chain-of-Thought (CoT) trajectories has become a pivotal phase in building large reasoning models. However, how CoT trajectories from different sources influence the generalization performance of models remains an open question. In this paper, we conduct a comparative study using two sources of verified CoT trajectories generated by two competing models, \texttt{DeepSeek-R1-0528} and \texttt{gpt-oss-120b}, with their problem sets controlled to be identical. Despite their comparable performance, we uncover a striking paradox: lower training loss does not translate to better generalization. SFT on \texttt{DeepSeek-R1-0528} data achieves remarkably lower training loss, yet exhibits significantly worse generalization performance on reasoning benchmarks compared to those trained on \texttt{gpt-oss-120b}. To understand this paradox, we perform a multi-faceted analysis probing token-level SFT loss and step-level reasoning behaviors. Our analysis reveals a difference in reasoning patterns. \texttt{gpt-oss-120b} exhibits highly convergent and deductive trajectories, whereas \texttt{DeepSeek-R1-0528} favors a divergent and branch-heavy exploration pattern. Consequently, models trained with \texttt{DeepSeek-R1} data inherit inefficient exploration behaviors, often getting trapped in redundant exploratory branches that hinder them from reaching correct solutions. Building upon this insight, we propose a simple yet effective remedy of filtering out frequently branching trajectories to improve the generalization of SFT. Experiments show that training on selected \texttt{DeepSeek-R1-0528} subsets surprisingly improves reasoning performance by up to 5.1% on AIME25, 5.5% on BeyondAIME, and on average 3.6% on five benchmarks.
BiT-MCTS: A Theme-based Bidirectional MCTS Approach to Chinese Fiction Generation
Mar 15, 2026Generating long-form linear fiction from open-ended themes remains a major challenge for large language models, which frequently fail to guarantee global structure and narrative diversity when using premise-based or linear outlining approaches. We present BiT-MCTS, a theme-driven framework that operationalizes a "climax-first, bidirectional expansion" strategy motivated by Freytag's Pyramid. Given a theme, our method extracts a core dramatic conflict and generates an explicit climax, then employs a bidirectional Monte Carlo Tree Search (MCTS) to expand the plot backward (rising action, exposition) and forward (falling action, resolution) to produce a structured outline. A final generation stage realizes a complete narrative from the refined outline. We construct a Chinese theme corpus for evaluation and conduct extensive experiments across three contemporary LLM backbones. Results show that BiT-MCTS improves narrative coherence, plot structure, and thematic depth relative to strong baselines, while enabling substantially longer, more coherent stories according to automatic metrics and human judgments.
Pushing the Frontier of Black-Box LVLM Attacks via Fine-Grained Detail Targeting
Feb 19, 2026Black-box adversarial attacks on Large Vision-Language Models (LVLMs) are challenging due to missing gradients and complex multimodal boundaries. While prior state-of-the-art transfer-based approaches like M-Attack perform well using local crop-level matching between source and target images, we find this induces high-variance, nearly orthogonal gradients across iterations, violating coherent local alignment and destabilizing optimization. We attribute this to (i) ViT translation sensitivity that yields spike-like gradients and (ii) structural asymmetry between source and target crops. We reformulate local matching as an asymmetric expectation over source transformations and target semantics, and build a gradient-denoising upgrade to M-Attack. On the source side, Multi-Crop Alignment (MCA) averages gradients from multiple independently sampled local views per iteration to reduce variance. On the target side, Auxiliary Target Alignment (ATA) replaces aggressive target augmentation with a small auxiliary set from a semantically correlated distribution, producing a smoother, lower-variance target manifold. We further reinterpret momentum as Patch Momentum, replaying historical crop gradients; combined with a refined patch-size ensemble (PE+), this strengthens transferable directions. Together these modules form M-Attack-V2, a simple, modular enhancement over M-Attack that substantially improves transfer-based black-box attacks on frontier LVLMs: boosting success rates on Claude-4.0 from 8% to 30%, Gemini-2.5-Pro from 83% to 97%, and GPT-5 from 98% to 100%, outperforming prior black-box LVLM attacks. Code and data are publicly available at: https://github.com/vila-lab/M-Attack-V2.
