 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$π_\texttt{RL}$: Online RL Fine-tuning for Flow-based Vision-Language-Action Models
Oct 29, 2025



Vision-Language-Action (VLA) models enable robots to understand and perform complex tasks from multimodal input. Although recent work explores using reinforcement learning (RL) to automate the laborious data collection process in scaling supervised fine-tuning (SFT), applying large-scale RL to flow-based VLAs (e.g., $\pi_0$, $\pi_{0.5}$) remains challenging due to intractable action log-likelihoods from iterative denoising. We address this challenge with $\pi_{\text{RL}}$, an open-source framework for training flow-based VLAs in parallel simulation. $\pi_{\text{RL}}$ implements two RL algorithms: (1) {Flow-Noise} models the denoising process as a discrete-time MDP with a learnable noise network for exact log-likelihood computation. (2) {Flow-SDE} integrates denoising with agent-environment interaction, formulating a two-layer MDP that employs ODE-to-SDE conversion for efficient RL exploration. We evaluate $\pi_{\text{RL}}$ on LIBERO and ManiSkill benchmarks. On LIBERO, $\pi_{\text{RL}}$ boosts few-shot SFT models $\pi_0$ and $\pi_{0.5}$ from 57.6% to 97.6% and from 77.1% to 98.3%, respectively. In ManiSkill, we train $\pi_{\text{RL}}$ in 320 parallel environments, improving $\pi_0$ from 41.6% to 85.7% and $\pi_{0.5}$ from 40.0% to 84.8% across 4352 pick-and-place tasks, demonstrating scalable multitask RL under heterogeneous simulation. Overall, $\pi_{\text{RL}}$ achieves significant performance gains and stronger generalization over SFT-models, validating the effectiveness of online RL for flow-based VLAs.
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Sep 19, 2025



Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker's adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving 1.1x-2.13x speedup in end-to-end training throughput.
SurfAAV: Design and Implementation of a Novel Multimodal Surfing Aquatic-Aerial Vehicle
Jun 18, 2025



Despite significant advancements in the research of aquatic-aerial robots, existing configurations struggle to efficiently perform underwater, surface, and aerial movement simultaneously. In this paper, we propose a novel multimodal surfing aquatic-aerial vehicle, SurfAAV, which efficiently integrates underwater navigation, surface gliding, and aerial flying capabilities. Thanks to the design of the novel differential thrust vectoring hydrofoil, SurfAAV can achieve efficient surface gliding and underwater navigation without the need for a buoyancy adjustment system. This design provides flexible operational capabilities for both surface and underwater tasks, enabling the robot to quickly carry out underwater monitoring activities. Additionally, when it is necessary to reach another water body, SurfAAV can switch to aerial mode through a gliding takeoff, flying to the target water area to perform corresponding tasks. The main contribution of this letter lies in proposing a new solution for underwater, surface, and aerial movement, designing a novel hybrid prototype concept, developing the required control laws, and validating the robot's ability to successfully perform surface gliding and gliding takeoff. SurfAAV achieves a maximum surface gliding speed of 7.96 m/s and a maximum underwater speed of 3.1 m/s. The prototype's surface gliding maneuverability and underwater cruising maneuverability both exceed those of existing aquatic-aerial vehicles.
RollingQ: Reviving the Cooperation Dynamics in Multimodal Transformer
Jun 13, 2025Multimodal learning faces challenges in effectively fusing information from diverse modalities, especially when modality quality varies across samples. Dynamic fusion strategies, such as attention mechanism in Transformers, aim to address such challenge by adaptively emphasizing modalities based on the characteristics of input data. However, through amounts of carefully designed experiments, we surprisingly observed that the dynamic adaptability of widely-used self-attention models diminishes. Model tends to prefer one modality regardless of data characteristics. This bias triggers a self-reinforcing cycle that progressively overemphasizes the favored modality, widening the distribution gap in attention keys across modalities and deactivating attention mechanism's dynamic properties. To revive adaptability, we propose a simple yet effective method Rolling Query (RollingQ), which balances attention allocation by rotating the query to break the self-reinforcing cycle and mitigate the key distribution gap. Extensive experiments on various multimodal scenarios validate the effectiveness of RollingQ and the restoration of cooperation dynamics is pivotal for enhancing the broader capabilities of widely deployed multimodal Transformers. The source code is available at https://github.com/GeWu-Lab/RollingQ_ICML2025.
