 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLookBench: A Live and Holistic Open Benchmark for Fashion Image Retrieval
Jan 21, 2026In this paper, we present LookBench (We use the term "look" to reflect retrieval that mirrors how people shop -- finding the exact item, a close substitute, or a visually consistent alternative.), a live, holistic and challenging benchmark for fashion image retrieval in real e-commerce settings. LookBench includes both recent product images sourced from live websites and AI-generated fashion images, reflecting contemporary trends and use cases. Each test sample is time-stamped and we intend to update the benchmark periodically, enabling contamination-aware evaluation aligned with declared training cutoffs. Grounded in our fine-grained attribute taxonomy, LookBench covers single-item and outfit-level retrieval across. Our experiments reveal that LookBench poses a significant challenge on strong baselines, with many models achieving below $60\%$ Recall@1. Our proprietary model achieves the best performance on LookBench, and we release an open-source counterpart that ranks second, with both models attaining state-of-the-art results on legacy Fashion200K evaluations. LookBench is designed to be updated semi-annually with new test samples and progressively harder task variants, providing a durable measure of progress. We publicly release our leaderboard, dataset, evaluation code, and trained models.
DORAEMON: A Unified Library for Visual Object Modeling and Representation Learning at Scale
Nov 06, 2025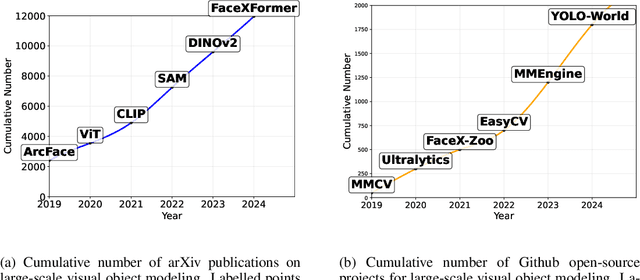
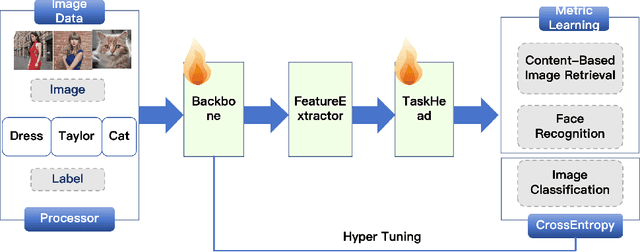
DORAEMON is an open-source PyTorch library that unifies visual object modeling and representation learning across diverse scales. A single YAML-driven workflow covers classification, retrieval and metric learning; more than 1000 pretrained backbones are exposed through a timm-compatible interface, together with modular losses, augmentations and distributed-training utilities. Reproducible recipes match or exceed reference results on ImageNet-1K, MS-Celeb-1M and Stanford online products, while one-command export to ONNX or HuggingFace bridges research and deployment. By consolidating datasets, models, and training techniques into one platform, DORAEMON offers a scalable foundation for rapid experimentation in visual recognition and representation learning, enabling efficient transfer of research advances to real-world applications. The repository is available at https://github.com/wuji3/DORAEMON.
ROMAS: A Role-Based Multi-Agent System for Database monitoring and Planning
Dec 18, 2024



In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities in data analytics when integrated with Multi-Agent Systems (MAS). However, these systems often struggle with complex tasks that involve diverse functional requirements and intricate data processing challenges, necessitating customized solutions that lack broad applicability. Furthermore, current MAS fail to emulate essential human-like traits such as self-planning, self-monitoring, and collaborative work in dynamic environments, leading to inefficiencies and resource wastage. To address these limitations, we propose ROMAS, a novel Role-Based M ulti-A gent System designed to adapt to various scenarios while enabling low code development and one-click deployment. ROMAS has been effectively deployed in DB-GPT [Xue et al., 2023a, 2024b], a well-known project utilizing LLM-powered database analytics, showcasing its practical utility in real-world scenarios. By integrating role-based collaborative mechanisms for self-monitoring and self-planning, and leveraging existing MAS capabilities to enhance database interactions, ROMAS offers a more effective and versatile solution. Experimental evaluations of ROMAS demonstrate its superiority across multiple scenarios, highlighting its potential to advance the field of multi-agent data analytics.