Scaling Reasoning Hop Exposes Weaknesses: Demystifying and Improving Hop Generalization in Large Language Models
Jan 29, 2026Chain-of-thought (CoT) reasoning has become the standard paradigm for enabling Large Language Models (LLMs) to solve complex problems. However, recent studies reveal a sharp performance drop in reasoning hop generalization scenarios, where the required number of reasoning steps exceeds training distributions while the underlying algorithm remains unchanged. The internal mechanisms driving this failure remain poorly understood. In this work, we conduct a systematic study on tasks from multiple domains, and find that errors concentrate at token positions of a few critical error types, rather than being uniformly distributed. Closer inspection reveals that these token-level erroneous predictions stem from internal competition mechanisms: certain attention heads, termed erroneous processing heads (ep heads), tip the balance by amplifying incorrect reasoning trajectories while suppressing correct ones. Notably, removing individual ep heads during inference can often restore the correct predictions. Motivated by these insights, we propose test-time correction of reasoning, a lightweight intervention method that dynamically identifies and deactivates ep heads in the reasoning process. Extensive experiments across different tasks and LLMs show that it consistently improves reasoning hop generalization, highlighting both its effectiveness and potential.
Fine-Tuning Flow Matching via Maximum Likelihood Estimation of Reconstructions
Oct 02, 2025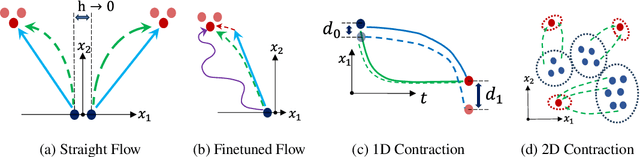
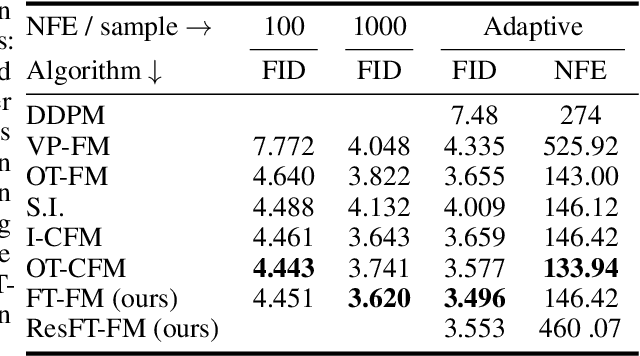
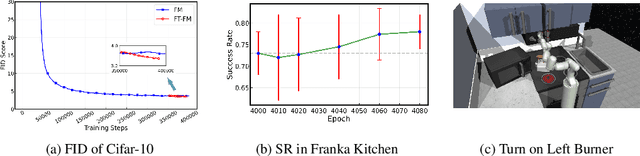

Flow Matching (FM) algorithm achieves remarkable results in generative tasks especially in robotic manipulation. Building upon the foundations of diffusion models, the simulation-free paradigm of FM enables simple and efficient training, but inherently introduces a train-inference gap. Specifically, we cannot assess the model's output during the training phase. In contrast, other generative models including Variational Autoencoder (VAE), Normalizing Flow and Generative Adversarial Networks (GANs) directly optimize on the reconstruction loss. Such a gap is particularly evident in scenarios that demand high precision, such as robotic manipulation. Moreover, we show that FM's over-pursuit of straight predefined paths may introduce some serious problems such as stiffness into the system. These motivate us to fine-tune FM via Maximum Likelihood Estimation of reconstructions - an approach made feasible by FM's underlying smooth ODE formulation, in contrast to the stochastic differential equations (SDEs) used in diffusion models. This paper first theoretically analyzes the relation between training loss and inference error in FM. Then we propose a method of fine-tuning FM via Maximum Likelihood Estimation of reconstructions, which includes both straightforward fine-tuning and residual-based fine-tuning approaches. Furthermore, through specifically designed architectures, the residual-based fine-tuning can incorporate the contraction property into the model, which is crucial for the model's robustness and interpretability. Experimental results in image generation and robotic manipulation verify that our method reliably improves the inference performance of FM.
