 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Logical Reasoning Abilities of Large Reasoning Models
May 17, 2025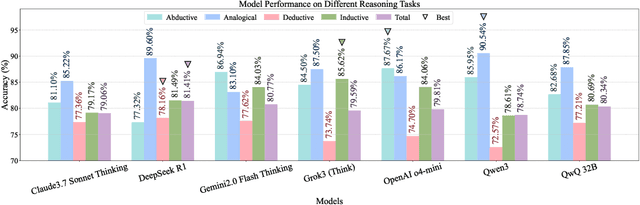

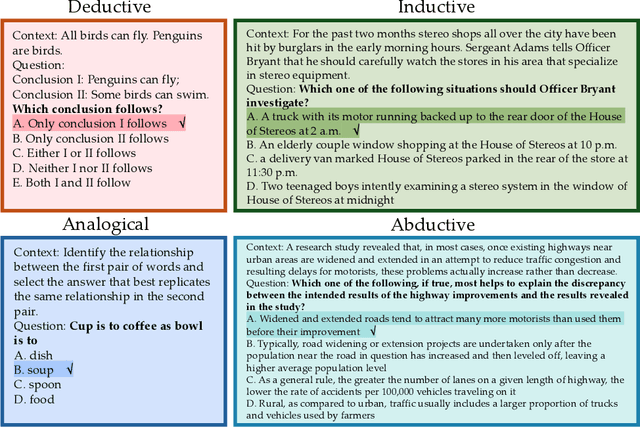
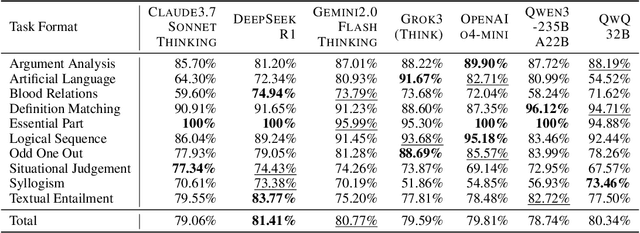
Large reasoning models, often post-trained on long chain-of-thought (long CoT) data with reinforcement learning, achieve state-of-the-art performance on mathematical, coding, and domain-specific reasoning benchmarks. However, their logical reasoning capabilities - fundamental to human cognition and independent of domain knowledge - remain understudied. To address this gap, we introduce LogiEval, a holistic benchmark for evaluating logical reasoning in large reasoning models. LogiEval spans diverse reasoning types (deductive, inductive, analogical, and abductive) and task formats (e.g., logical sequence, argument analysis), sourced from high-quality human examinations (e.g., LSAT, GMAT). Our experiments demonstrate that modern reasoning models excel at 4-choice argument analysis problems and analogical reasoning, surpassing human performance, yet exhibit uneven capabilities across reasoning types and formats, highlighting limitations in their generalization. Our analysis reveals that human performance does not mirror model failure distributions. To foster further research, we curate LogiEval-Hard, a challenging subset identified through a novel screening paradigm where small-model failures (Qwen3-30B-A3B) reliably predict difficulties for larger models. Modern models show striking, consistent failures on LogiEval-Hard. This demonstrates that fundamental reasoning bottlenecks persist across model scales, and establishes LogiEval-Hard as both a diagnostic tool and a rigorous testbed for advancing logical reasoning in LLMs.
Logical Reasoning in Large Language Models: A Survey
Feb 13, 2025
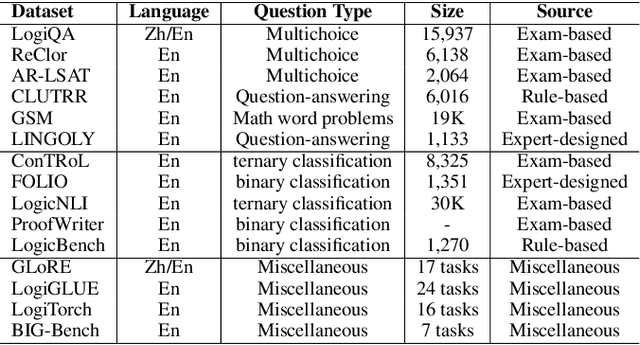

With the emergence of advanced reasoning models like OpenAI o3 and DeepSeek-R1, large language models (LLMs) have demonstrated remarkable reasoning capabilities. However, their ability to perform rigorous logical reasoning remains an open question. This survey synthesizes recent advancements in logical reasoning within LLMs, a critical area of AI research. It outlines the scope of logical reasoning in LLMs, its theoretical foundations, and the benchmarks used to evaluate reasoning proficiency. We analyze existing capabilities across different reasoning paradigms - deductive, inductive, abductive, and analogical - and assess strategies to enhance reasoning performance, including data-centric tuning, reinforcement learning, decoding strategies, and neuro-symbolic approaches. The review concludes with future directions, emphasizing the need for further exploration to strengthen logical reasoning in AI systems.