FAMMA: A Benchmark for Financial Domain Multilingual Multimodal Question Answering
Oct 06, 2024



In this paper, we introduce FAMMA, an open-source benchmark for financial multilingual multimodal question answering (QA). Our benchmark aims to evaluate the abilities of multimodal large language models (MLLMs) in answering questions that require advanced financial knowledge and sophisticated reasoning. It includes 1,758 meticulously collected question-answer pairs from university textbooks and exams, spanning 8 major subfields in finance including corporate finance, asset management, and financial engineering. Some of the QA pairs are written in Chinese or French, while a majority of them are in English. These questions are presented in a mixed format combining text and heterogeneous image types, such as charts, tables, and diagrams. We evaluate a range of state-of-the-art MLLMs on our benchmark, and our analysis shows that FAMMA poses a significant challenge for these models. Even advanced systems like GPT-4o and Claude-35-Sonnet achieve only 42\% accuracy. Additionally, the open-source Qwen2-VL lags notably behind its proprietary counterparts. Lastly, we explore GPT o1-style reasoning chains to enhance the models' reasoning capabilities, which significantly improve error correction. Our FAMMA benchmark will facilitate future research to develop expert systems in financial QA. The leaderboard is available at https://famma-bench.github.io/famma/ .
GMP-AR: Granularity Message Passing and Adaptive Reconciliation for Temporal Hierarchy Forecasting
Jun 18, 2024
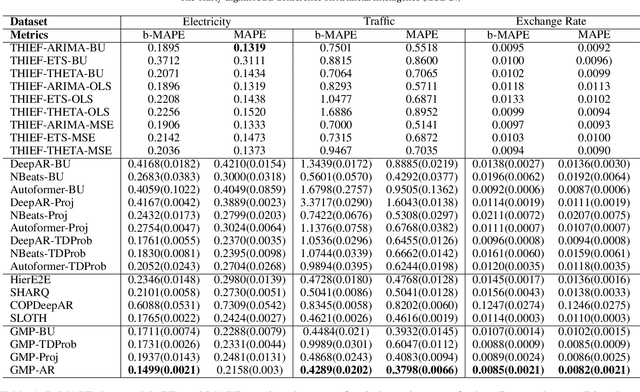
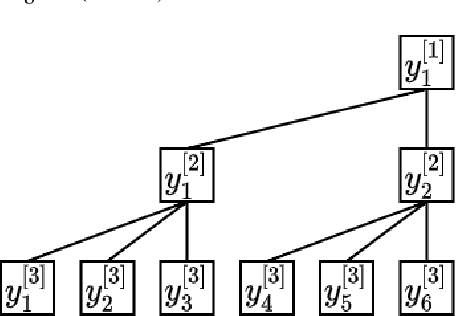
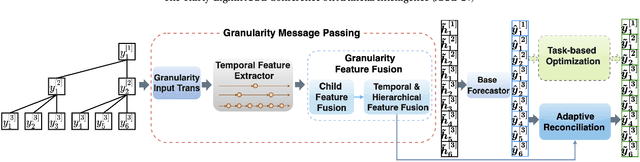
Time series forecasts of different temporal granularity are widely used in real-world applications, e.g., sales prediction in days and weeks for making different inventory plans. However, these tasks are usually solved separately without ensuring coherence, which is crucial for aligning downstream decisions. Previous works mainly focus on ensuring coherence with some straightforward methods, e.g., aggregation from the forecasts of fine granularity to the coarse ones, and allocation from the coarse granularity to the fine ones. These methods merely take the temporal hierarchical structure to maintain coherence without improving the forecasting accuracy. In this paper, we propose a novel granularity message-passing mechanism (GMP) that leverages temporal hierarchy information to improve forecasting performance and also utilizes an adaptive reconciliation (AR) strategy to maintain coherence without performance loss. Furthermore, we introduce an optimization module to achieve task-based targets while adhering to more real-world constraints. Experiments on real-world datasets demonstrate that our framework (GMP-AR) achieves superior performances on temporal hierarchical forecasting tasks compared to state-of-the-art methods. In addition, our framework has been successfully applied to a real-world task of payment traffic management in Alipay by integrating with the task-based optimization module.