GhostPrompt: Jailbreaking Text-to-image Generative Models based on Dynamic Optimization
May 25, 2025Text-to-image (T2I) generation models can inadvertently produce not-safe-for-work (NSFW) content, prompting the integration of text and image safety filters. Recent advances employ large language models (LLMs) for semantic-level detection, rendering traditional token-level perturbation attacks largely ineffective. However, our evaluation shows that existing jailbreak methods are ineffective against these modern filters. We introduce GhostPrompt, the first automated jailbreak framework that combines dynamic prompt optimization with multimodal feedback. It consists of two key components: (i) Dynamic Optimization, an iterative process that guides a large language model (LLM) using feedback from text safety filters and CLIP similarity scores to generate semantically aligned adversarial prompts; and (ii) Adaptive Safety Indicator Injection, which formulates the injection of benign visual cues as a reinforcement learning problem to bypass image-level filters. GhostPrompt achieves state-of-the-art performance, increasing the ShieldLM-7B bypass rate from 12.5\% (Sneakyprompt) to 99.0\%, improving CLIP score from 0.2637 to 0.2762, and reducing the time cost by $4.2 \times$. Moreover, it generalizes to unseen filters including GPT-4.1 and successfully jailbreaks DALLE 3 to generate NSFW images in our evaluation, revealing systemic vulnerabilities in current multimodal defenses. To support further research on AI safety and red-teaming, we will release code and adversarial prompts under a controlled-access protocol.
No Query, No Access
May 12, 2025Textual adversarial attacks mislead NLP models, including Large Language Models (LLMs), by subtly modifying text. While effective, existing attacks often require knowledge of the victim model, extensive queries, or access to training data, limiting real-world feasibility. To overcome these constraints, we introduce the \textbf{Victim Data-based Adversarial Attack (VDBA)}, which operates using only victim texts. To prevent access to the victim model, we create a shadow dataset with publicly available pre-trained models and clustering methods as a foundation for developing substitute models. To address the low attack success rate (ASR) due to insufficient information feedback, we propose the hierarchical substitution model design, generating substitute models to mitigate the failure of a single substitute model at the decision boundary. Concurrently, we use diverse adversarial example generation, employing various attack methods to generate and select the adversarial example with better similarity and attack effectiveness. Experiments on the Emotion and SST5 datasets show that VDBA outperforms state-of-the-art methods, achieving an ASR improvement of 52.08\% while significantly reducing attack queries to 0. More importantly, we discover that VDBA poses a significant threat to LLMs such as Qwen2 and the GPT family, and achieves the highest ASR of 45.99% even without access to the API, confirming that advanced NLP models still face serious security risks. Our codes can be found at https://anonymous.4open.science/r/VDBA-Victim-Data-based-Adversarial-Attack-36EC/