Time Series Analysis for Education: Methods, Applications, and Future Directions
Aug 27, 2024
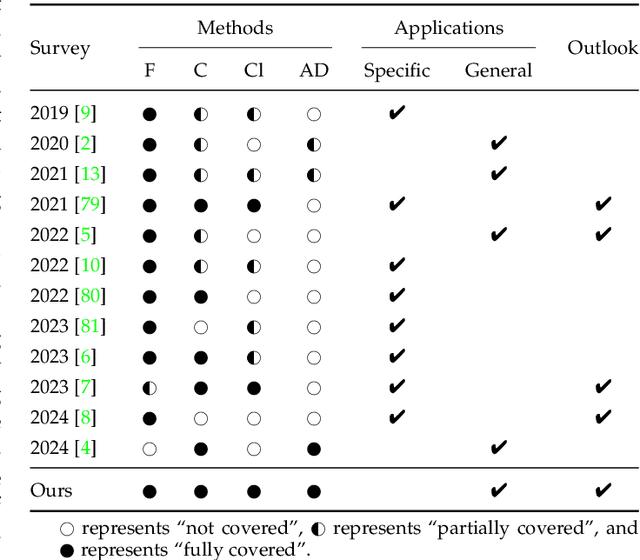
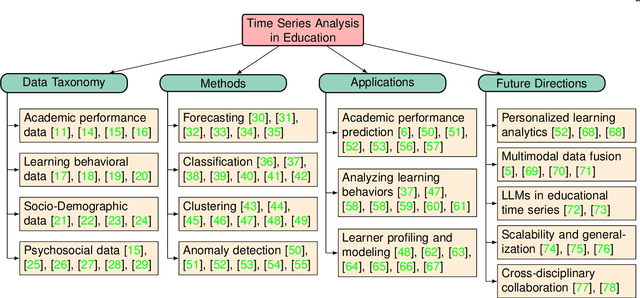
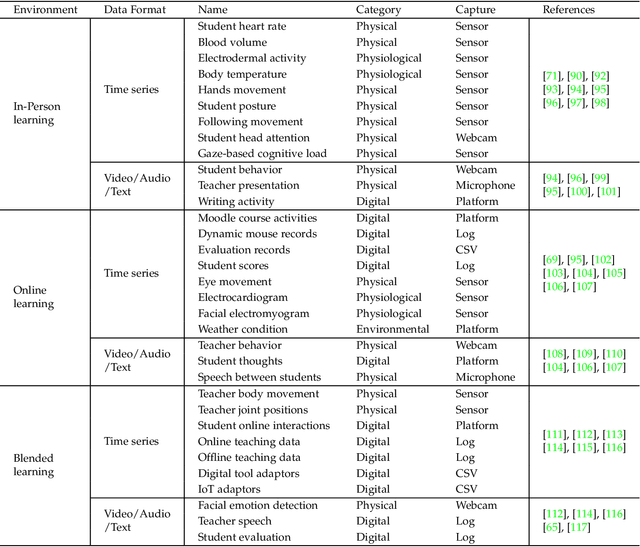
Recent advancements in the collection and analysis of sequential educational data have brought time series analysis to a pivotal position in educational research, highlighting its essential role in facilitating data-driven decision-making. However, there is a lack of comprehensive summaries that consolidate these advancements. To the best of our knowledge, this paper is the first to provide a comprehensive review of time series analysis techniques specifically within the educational context. We begin by exploring the landscape of educational data analytics, categorizing various data sources and types relevant to education. We then review four prominent time series methods-forecasting, classification, clustering, and anomaly detection-illustrating their specific application points in educational settings. Subsequently, we present a range of educational scenarios and applications, focusing on how these methods are employed to address diverse educational tasks, which highlights the practical integration of multiple time series methods to solve complex educational problems. Finally, we conclude with a discussion on future directions, including personalized learning analytics, multimodal data fusion, and the role of large language models (LLMs) in educational time series. The contributions of this paper include a detailed taxonomy of educational data, a synthesis of time series techniques with specific educational applications, and a forward-looking perspective on emerging trends and future research opportunities in educational analysis. The related papers and resources are available and regularly updated at the project page.
