 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Series Analysis for Education: Methods, Applications, and Future Directions
Aug 27, 2024
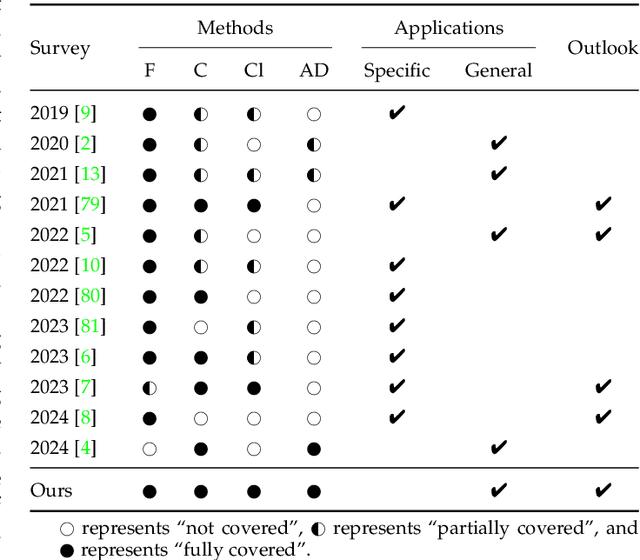
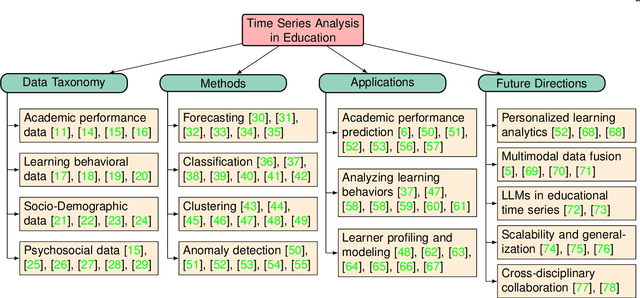
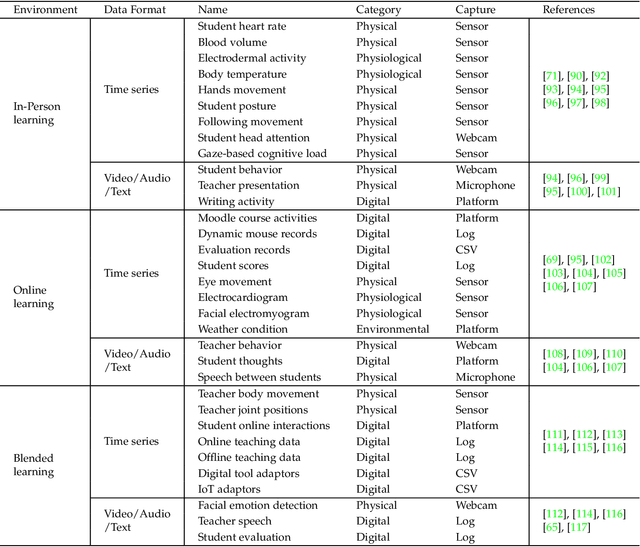
Recent advancements in the collection and analysis of sequential educational data have brought time series analysis to a pivotal position in educational research, highlighting its essential role in facilitating data-driven decision-making. However, there is a lack of comprehensive summaries that consolidate these advancements. To the best of our knowledge, this paper is the first to provide a comprehensive review of time series analysis techniques specifically within the educational context. We begin by exploring the landscape of educational data analytics, categorizing various data sources and types relevant to education. We then review four prominent time series methods-forecasting, classification, clustering, and anomaly detection-illustrating their specific application points in educational settings. Subsequently, we present a range of educational scenarios and applications, focusing on how these methods are employed to address diverse educational tasks, which highlights the practical integration of multiple time series methods to solve complex educational problems. Finally, we conclude with a discussion on future directions, including personalized learning analytics, multimodal data fusion, and the role of large language models (LLMs) in educational time series. The contributions of this paper include a detailed taxonomy of educational data, a synthesis of time series techniques with specific educational applications, and a forward-looking perspective on emerging trends and future research opportunities in educational analysis. The related papers and resources are available and regularly updated at the project page.