Interpretable Catastrophic Forgetting of Large Language Model Fine-tuning via Instruction Vector
Jun 18, 2024



Fine-tuning large language models (LLMs) can cause them to lose their general capabilities. However, the intrinsic mechanisms behind such forgetting remain unexplored. In this paper, we begin by examining this phenomenon by focusing on knowledge understanding and instruction following, with the latter identified as the main contributor to forgetting during fine-tuning. Consequently, we propose the Instruction Vector (IV) framework to capture model representations highly related to specific instruction-following capabilities, thereby making it possible to understand model-intrinsic forgetting. Through the analysis of IV dynamics pre and post-training, we suggest that fine-tuning mostly adds specialized reasoning patterns instead of erasing previous skills, which may appear as forgetting. Building on this insight, we develop IV-guided training, which aims to preserve original computation graph, thereby mitigating catastrophic forgetting. Empirical tests on three benchmarks confirm the efficacy of this new approach, supporting the relationship between IVs and forgetting. Our code will be made available soon.
Sora Detector: A Unified Hallucination Detection for Large Text-to-Video Models
May 07, 2024



The rapid advancement in text-to-video (T2V) generative models has enabled the synthesis of high-fidelity video content guided by textual descriptions. Despite this significant progress, these models are often susceptible to hallucination, generating contents that contradict the input text, which poses a challenge to their reliability and practical deployment. To address this critical issue, we introduce the SoraDetector, a novel unified framework designed to detect hallucinations across diverse large T2V models, including the cutting-edge Sora model. Our framework is built upon a comprehensive analysis of hallucination phenomena, categorizing them based on their manifestation in the video content. Leveraging the state-of-the-art keyframe extraction techniques and multimodal large language models, SoraDetector first evaluates the consistency between extracted video content summary and textual prompts, then constructs static and dynamic knowledge graphs (KGs) from frames to detect hallucination both in single frames and across frames. Sora Detector provides a robust and quantifiable measure of consistency, static and dynamic hallucination. In addition, we have developed the Sora Detector Agent to automate the hallucination detection process and generate a complete video quality report for each input video. Lastly, we present a novel meta-evaluation benchmark, T2VHaluBench, meticulously crafted to facilitate the evaluation of advancements in T2V hallucination detection. Through extensive experiments on videos generated by Sora and other large T2V models, we demonstrate the efficacy of our approach in accurately detecting hallucinations. The code and dataset can be accessed via GitHub.