A Survey on Diffusion Models for Time Series and Spatio-Temporal Data
Apr 29, 2024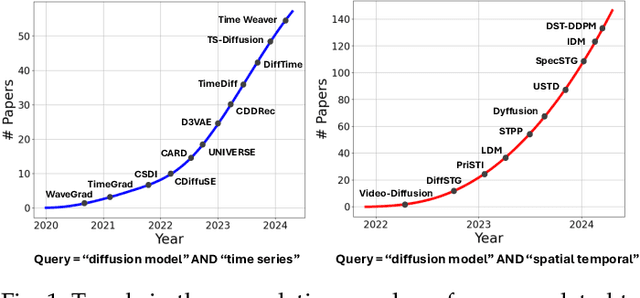
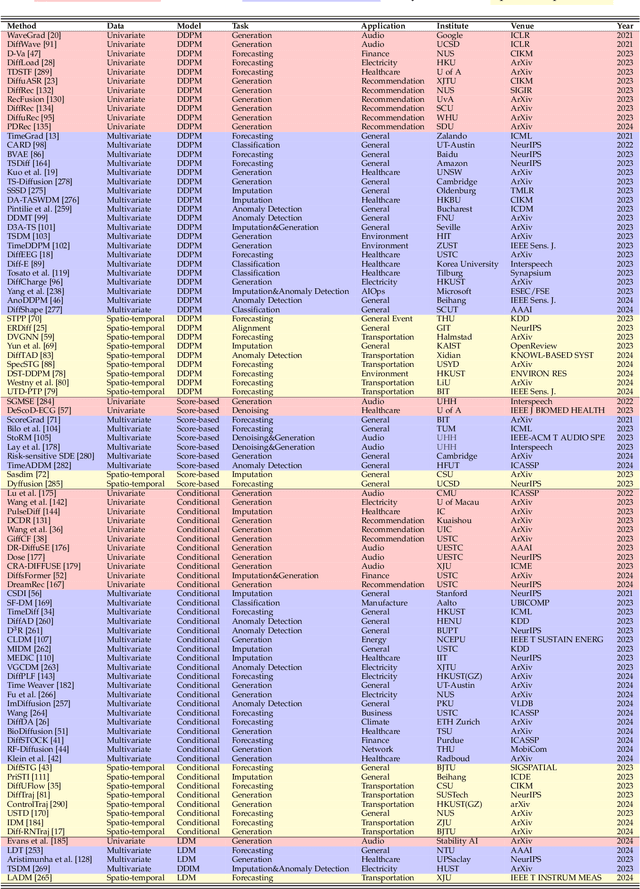
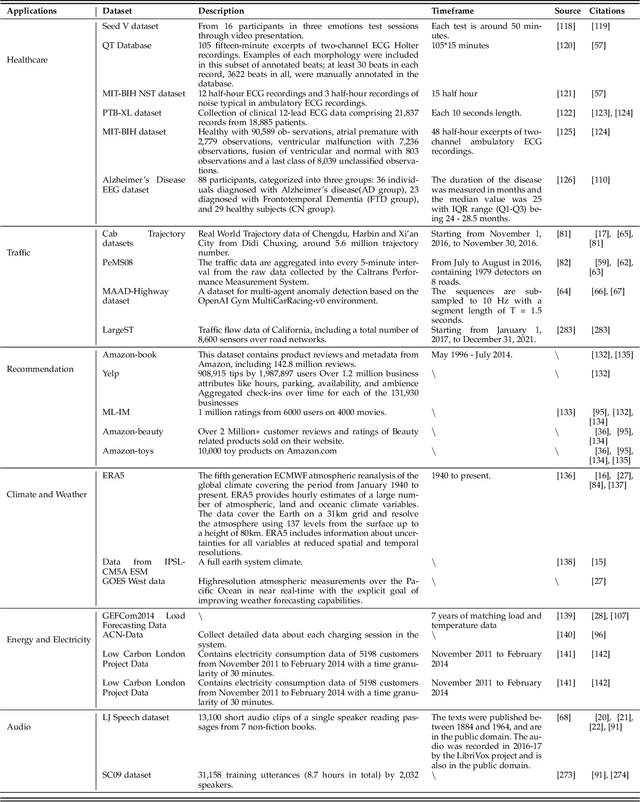
The study of time series data is crucial for understanding trends and anomalies over time, enabling predictive insights across various sectors. Spatio-temporal data, on the other hand, is vital for analyzing phenomena in both space and time, providing a dynamic perspective on complex system interactions. Recently, diffusion models have seen widespread application in time series and spatio-temporal data mining. Not only do they enhance the generative and inferential capabilities for sequential and temporal data, but they also extend to other downstream tasks. In this survey, we comprehensively and thoroughly review the use of diffusion models in time series and spatio-temporal data, categorizing them by model category, task type, data modality, and practical application domain. In detail, we categorize diffusion models into unconditioned and conditioned types and discuss time series data and spatio-temporal data separately. Unconditioned models, which operate unsupervised, are subdivided into probability-based and score-based models, serving predictive and generative tasks such as forecasting, anomaly detection, classification, and imputation. Conditioned models, on the other hand, utilize extra information to enhance performance and are similarly divided for both predictive and generative tasks. Our survey extensively covers their application in various fields, including healthcare, recommendation, climate, energy, audio, and transportation, providing a foundational understanding of how these models analyze and generate data. Through this structured overview, we aim to provide researchers and practitioners with a comprehensive understanding of diffusion models for time series and spatio-temporal data analysis, aiming to direct future innovations and applications by addressing traditional challenges and exploring innovative solutions within the diffusion model framework.
Logic Agent: Enhancing Validity with Logic Rule Invocation
