 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUMAIR-FPS: User-aware Multi-modal Animation Illustration Recommendation Fusion with Painting Style
Feb 16, 2024



The rapid advancement of high-quality image generation models based on AI has generated a deluge of anime illustrations. Recommending illustrations to users within massive data has become a challenging and popular task. However, existing anime recommendation systems have focused on text features but still need to integrate image features. In addition, most multi-modal recommendation research is constrained by tightly coupled datasets, limiting its applicability to anime illustrations. We propose the User-aware Multi-modal Animation Illustration Recommendation Fusion with Painting Style (UMAIR-FPS) to tackle these gaps. In the feature extract phase, for image features, we are the first to combine image painting style features with semantic features to construct a dual-output image encoder for enhancing representation. For text features, we obtain text embeddings based on fine-tuning Sentence-Transformers by incorporating domain knowledge that composes a variety of domain text pairs from multilingual mappings, entity relationships, and term explanation perspectives, respectively. In the multi-modal fusion phase, we novelly propose a user-aware multi-modal contribution measurement mechanism to weight multi-modal features dynamically according to user features at the interaction level and employ the DCN-V2 module to model bounded-degree multi-modal crosses effectively. UMAIR-FPS surpasses the stat-of-the-art baselines on large real-world datasets, demonstrating substantial performance enhancements.
Knowledge From the Dark Side: Entropy-Reweighted Knowledge Distillation for Balanced Knowledge Transfer
Nov 22, 2023



Knowledge Distillation (KD) transfers knowledge from a larger "teacher" model to a compact "student" model, guiding the student with the "dark knowledge" $\unicode{x2014}$ the implicit insights present in the teacher's soft predictions. Although existing KDs have shown the potential of transferring knowledge, the gap between the two parties still exists. With a series of investigations, we argue the gap is the result of the student's overconfidence in prediction, signaling an imbalanced focus on pronounced features while overlooking the subtle yet crucial dark knowledge. To overcome this, we introduce the Entropy-Reweighted Knowledge Distillation (ER-KD), a novel approach that leverages the entropy in the teacher's predictions to reweight the KD loss on a sample-wise basis. ER-KD precisely refocuses the student on challenging instances rich in the teacher's nuanced insights while reducing the emphasis on simpler cases, enabling a more balanced knowledge transfer. Consequently, ER-KD not only demonstrates compatibility with various state-of-the-art KD methods but also further enhances their performance at negligible cost. This approach offers a streamlined and effective strategy to refine the knowledge transfer process in KD, setting a new paradigm in the meticulous handling of dark knowledge. Our code is available at https://github.com/cpsu00/ER-KD.
A Novel Method of Fuzzy Topic Modeling based on Transformer Processing
Sep 18, 2023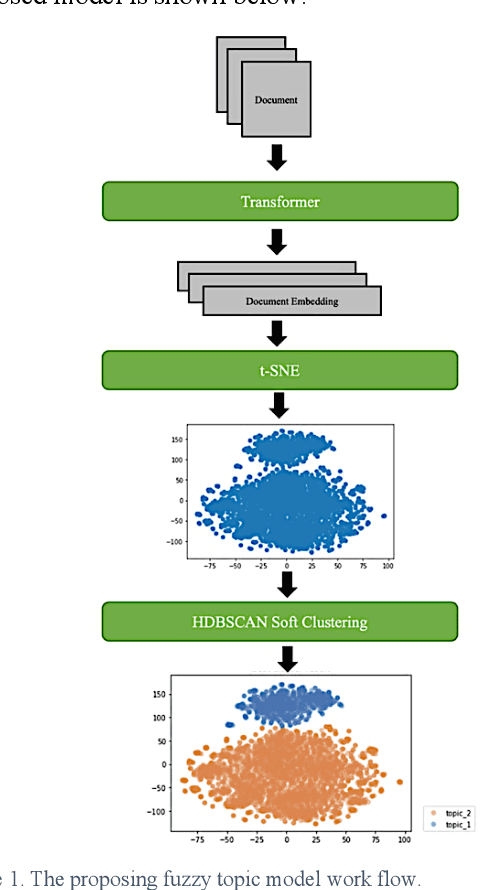


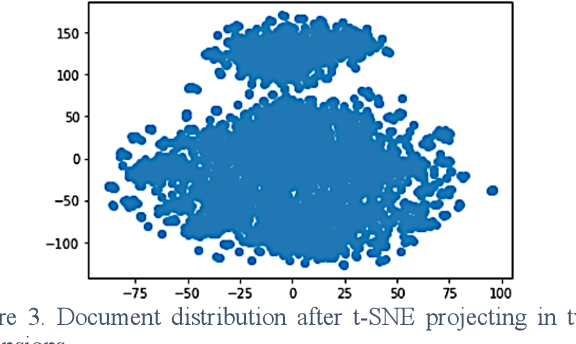
Topic modeling is admittedly a convenient way to monitor markets trend. Conventionally, Latent Dirichlet Allocation, LDA, is considered a must-do model to gain this type of information. By given the merit of deducing keyword with token conditional probability in LDA, we can know the most possible or essential topic. However, the results are not intuitive because the given topics cannot wholly fit human knowledge. LDA offers the first possible relevant keywords, which also brings out another problem of whether the connection is reliable based on the statistic possibility. It is also hard to decide the topic number manually in advance. As the booming trend of using fuzzy membership to cluster and using transformers to embed words, this work presents the fuzzy topic modeling based on soft clustering and document embedding from state-of-the-art transformer-based model. In our practical application in a press release monitoring, the fuzzy topic modeling gives a more natural result than the traditional output from LDA.