Open CaptchaWorld: A Comprehensive Web-based Platform for Testing and Benchmarking Multimodal LLM Agents
May 30, 2025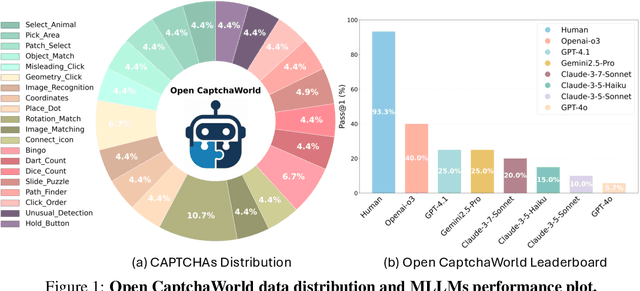
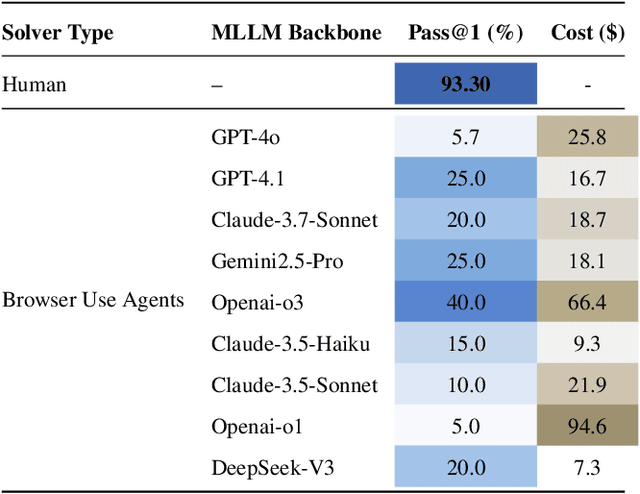

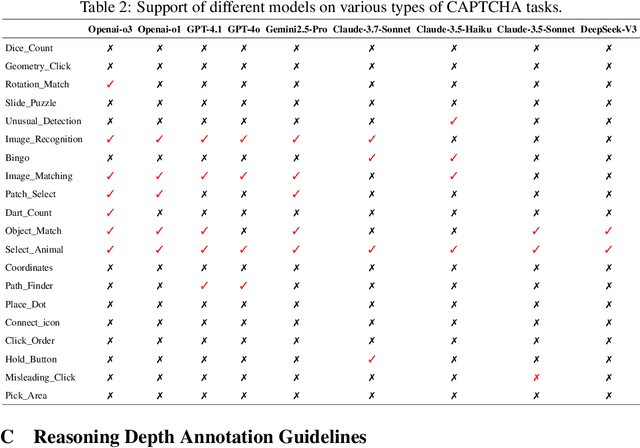
CAPTCHAs have been a critical bottleneck for deploying web agents in real-world applications, often blocking them from completing end-to-end automation tasks. While modern multimodal LLM agents have demonstrated impressive performance in static perception tasks, their ability to handle interactive, multi-step reasoning challenges like CAPTCHAs is largely untested. To address this gap, we introduce Open CaptchaWorld, the first web-based benchmark and platform specifically designed to evaluate the visual reasoning and interaction capabilities of MLLM-powered agents through diverse and dynamic CAPTCHA puzzles. Our benchmark spans 20 modern CAPTCHA types, totaling 225 CAPTCHAs, annotated with a new metric we propose: CAPTCHA Reasoning Depth, which quantifies the number of cognitive and motor steps required to solve each puzzle. Experimental results show that humans consistently achieve near-perfect scores, state-of-the-art MLLM agents struggle significantly, with success rates at most 40.0% by Browser-Use Openai-o3, far below human-level performance, 93.3%. This highlights Open CaptchaWorld as a vital benchmark for diagnosing the limits of current multimodal agents and guiding the development of more robust multimodal reasoning systems. Code and Data are available at this https URL.
What Makes a Good Reasoning Chain? Uncovering Structural Patterns in Long Chain-of-Thought Reasoning
May 28, 2025



Recent advances in reasoning with large language models (LLMs) have popularized Long Chain-of-Thought (LCoT), a strategy that encourages deliberate and step-by-step reasoning before producing a final answer. While LCoTs have enabled expert-level performance in complex tasks, how the internal structures of their reasoning chains drive, or even predict, the correctness of final answers remains a critical yet underexplored question. In this work, we present LCoT2Tree, an automated framework that converts sequential LCoTs into hierarchical tree structures and thus enables deeper structural analysis of LLM reasoning. Using graph neural networks (GNNs), we reveal that structural patterns extracted by LCoT2Tree, including exploration, backtracking, and verification, serve as stronger predictors of final performance across a wide range of tasks and models. Leveraging an explainability technique, we further identify critical thought patterns such as over-branching that account for failures. Beyond diagnostic insights, the structural patterns by LCoT2Tree support practical applications, including improving Best-of-N decoding effectiveness. Overall, our results underscore the critical role of internal structures of reasoning chains, positioning LCoT2Tree as a powerful tool for diagnosing, interpreting, and improving reasoning in LLMs.