Demonstration of DB-GPT: Next Generation Data Interaction System Empowered by Large Language Models
Apr 18, 2024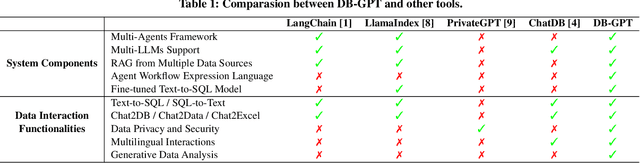
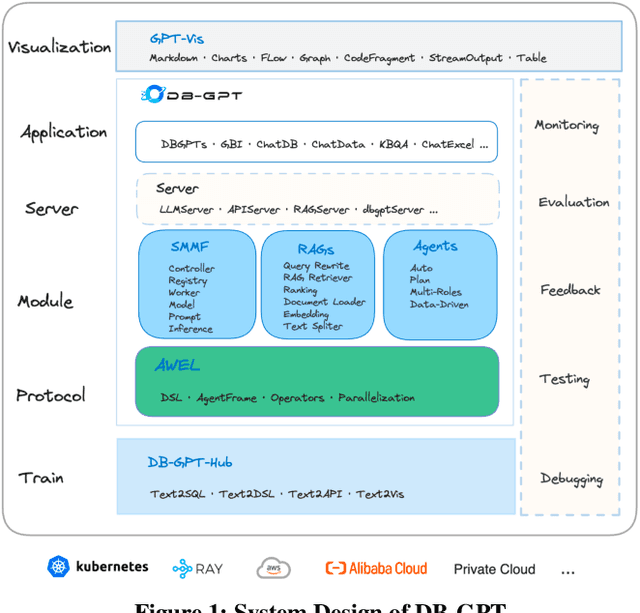

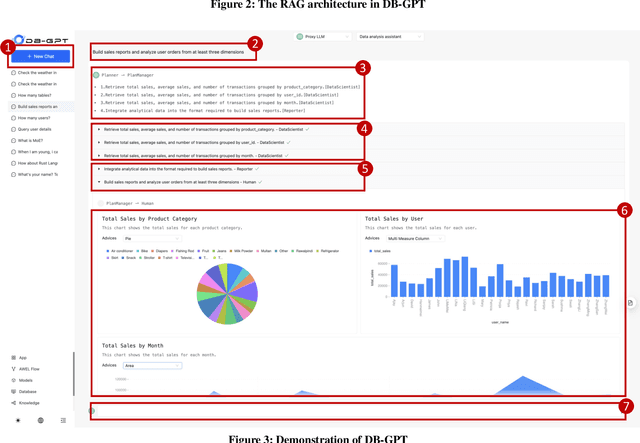
The recent breakthroughs in large language models (LLMs) are positioned to transition many areas of software. The technologies of interacting with data particularly have an important entanglement with LLMs as efficient and intuitive data interactions are paramount. In this paper, we present DB-GPT, a revolutionary and product-ready Python library that integrates LLMs into traditional data interaction tasks to enhance user experience and accessibility. DB-GPT is designed to understand data interaction tasks described by natural language and provide context-aware responses powered by LLMs, making it an indispensable tool for users ranging from novice to expert. Its system design supports deployment across local, distributed, and cloud environments. Beyond handling basic data interaction tasks like Text-to-SQL with LLMs, it can handle complex tasks like generative data analysis through a Multi-Agents framework and the Agentic Workflow Expression Language (AWEL). The Service-oriented Multi-model Management Framework (SMMF) ensures data privacy and security, enabling users to employ DB-GPT with private LLMs. Additionally, DB-GPT offers a series of product-ready features designed to enable users to integrate DB-GPT within their product environments easily. The code of DB-GPT is available at Github(https://github.com/eosphoros-ai/DB-GPT) which already has over 10.7k stars. Please install DB-GPT for your own usage with the instructions(https://github.com/eosphoros-ai/DB-GPT#install) and watch a 5-minute introduction video on Youtube(https://youtu.be/n_8RI1ENyl4) to further investigate DB-GPT.
Large Models for Time Series and Spatio-Temporal Data: A Survey and Outlook
Oct 20, 2023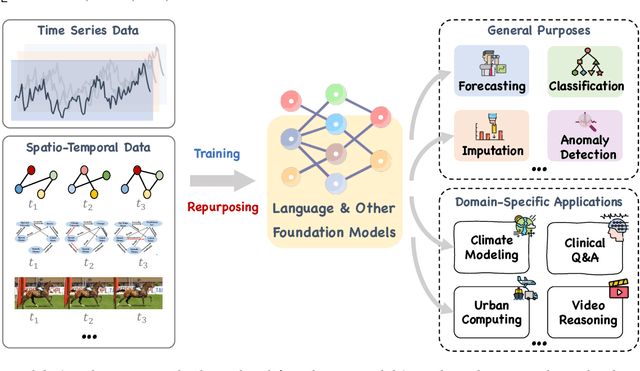
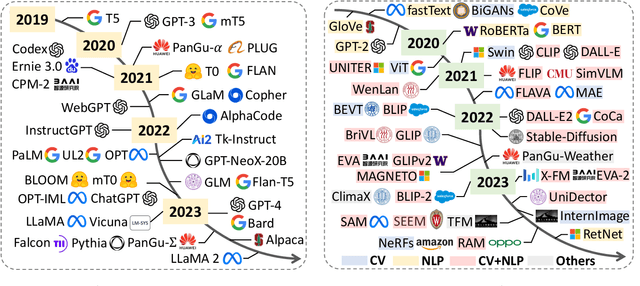
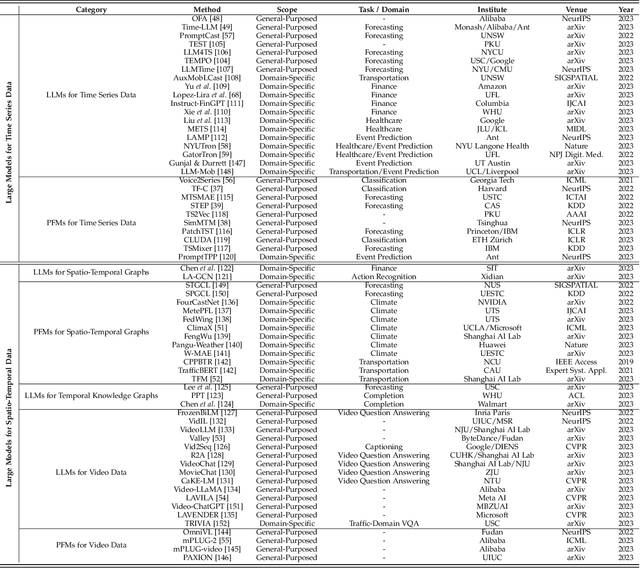
