 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Real-world Text Image Forgery Localization: Structured and Interpretable Data Synthesis
Nov 16, 2025Existing Text Image Forgery Localization (T-IFL) methods often suffer from poor generalization due to the limited scale of real-world datasets and the distribution gap caused by synthetic data that fails to capture the complexity of real-world tampering. To tackle this issue, we propose Fourier Series-based Tampering Synthesis (FSTS), a structured and interpretable framework for synthesizing tampered text images. FSTS first collects 16,750 real-world tampering instances from five representative tampering types, using a structured pipeline that records human-performed editing traces via multi-format logs (e.g., video, PSD, and editing logs). By analyzing these collected parameters and identifying recurring behavioral patterns at both individual and population levels, we formulate a hierarchical modeling framework. Specifically, each individual tampering parameter is represented as a compact combination of basis operation-parameter configurations, while the population-level distribution is constructed by aggregating these behaviors. Since this formulation draws inspiration from the Fourier series, it enables an interpretable approximation using basis functions and their learned weights. By sampling from this modeled distribution, FSTS synthesizes diverse and realistic training data that better reflect real-world forgery traces. Extensive experiments across four evaluation protocols demonstrate that models trained with FSTS data achieve significantly improved generalization on real-world datasets. Dataset is available at \href{https://github.com/ZeqinYu/FSTS}{Project Page}.
CLUE: Leveraging Low-Rank Adaptation to Capture Latent Uncovered Evidence for Image Forgery Localization
Aug 10, 2025The increasing accessibility of image editing tools and generative AI has led to a proliferation of visually convincing forgeries, compromising the authenticity of digital media. In this paper, in addition to leveraging distortions from conventional forgeries, we repurpose the mechanism of a state-of-the-art (SOTA) text-to-image synthesis model by exploiting its internal generative process, turning it into a high-fidelity forgery localization tool. To this end, we propose CLUE (Capture Latent Uncovered Evidence), a framework that employs Low- Rank Adaptation (LoRA) to parameter-efficiently reconfigure Stable Diffusion 3 (SD3) as a forensic feature extractor. Our approach begins with the strategic use of SD3's Rectified Flow (RF) mechanism to inject noise at varying intensities into the latent representation, thereby steering the LoRAtuned denoising process to amplify subtle statistical inconsistencies indicative of a forgery. To complement the latent analysis with high-level semantic context and precise spatial details, our method incorporates contextual features from the image encoder of the Segment Anything Model (SAM), which is parameter-efficiently adapted to better trace the boundaries of forged regions. Extensive evaluations demonstrate CLUE's SOTA generalization performance, significantly outperforming prior methods. Furthermore, CLUE shows superior robustness against common post-processing attacks and Online Social Networks (OSNs). Code is publicly available at https://github.com/SZAISEC/CLUE.
ForensicsSAM: Toward Robust and Unified Image Forgery Detection and Localization Resisting to Adversarial Attack
Aug 10, 2025Parameter-efficient fine-tuning (PEFT) has emerged as a popular strategy for adapting large vision foundation models, such as the Segment Anything Model (SAM) and LLaVA, to downstream tasks like image forgery detection and localization (IFDL). However, existing PEFT-based approaches overlook their vulnerability to adversarial attacks. In this paper, we show that highly transferable adversarial images can be crafted solely via the upstream model, without accessing the downstream model or training data, significantly degrading the IFDL performance. To address this, we propose ForensicsSAM, a unified IFDL framework with built-in adversarial robustness. Our design is guided by three key ideas: (1) To compensate for the lack of forgery-relevant knowledge in the frozen image encoder, we inject forgery experts into each transformer block to enhance its ability to capture forgery artifacts. These forgery experts are always activated and shared across any input images. (2) To detect adversarial images, we design an light-weight adversary detector that learns to capture structured, task-specific artifact in RGB domain, enabling reliable discrimination across various attack methods. (3) To resist adversarial attacks, we inject adversary experts into the global attention layers and MLP modules to progressively correct feature shifts induced by adversarial noise. These adversary experts are adaptively activated by the adversary detector, thereby avoiding unnecessary interference with clean images. Extensive experiments across multiple benchmarks demonstrate that ForensicsSAM achieves superior resistance to various adversarial attack methods, while also delivering state-of-the-art performance in image-level forgery detection and pixel-level forgery localization. The resource is available at https://github.com/siriusPRX/ForensicsSAM.
Active Adversarial Noise Suppression for Image Forgery Localization
Jun 15, 2025Recent advances in deep learning have significantly propelled the development of image forgery localization. However, existing models remain highly vulnerable to adversarial attacks: imperceptible noise added to forged images can severely mislead these models. In this paper, we address this challenge with an Adversarial Noise Suppression Module (ANSM) that generate a defensive perturbation to suppress the attack effect of adversarial noise. We observe that forgery-relevant features extracted from adversarial and original forged images exhibit distinct distributions. To bridge this gap, we introduce Forgery-relevant Features Alignment (FFA) as a first-stage training strategy, which reduces distributional discrepancies by minimizing the channel-wise Kullback-Leibler divergence between these features. To further refine the defensive perturbation, we design a second-stage training strategy, termed Mask-guided Refinement (MgR), which incorporates a dual-mask constraint. MgR ensures that the perturbation remains effective for both adversarial and original forged images, recovering forgery localization accuracy to their original level. Extensive experiments across various attack algorithms demonstrate that our method significantly restores the forgery localization model's performance on adversarial images. Notably, when ANSM is applied to original forged images, the performance remains nearly unaffected. To our best knowledge, this is the first report of adversarial defense in image forgery localization tasks. We have released the source code and anti-forensics dataset.