Apr 28, 2024Chain-of-Thought (CoT) prompting has emerged as a pivotal technique for augmenting the inferential capabilities of language models during reasoning tasks. Despite its advancements, CoT often grapples with challenges in validating reasoning validity and ensuring informativeness. Addressing these limitations, this paper introduces the Logic Agent (LA), an agent-based framework aimed at enhancing the validity of reasoning processes in Large Language Models (LLMs) through strategic logic rule invocation. Unlike conventional approaches, LA transforms LLMs into logic agents that dynamically apply propositional logic rules, initiating the reasoning process by converting natural language inputs into structured logic forms. The logic agent leverages a comprehensive set of predefined functions to systematically navigate the reasoning process. This methodology not only promotes the structured and coherent generation of reasoning constructs but also significantly improves their interpretability and logical coherence. Through extensive experimentation, we demonstrate LA's capacity to scale effectively across various model sizes, markedly improving the precision of complex reasoning across diverse tasks.
Large Language Models for Education: A Survey and Outlook
Apr 01, 2024

The advent of Large Language Models (LLMs) has brought in a new era of possibilities in the realm of education. This survey paper summarizes the various technologies of LLMs in educational settings from multifaceted perspectives, encompassing student and teacher assistance, adaptive learning, and commercial tools. We systematically review the technological advancements in each perspective, organize related datasets and benchmarks, and identify the risks and challenges associated with deploying LLMs in education. Furthermore, we outline future research opportunities, highlighting the potential promising directions. Our survey aims to provide a comprehensive technological picture for educators, researchers, and policymakers to harness the power of LLMs to revolutionize educational practices and foster a more effective personalized learning environment.