Real-time Automatic M-mode Echocardiography Measurement with Panel Attention from Local-to-Global Pixels
Aug 15, 2023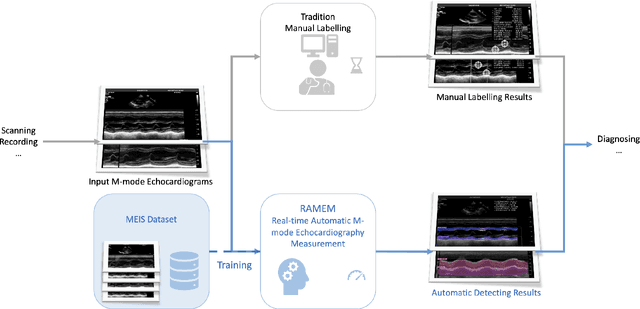
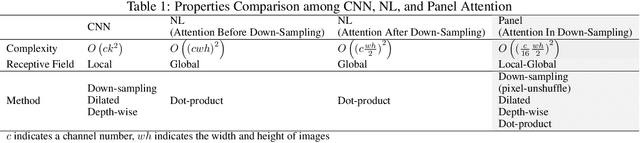
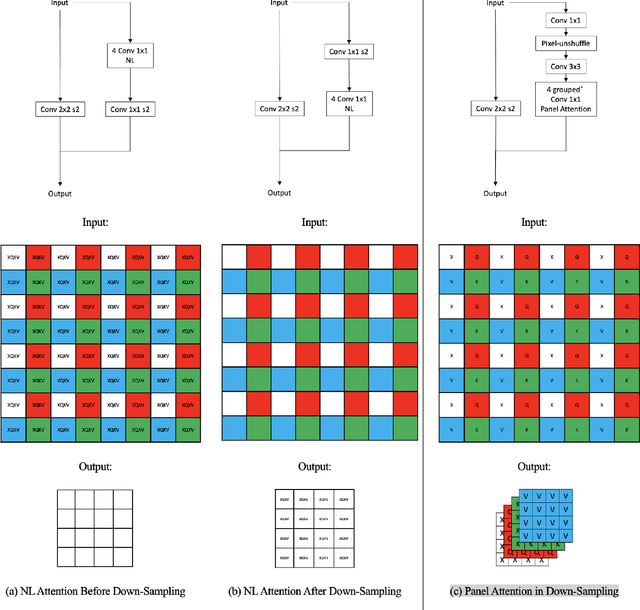

Motion mode (M-mode) recording is an essential part of echocardiography to measure cardiac dimension and function. However, the current diagnosis cannot build an automatic scheme, as there are three fundamental obstructs: Firstly, there is no open dataset available to build the automation for ensuring constant results and bridging M-mode echocardiography with real-time instance segmentation (RIS); Secondly, the examination is involving the time-consuming manual labelling upon M-mode echocardiograms; Thirdly, as objects in echocardiograms occupy a significant portion of pixels, the limited receptive field in existing backbones (e.g., ResNet) composed from multiple convolution layers are inefficient to cover the period of a valve movement. Existing non-local attentions (NL) compromise being unable real-time with a high computation overhead or losing information from a simplified version of the non-local block. Therefore, we proposed RAMEM, a real-time automatic M-mode echocardiography measurement scheme, contributes three aspects to answer the problems: 1) provide MEIS, a dataset of M-mode echocardiograms for instance segmentation, to enable consistent results and support the development of an automatic scheme; 2) propose panel attention, local-to-global efficient attention by pixel-unshuffling, embedding with updated UPANets V2 in a RIS scheme toward big object detection with global receptive field; 3) develop and implement AMEM, an efficient algorithm of automatic M-mode echocardiography measurement enabling fast and accurate automatic labelling among diagnosis. The experimental results show that RAMEM surpasses existing RIS backbones (with non-local attention) in PASCAL 2012 SBD and human performances in real-time MEIS tested. The code of MEIS and dataset are available at https://github.com/hanktseng131415go/RAME.