EDU-level Extractive Summarization with Varying Summary Lengths
Oct 08, 2022
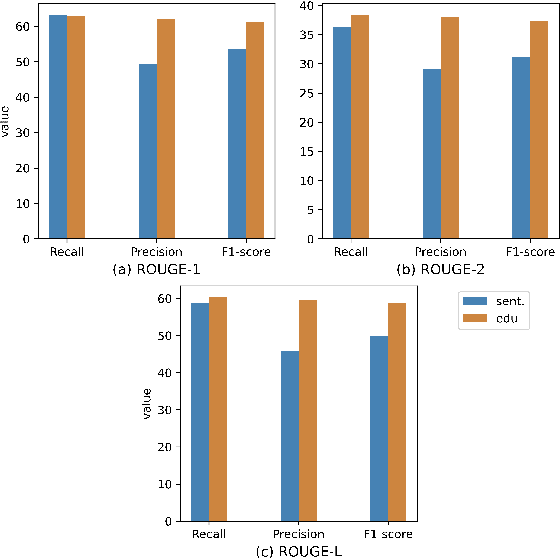
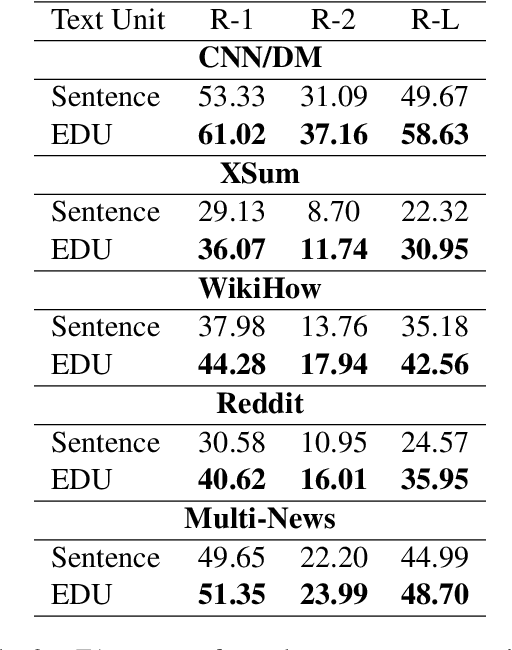
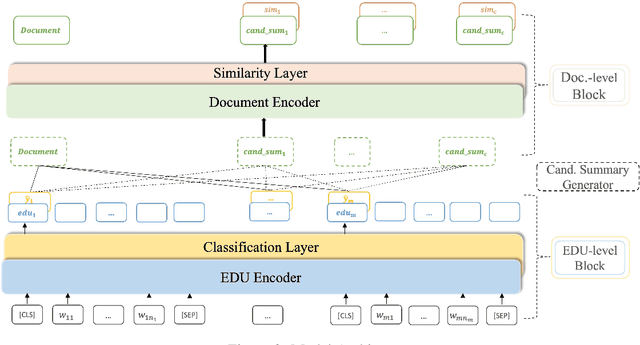
Extractive models usually formulate text summarization as extracting top-k important sentences from document as summary. Few work exploited extracting finer-grained Elementary Discourse Unit (EDU) and there is little analysis and justification for the extractive unit selection. To fill such a gap, this paper firstly conducts oracle analysis to compare the upper bound of performance for models based on EDUs and sentences. The analysis provides evidences from both theoretical and experimental perspectives to justify that EDUs make more concise and precise summary than sentences without losing salient information. Then, considering this merit of EDUs, this paper further proposes EDU-level extractive model with Varying summary Lengths (EDU-VL) and develops the corresponding learning algorithm. EDU-VL learns to encode and predict probabilities of EDUs in document, and encode EDU-level candidate summaries with different lengths based on various $k$ values and select the best candidate summary in an end-to-end training manner. Finally, the proposed and developed approach is experimented on single and multi-document benchmark datasets and shows the improved performances in comparison with the state-of-the-art models.