Prompt Engineering-assisted Malware Dynamic Analysis Using GPT-4
Dec 13, 2023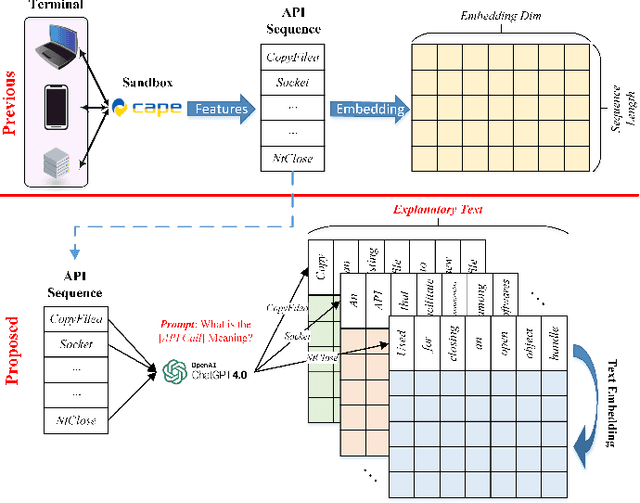
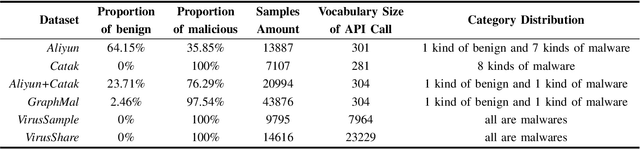
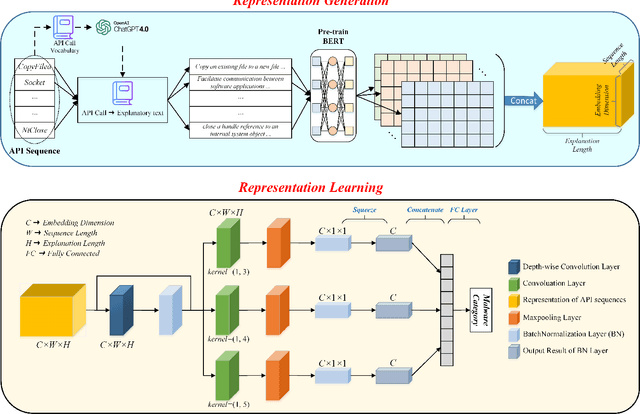
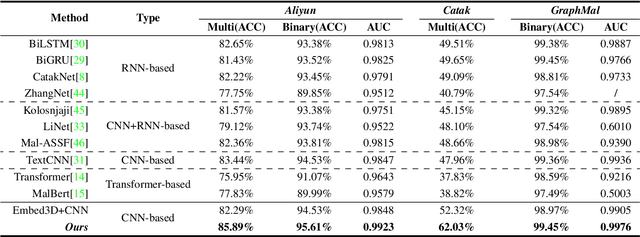
Dynamic analysis methods effectively identify shelled, wrapped, or obfuscated malware, thereby preventing them from invading computers. As a significant representation of dynamic malware behavior, the API (Application Programming Interface) sequence, comprised of consecutive API calls, has progressively become the dominant feature of dynamic analysis methods. Though there have been numerous deep learning models for malware detection based on API sequences, the quality of API call representations produced by those models is limited. These models cannot generate representations for unknown API calls, which weakens both the detection performance and the generalization. Further, the concept drift phenomenon of API calls is prominent. To tackle these issues, we introduce a prompt engineering-assisted malware dynamic analysis using GPT-4. In this method, GPT-4 is employed to create explanatory text for each API call within the API sequence. Afterward, the pre-trained language model BERT is used to obtain the representation of the text, from which we derive the representation of the API sequence. Theoretically, this proposed method is capable of generating representations for all API calls, excluding the necessity for dataset training during the generation process. Utilizing the representation, a CNN-based detection model is designed to extract the feature. We adopt five benchmark datasets to validate the performance of the proposed model. The experimental results reveal that the proposed detection algorithm performs better than the state-of-the-art method (TextCNN). Specifically, in cross-database experiments and few-shot learning experiments, the proposed model achieves excellent detection performance and almost a 100% recall rate for malware, verifying its superior generalization performance. The code is available at: github.com/yan-scnu/Prompted_Dynamic_Detection.