UPANets: Learning from the Universal Pixel Attention Networks
Mar 22, 2021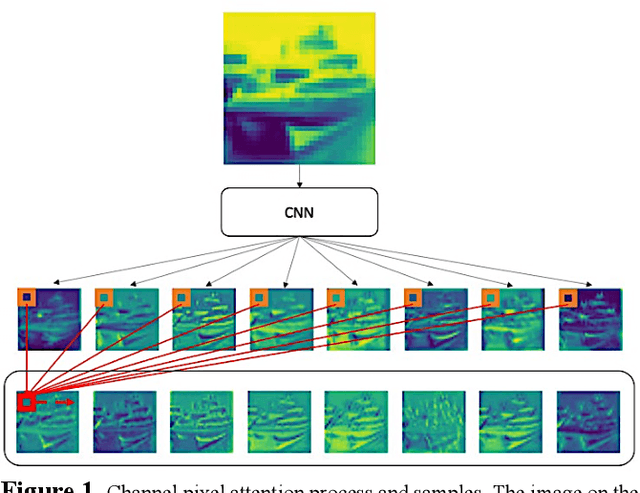
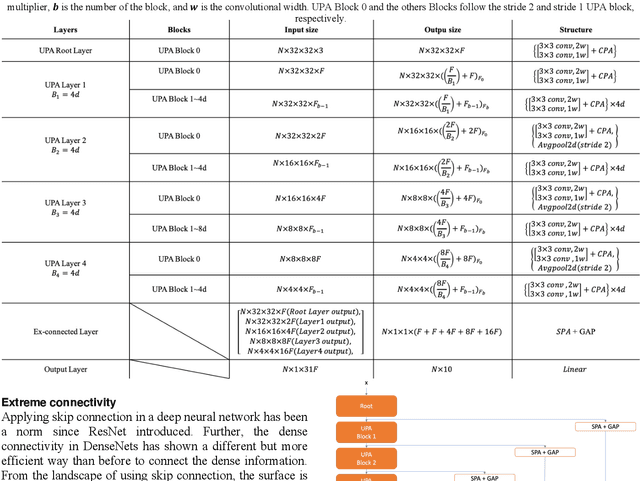
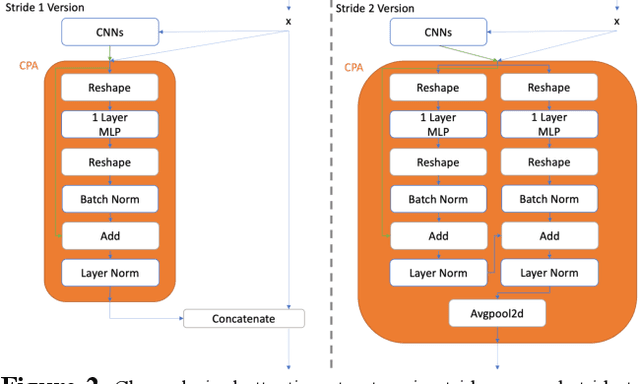
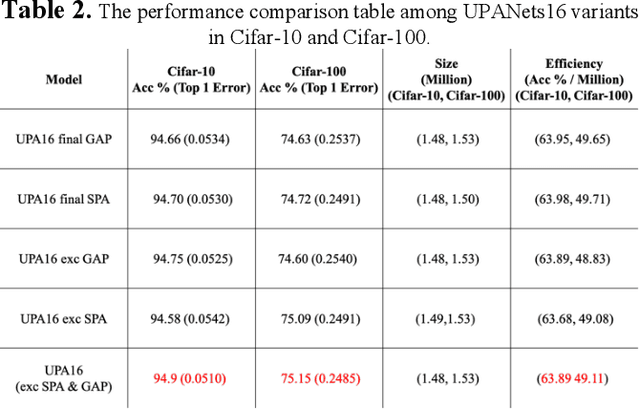
Among image classification, skip and densely-connection-based networks have dominated most leaderboards. Recently, from the successful development of multi-head attention in natural language processing, it is sure that now is a time of either using a Transformer-like model or hybrid CNNs with attention. However, the former need a tremendous resource to train, and the latter is in the perfect balance in this direction. In this work, to make CNNs handle global and local information, we proposed UPANets, which equips channel-wise attention with a hybrid skip-densely-connection structure. Also, the extreme-connection structure makes UPANets robust with a smoother loss landscape. In experiments, UPANets surpassed most well-known and widely-used SOTAs with an accuracy of 96.47% in Cifar-10, 80.29% in Cifar-100, and 67.67% in Tiny Imagenet. Most importantly, these performances have high parameters efficiency and only trained in one customer-based GPU. We share implementing code of UPANets in https://github.com/hanktseng131415go/UPANets.