DriveAgent: Multi-Agent Structured Reasoning with LLM and Multimodal Sensor Fusion for Autonomous Driving
May 04, 2025
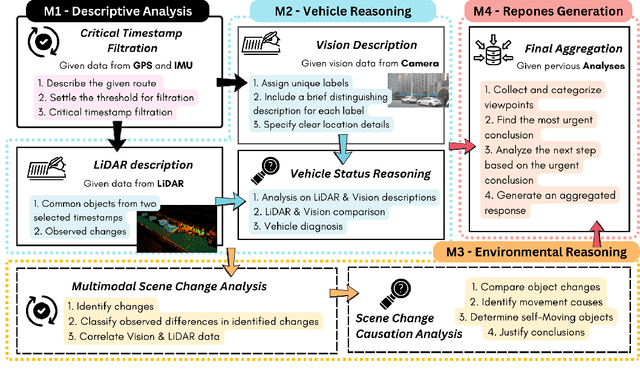
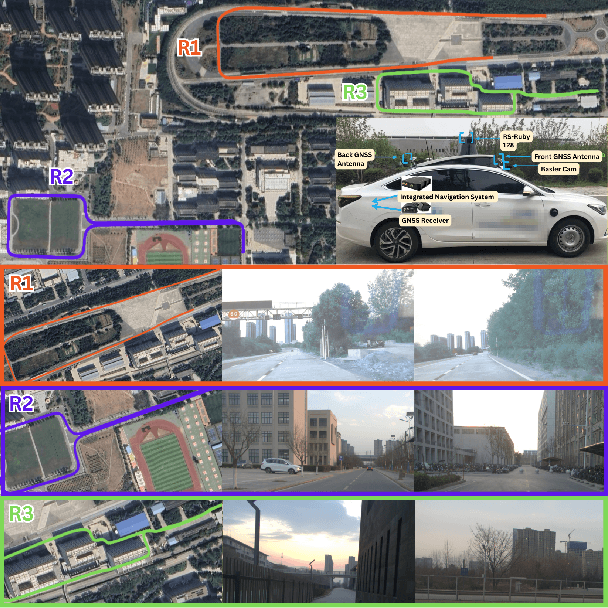
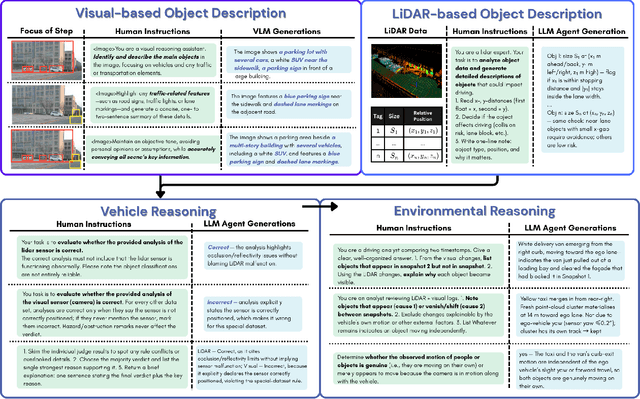
We introduce DriveAgent, a novel multi-agent autonomous driving framework that leverages large language model (LLM) reasoning combined with multimodal sensor fusion to enhance situational understanding and decision-making. DriveAgent uniquely integrates diverse sensor modalities-including camera, LiDAR, GPS, and IMU-with LLM-driven analytical processes structured across specialized agents. The framework operates through a modular agent-based pipeline comprising four principal modules: (i) a descriptive analysis agent identifying critical sensor data events based on filtered timestamps, (ii) dedicated vehicle-level analysis conducted by LiDAR and vision agents that collaboratively assess vehicle conditions and movements, (iii) environmental reasoning and causal analysis agents explaining contextual changes and their underlying mechanisms, and (iv) an urgency-aware decision-generation agent prioritizing insights and proposing timely maneuvers. This modular design empowers the LLM to effectively coordinate specialized perception and reasoning agents, delivering cohesive, interpretable insights into complex autonomous driving scenarios. Extensive experiments on challenging autonomous driving datasets demonstrate that DriveAgent is achieving superior performance on multiple metrics against baseline methods. These results validate the efficacy of the proposed LLM-driven multi-agent sensor fusion framework, underscoring its potential to substantially enhance the robustness and reliability of autonomous driving systems.
MEGA: Second-Order Gradient Alignment for Catastrophic Forgetting Mitigation in GFSCIL
Apr 18, 2025Graph Few-Shot Class-Incremental Learning (GFSCIL) enables models to continually learn from limited samples of novel tasks after initial training on a large base dataset. Existing GFSCIL approaches typically utilize Prototypical Networks (PNs) for metric-based class representations and fine-tune the model during the incremental learning stage. However, these PN-based methods oversimplify learning via novel query set fine-tuning and fail to integrate Graph Continual Learning (GCL) techniques due to architectural constraints. To address these challenges, we propose a more rigorous and practical setting for GFSCIL that excludes query sets during the incremental training phase. Building on this foundation, we introduce Model-Agnostic Meta Graph Continual Learning (MEGA), aimed at effectively alleviating catastrophic forgetting for GFSCIL. Specifically, by calculating the incremental second-order gradient during the meta-training stage, we endow the model to learn high-quality priors that enhance incremental learning by aligning its behaviors across both the meta-training and incremental learning stages. Extensive experiments on four mainstream graph datasets demonstrate that MEGA achieves state-of-the-art results and enhances the effectiveness of various GCL methods in GFSCIL. We believe that our proposed MEGA serves as a model-agnostic GFSCIL paradigm, paving the way for future research.