Large Models for Time Series and Spatio-Temporal Data: A Survey and Outlook
Oct 20, 2023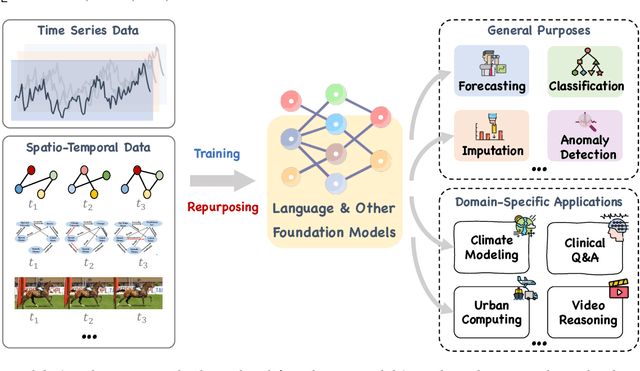
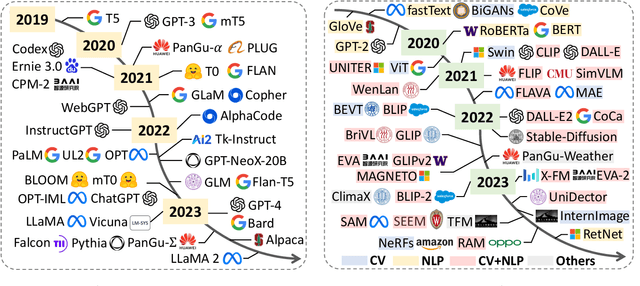
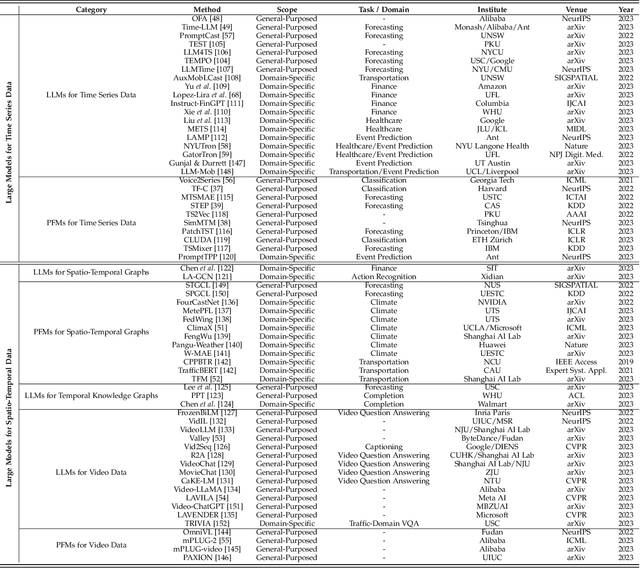
Temporal data, notably time series and spatio-temporal data, are prevalent in real-world applications. They capture dynamic system measurements and are produced in vast quantities by both physical and virtual sensors. Analyzing these data types is vital to harnessing the rich information they encompass and thus benefits a wide range of downstream tasks. Recent advances in large language and other foundational models have spurred increased use of these models in time series and spatio-temporal data mining. Such methodologies not only enable enhanced pattern recognition and reasoning across diverse domains but also lay the groundwork for artificial general intelligence capable of comprehending and processing common temporal data. In this survey, we offer a comprehensive and up-to-date review of large models tailored (or adapted) for time series and spatio-temporal data, spanning four key facets: data types, model categories, model scopes, and application areas/tasks. Our objective is to equip practitioners with the knowledge to develop applications and further research in this underexplored domain. We primarily categorize the existing literature into two major clusters: large models for time series analysis (LM4TS) and spatio-temporal data mining (LM4STD). On this basis, we further classify research based on model scopes (i.e., general vs. domain-specific) and application areas/tasks. We also provide a comprehensive collection of pertinent resources, including datasets, model assets, and useful tools, categorized by mainstream applications. This survey coalesces the latest strides in large model-centric research on time series and spatio-temporal data, underscoring the solid foundations, current advances, practical applications, abundant resources, and future research opportunities.
Benchmarks and Custom Package for Electrical Load Forecasting
Jul 14, 2023



Load forecasting is of great significance in the power industry as it can provide a reference for subsequent tasks such as power grid dispatch, thus bringing huge economic benefits. However, there are many differences between load forecasting and traditional time series forecasting. On the one hand, load forecasting aims to minimize the cost of subsequent tasks such as power grid dispatch, rather than simply pursuing prediction accuracy. On the other hand, the load is largely influenced by many external factors, such as temperature or calendar variables. In addition, the scale of predictions (such as building-level loads and aggregated-level loads) can also significantly impact the predicted results. In this paper, we provide a comprehensive load forecasting archive, which includes load domain-specific feature engineering to help forecasting models better model load data. In addition, different from the traditional loss function which only aims for accuracy, we also provide a method to customize the loss function based on the forecasting error, integrating it into our forecasting framework. Based on this, we conducted extensive experiments on load data at different levels, providing a reference for researchers to compare different load forecasting models.