UPANets: Learning from the Universal Pixel Attention Networks
Mar 22, 2021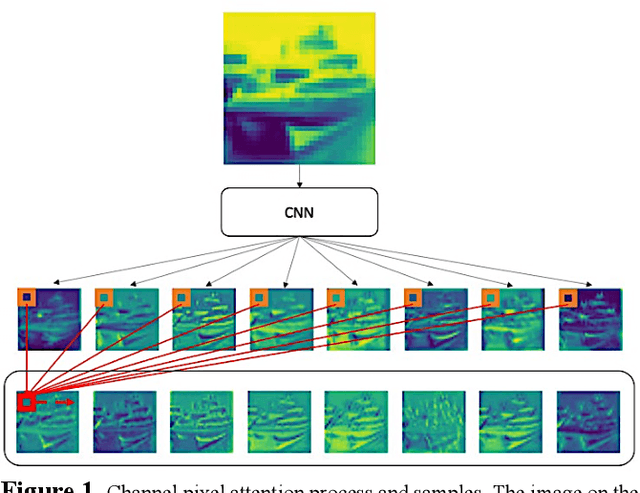
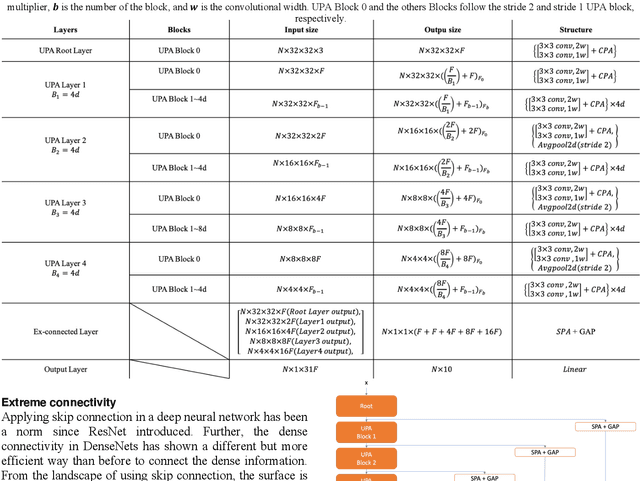
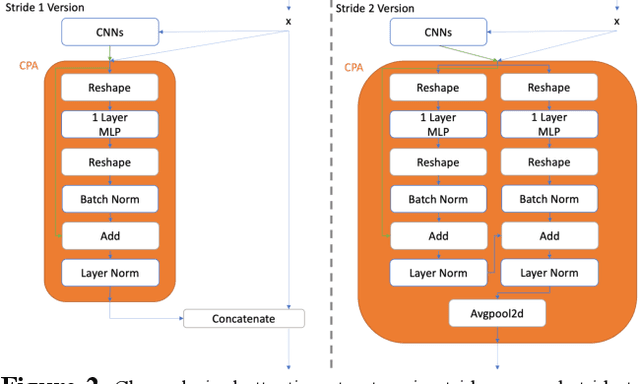
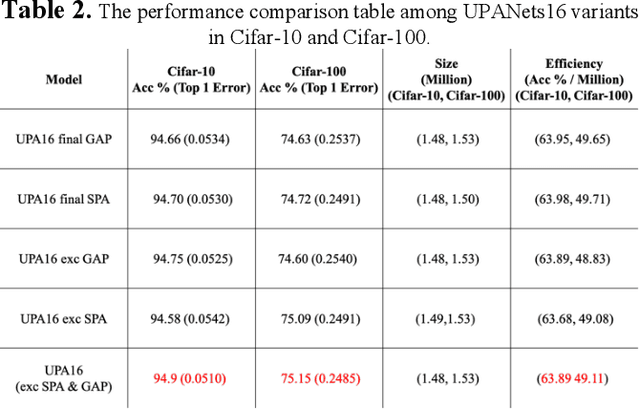
Among image classification, skip and densely-connection-based networks have dominated most leaderboards. Recently, from the successful development of multi-head attention in natural language processing, it is sure that now is a time of either using a Transformer-like model or hybrid CNNs with attention. However, the former need a tremendous resource to train, and the latter is in the perfect balance in this direction. In this work, to make CNNs handle global and local information, we proposed UPANets, which equips channel-wise attention with a hybrid skip-densely-connection structure. Also, the extreme-connection structure makes UPANets robust with a smoother loss landscape. In experiments, UPANets surpassed most well-known and widely-used SOTAs with an accuracy of 96.47% in Cifar-10, 80.29% in Cifar-100, and 67.67% in Tiny Imagenet. Most importantly, these performances have high parameters efficiency and only trained in one customer-based GPU. We share implementing code of UPANets in https://github.com/hanktseng131415go/UPANets.