 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Generated Image Detection using a Cross-Attention Enhanced Dual-Stream Network
Jun 12, 2023

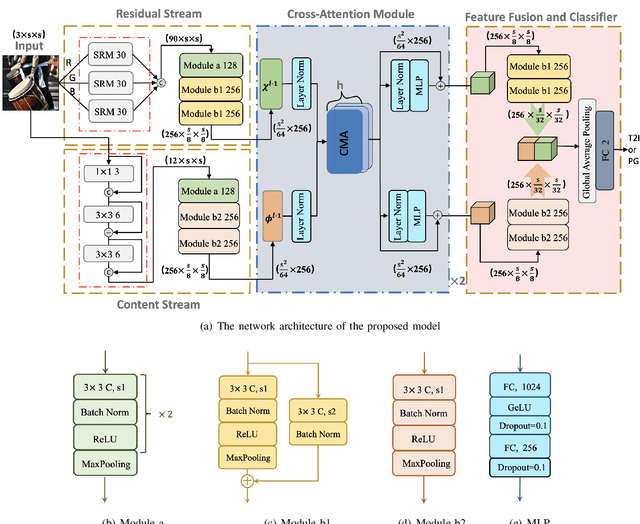

With the rapid evolution of AI Generated Content (AIGC), forged images produced through this technology are inherently more deceptive and require less human intervention compared to traditional Computer-generated Graphics (CG). However, owing to the disparities between CG and AIGC, conventional CG detection methods tend to be inadequate in identifying AIGC-produced images. To address this issue, our research concentrates on the text-to-image generation process in AIGC. Initially, we first assemble two text-to-image databases utilizing two distinct AI systems, DALLE2 and DreamStudio. Aiming to holistically capture the inherent anomalies produced by AIGC, we develope a robust dual-stream network comprised of a residual stream and a content stream. The former employs the Spatial Rich Model (SRM) to meticulously extract various texture information from images, while the latter seeks to capture additional forged traces in low frequency, thereby extracting complementary information that the residual stream may overlook. To enhance the information exchange between these two streams, we incorporate a cross multi-head attention mechanism. Numerous comparative experiments are performed on both databases, and the results show that our detection method consistently outperforms traditional CG detection techniques across a range of image resolutions. Moreover, our method exhibits superior performance through a series of robustness tests and cross-database experiments. When applied to widely recognized traditional CG benchmarks such as SPL2018 and DsTok, our approach significantly exceeds the capabilities of other existing methods in the field of CG detection.
Universal Deep Network for Steganalysis of Color Image based on Channel Representation
Nov 24, 2021Up to now, most existing steganalytic methods are designed for grayscale images, and they are not suitable for color images that are widely used in current social networks. In this paper, we design a universal color image steganalysis network (called UCNet) in spatial and JPEG domains. The proposed method includes preprocessing, convolutional, and classification modules. To preserve the steganographic artifacts in each color channel, in preprocessing module, we firstly separate the input image into three channels according to the corresponding embedding spaces (i.e. RGB for spatial steganography and YCbCr for JPEG steganography), and then extract the image residuals with 62 fixed high-pass filters, finally concatenate all truncated residuals for subsequent analysis rather than adding them together with normal convolution like existing CNN-based steganalyzers. To accelerate the network convergence and effectively reduce the number of parameters, in convolutional module, we carefully design three types of layers with different shortcut connections and group convolution structures to further learn high-level steganalytic features. In classification module, we employ a global average pooling and fully connected layer for classification. We conduct extensive experiments on ALASKA II to demonstrate that the proposed method can achieve state-of-the-art results compared with the modern CNN-based steganalyzers (e.g., SRNet and J-YeNet) in both spatial and JPEG domains, while keeping relatively few memory requirements and training time. Furthermore, we also provide necessary descriptions and many ablation experiments to verify the rationality of the network design.
Improved Xception with Dual Attention Mechanism and Feature Fusion for Face Forgery Detection
Sep 29, 2021
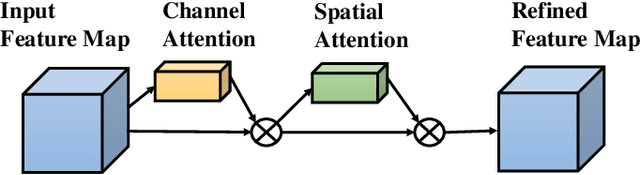

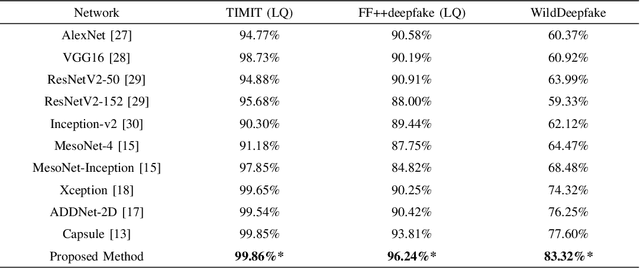
With the rapid development of deep learning technology, more and more face forgeries by deepfake are widely spread on social media, causing serious social concern. Face forgery detection has become a research hotspot in recent years, and many related methods have been proposed until now. For those images with low quality and/or diverse sources, however, the detection performances of existing methods are still far from satisfactory. In this paper, we propose an improved Xception with dual attention mechanism and feature fusion for face forgery detection. Different from the middle flow in original Xception model, we try to catch different high-semantic features of the face images using different levels of convolution, and introduce the convolutional block attention module and feature fusion to refine and reorganize those high-semantic features. In the exit flow, we employ the self-attention mechanism and depthwise separable convolution to learn the global information and local information of the fused features separately to improve the classification the ability of the proposed model. Experimental results evaluated on three Deepfake datasets demonstrate that the proposed method outperforms Xception as well as other related methods both in effectiveness and generalization ability.