Temporal data, notably time series and spatio-temporal data, are prevalent in real-world applications. They capture dynamic system measurements and are produced in vast quantities by both physical and virtual sensors. Analyzing these data types is vital to harnessing the rich information they encompass and thus benefits a wide range of downstream tasks. Recent advances in large language and other foundational models have spurred increased use of these models in time series and spatio-temporal data mining. Such methodologies not only enable enhanced pattern recognition and reasoning across diverse domains but also lay the groundwork for artificial general intelligence capable of comprehending and processing common temporal data. In this survey, we offer a comprehensive and up-to-date review of large models tailored (or adapted) for time series and spatio-temporal data, spanning four key facets: data types, model categories, model scopes, and application areas/tasks. Our objective is to equip practitioners with the knowledge to develop applications and further research in this underexplored domain. We primarily categorize the existing literature into two major clusters: large models for time series analysis (LM4TS) and spatio-temporal data mining (LM4STD). On this basis, we further classify research based on model scopes (i.e., general vs. domain-specific) and application areas/tasks. We also provide a comprehensive collection of pertinent resources, including datasets, model assets, and useful tools, categorized by mainstream applications. This survey coalesces the latest strides in large model-centric research on time series and spatio-temporal data, underscoring the solid foundations, current advances, practical applications, abundant resources, and future research opportunities.
Towards Anytime Fine-tuning: Continually Pre-trained Language Models with Hypernetwork Prompt
Oct 19, 2023


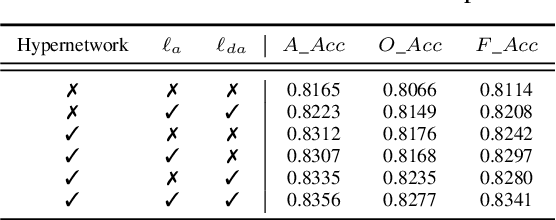
Continual pre-training has been urgent for adapting a pre-trained model to a multitude of domains and tasks in the fast-evolving world. In practice, a continually pre-trained model is expected to demonstrate not only greater capacity when fine-tuned on pre-trained domains but also a non-decreasing performance on unseen ones. In this work, we first investigate such anytime fine-tuning effectiveness of existing continual pre-training approaches, concluding with unanimously decreased performance on unseen domains. To this end, we propose a prompt-guided continual pre-training method, where we train a hypernetwork to generate domain-specific prompts by both agreement and disagreement losses. The agreement loss maximally preserves the generalization of a pre-trained model to new domains, and the disagreement one guards the exclusiveness of the generated hidden states for each domain. Remarkably, prompts by the hypernetwork alleviate the domain identity when fine-tuning and promote knowledge transfer across domains. Our method achieved improvements of 3.57% and 3.4% on two real-world datasets (including domain shift and temporal shift), respectively, demonstrating its efficacy.