The Risks of Using Large Language Models for Text Annotation in Social Science Research
Mar 27, 2025



Generative artificial intelligence (GenAI) or large language models (LLMs) have the potential to revolutionize computational social science, particularly in automated textual analysis. In this paper, we conduct a systematic evaluation of the promises and risks of using LLMs for diverse coding tasks, with social movement studies serving as a case example. We propose a framework for social scientists to incorporate LLMs into text annotation, either as the primary coding decision-maker or as a coding assistant. This framework provides tools for researchers to develop the optimal prompt, and to examine and report the validity and reliability of LLMs as a methodological tool. Additionally, we discuss the associated epistemic risks related to validity, reliability, replicability, and transparency. We conclude with several practical guidelines for using LLMs in text annotation tasks, and how we can better communicate the epistemic risks in research.
Bridging Traffic State and Trajectory for Dynamic Road Network and Trajectory Representation Learning
Feb 08, 2025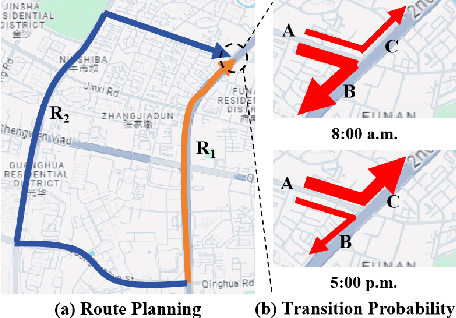

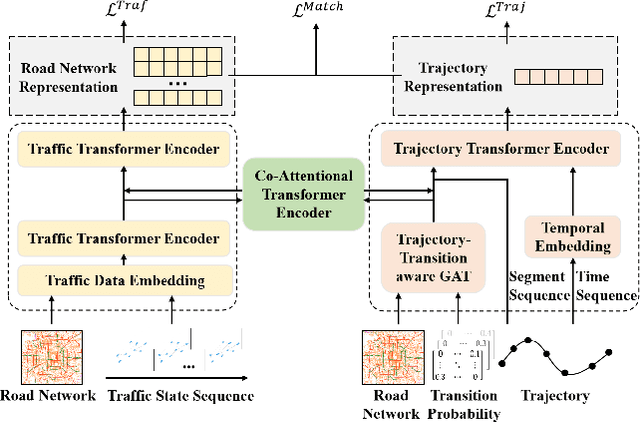
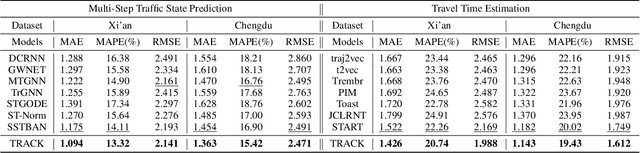
Effective urban traffic management is vital for sustainable city development, relying on intelligent systems with machine learning tasks such as traffic flow prediction and travel time estimation. Traditional approaches usually focus on static road network and trajectory representation learning, and overlook the dynamic nature of traffic states and trajectories, which is crucial for downstream tasks. To address this gap, we propose TRACK, a novel framework to bridge traffic state and trajectory data for dynamic road network and trajectory representation learning. TRACK leverages graph attention networks (GAT) to encode static and spatial road segment features, and introduces a transformer-based model for trajectory representation learning. By incorporating transition probabilities from trajectory data into GAT attention weights, TRACK captures dynamic spatial features of road segments. Meanwhile, TRACK designs a traffic transformer encoder to capture the spatial-temporal dynamics of road segments from traffic state data. To further enhance dynamic representations, TRACK proposes a co-attentional transformer encoder and a trajectory-traffic state matching task. Extensive experiments on real-life urban traffic datasets demonstrate the superiority of TRACK over state-of-the-art baselines. Case studies confirm TRACK's ability to capture spatial-temporal dynamics effectively.