DCdetector: Dual Attention Contrastive Representation Learning for Time Series Anomaly Detection
Jun 17, 2023
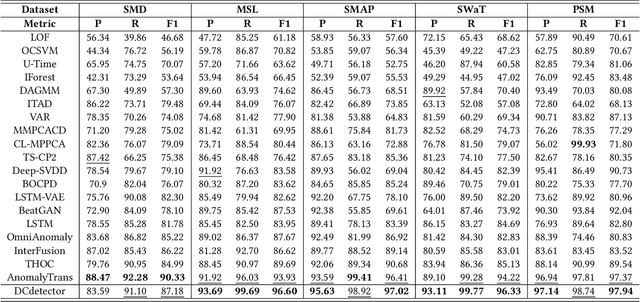
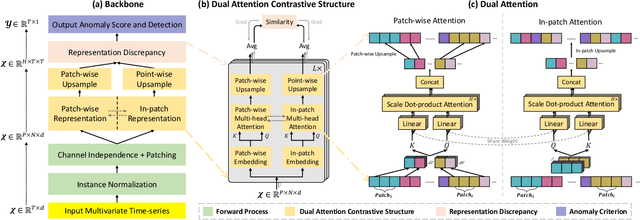
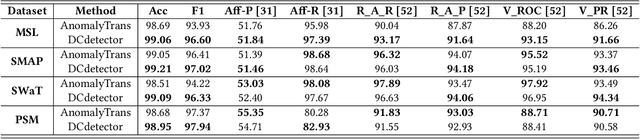
Time series anomaly detection is critical for a wide range of applications. It aims to identify deviant samples from the normal sample distribution in time series. The most fundamental challenge for this task is to learn a representation map that enables effective discrimination of anomalies. Reconstruction-based methods still dominate, but the representation learning with anomalies might hurt the performance with its large abnormal loss. On the other hand, contrastive learning aims to find a representation that can clearly distinguish any instance from the others, which can bring a more natural and promising representation for time series anomaly detection. In this paper, we propose DCdetector, a multi-scale dual attention contrastive representation learning model. DCdetector utilizes a novel dual attention asymmetric design to create the permutated environment and pure contrastive loss to guide the learning process, thus learning a permutation invariant representation with superior discrimination abilities. Extensive experiments show that DCdetector achieves state-of-the-art results on multiple time series anomaly detection benchmark datasets. Code is publicly available at https://github.com/DAMO-DI-ML/KDD2023-DCdetector.
Self-Supervised Learning for Time Series Analysis: Taxonomy, Progress, and Prospects
Jun 16, 2023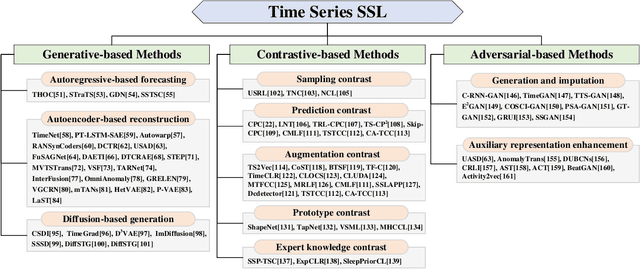
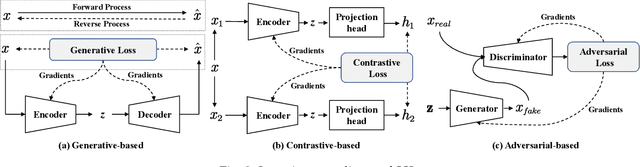
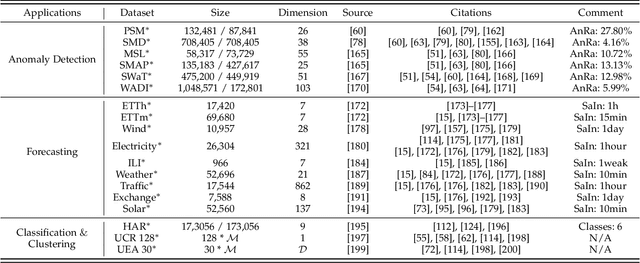
Self-supervised learning (SSL) has recently achieved impressive performance on various time series tasks. The most prominent advantage of SSL is that it reduces the dependence on labeled data. Based on the pre-training and fine-tuning strategy, even a small amount of labeled data can achieve high performance. Compared with many published self-supervised surveys on computer vision and natural language processing, a comprehensive survey for time series SSL is still missing. To fill this gap, we review current state-of-the-art SSL methods for time series data in this article. To this end, we first comprehensively review existing surveys related to SSL and time series, and then provide a new taxonomy of existing time series SSL methods. We summarize these methods into three categories: generative-based, contrastive-based, and adversarial-based. All methods can be further divided into ten subcategories. To facilitate the experiments and validation of time series SSL methods, we also summarize datasets commonly used in time series forecasting, classification, anomaly detection, and clustering tasks. Finally, we present the future directions of SSL for time series analysis.