A Frustratingly Simple Yet Highly Effective Attack Baseline: Over 90% Success Rate Against the Strong Black-box Models of GPT-4.5/4o/o1
Mar 13, 2025Despite promising performance on open-source large vision-language models (LVLMs), transfer-based targeted attacks often fail against black-box commercial LVLMs. Analyzing failed adversarial perturbations reveals that the learned perturbations typically originate from a uniform distribution and lack clear semantic details, resulting in unintended responses. This critical absence of semantic information leads commercial LVLMs to either ignore the perturbation entirely or misinterpret its embedded semantics, thereby causing the attack to fail. To overcome these issues, we notice that identifying core semantic objects is a key objective for models trained with various datasets and methodologies. This insight motivates our approach that refines semantic clarity by encoding explicit semantic details within local regions, thus ensuring interoperability and capturing finer-grained features, and by concentrating modifications on semantically rich areas rather than applying them uniformly. To achieve this, we propose a simple yet highly effective solution: at each optimization step, the adversarial image is cropped randomly by a controlled aspect ratio and scale, resized, and then aligned with the target image in the embedding space. Experimental results confirm our hypothesis. Our adversarial examples crafted with local-aggregated perturbations focused on crucial regions exhibit surprisingly good transferability to commercial LVLMs, including GPT-4.5, GPT-4o, Gemini-2.0-flash, Claude-3.5-sonnet, Claude-3.7-sonnet, and even reasoning models like o1, Claude-3.7-thinking and Gemini-2.0-flash-thinking. Our approach achieves success rates exceeding 90% on GPT-4.5, 4o, and o1, significantly outperforming all prior state-of-the-art attack methods. Our optimized adversarial examples under different configurations and training code are available at https://github.com/VILA-Lab/M-Attack.
Learning to Substitute Components for Compositional Generalization
Feb 28, 2025Despite the rising prevalence of neural language models, recent empirical evidence suggests their deficiency in compositional generalization. One of the current de-facto solutions to this problem is compositional data augmentation, which aims to introduce additional compositional inductive bias. However, existing handcrafted augmentation strategies offer limited improvement when systematic generalization of neural language models requires multi-grained compositional bias (i.e., not limited to either lexical or structural biases alone) or when training sentences have an imbalanced difficulty distribution. To address these challenges, we first propose a novel compositional augmentation strategy called Component Substitution (CompSub), which enables multi-grained composition of substantial substructures across the entire training set. Furthermore, we introduce the Learning Component Substitution (LCS) framework. This framework empowers the learning of component substitution probabilities in CompSub in an end-to-end manner by maximizing the loss of neural language models, thereby prioritizing challenging compositions with elusive concepts and novel contexts. We extend the key ideas of CompSub and LCS to the recently emerging in-context learning scenarios of pre-trained large language models (LLMs), proposing the LCS-ICL algorithm to enhance the few-shot compositional generalization of state-of-the-art (SOTA) LLMs. Theoretically, we provide insights into why applying our algorithms to language models can improve compositional generalization performance. Empirically, our results on four standard compositional generalization benchmarks(SCAN, COGS, GeoQuery, and COGS-QL) demonstrate the superiority of CompSub, LCS, and LCS-ICL, with improvements of up to 66.5%, 10.3%, 1.4%, and 8.8%, respectively.
General Time-series Model for Universal Knowledge Representation of Multivariate Time-Series data
Feb 05, 2025



Universal knowledge representation is a central problem for multivariate time series(MTS) foundation models and yet remains open. This paper investigates this problem from the first principle and it makes four folds of contributions. First, a new empirical finding is revealed: time series with different time granularities (or corresponding frequency resolutions) exhibit distinct joint distributions in the frequency domain. This implies a crucial aspect of learning universal knowledge, one that has been overlooked by previous studies. Second, a novel Fourier knowledge attention mechanism is proposed to enable learning time granularity-aware representations from both the temporal and frequency domains. Third, an autoregressive blank infilling pre-training framework is incorporated to time series analysis for the first time, leading to a generative tasks agnostic pre-training strategy. To this end, we develop the General Time-series Model (GTM), a unified MTS foundation model that addresses the limitation of contemporary time series models, which often require token, pre-training, or model-level customizations for downstream tasks adaption. Fourth, extensive experiments show that GTM outperforms state-of-the-art (SOTA) methods across all generative tasks, including long-term forecasting, anomaly detection, and imputation.