Evading Detection Actively: Toward Anti-Forensics against Forgery Localization
Oct 16, 2023
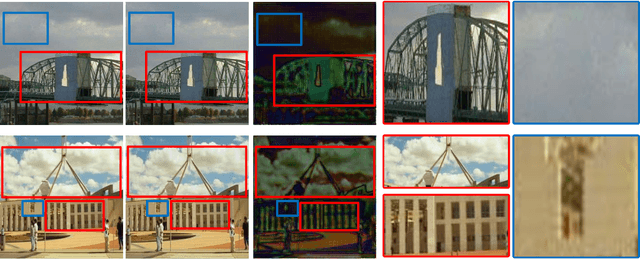
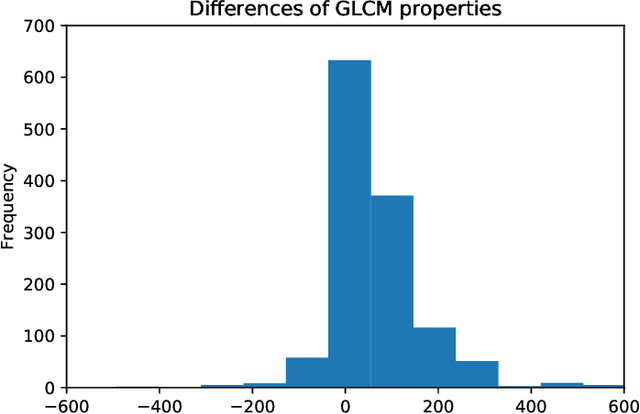

Anti-forensics seeks to eliminate or conceal traces of tampering artifacts. Typically, anti-forensic methods are designed to deceive binary detectors and persuade them to misjudge the authenticity of an image. However, to the best of our knowledge, no attempts have been made to deceive forgery detectors at the pixel level and mis-locate forged regions. Traditional adversarial attack methods cannot be directly used against forgery localization due to the following defects: 1) they tend to just naively induce the target forensic models to flip their pixel-level pristine or forged decisions; 2) their anti-forensics performance tends to be severely degraded when faced with the unseen forensic models; 3) they lose validity once the target forensic models are retrained with the anti-forensics images generated by them. To tackle the three defects, we propose SEAR (Self-supErvised Anti-foRensics), a novel self-supervised and adversarial training algorithm that effectively trains deep-learning anti-forensic models against forgery localization. SEAR sets a pretext task to reconstruct perturbation for self-supervised learning. In adversarial training, SEAR employs a forgery localization model as a supervisor to explore tampering features and constructs a deep-learning concealer to erase corresponding traces. We have conducted largescale experiments across diverse datasets. The experimental results demonstrate that, through the combination of self-supervised learning and adversarial learning, SEAR successfully deceives the state-of-the-art forgery localization methods, as well as tackle the three defects regarding traditional adversarial attack methods mentioned above.
Forgery-aware Adaptive Vision Transformer for Face Forgery Detection
Sep 20, 2023With the advancement in face manipulation technologies, the importance of face forgery detection in protecting authentication integrity becomes increasingly evident. Previous Vision Transformer (ViT)-based detectors have demonstrated subpar performance in cross-database evaluations, primarily because fully fine-tuning with limited Deepfake data often leads to forgetting pre-trained knowledge and over-fitting to data-specific ones. To circumvent these issues, we propose a novel Forgery-aware Adaptive Vision Transformer (FA-ViT). In FA-ViT, the vanilla ViT's parameters are frozen to preserve its pre-trained knowledge, while two specially designed components, the Local-aware Forgery Injector (LFI) and the Global-aware Forgery Adaptor (GFA), are employed to adapt forgery-related knowledge. our proposed FA-ViT effectively combines these two different types of knowledge to form the general forgery features for detecting Deepfakes. Specifically, LFI captures local discriminative information and incorporates these information into ViT via Neighborhood-Preserving Cross Attention (NPCA). Simultaneously, GFA learns adaptive knowledge in the self-attention layer, bridging the gap between the two different domain. Furthermore, we design a novel Single Domain Pairwise Learning (SDPL) to facilitate fine-grained information learning in FA-ViT. The extensive experiments demonstrate that our FA-ViT achieves state-of-the-art performance in cross-dataset evaluation and cross-manipulation scenarios, and improves the robustness against unseen perturbations.
Beyond the Prior Forgery Knowledge: Mining Critical Clues for General Face Forgery Detection
Apr 24, 2023Face forgery detection is essential in combating malicious digital face attacks. Previous methods mainly rely on prior expert knowledge to capture specific forgery clues, such as noise patterns, blending boundaries, and frequency artifacts. However, these methods tend to get trapped in local optima, resulting in limited robustness and generalization capability. To address these issues, we propose a novel Critical Forgery Mining (CFM) framework, which can be flexibly assembled with various backbones to boost their generalization and robustness performance. Specifically, we first build a fine-grained triplet and suppress specific forgery traces through prior knowledge-agnostic data augmentation. Subsequently, we propose a fine-grained relation learning prototype to mine critical information in forgeries through instance and local similarity-aware losses. Moreover, we design a novel progressive learning controller to guide the model to focus on principal feature components, enabling it to learn critical forgery features in a coarse-to-fine manner. The proposed method achieves state-of-the-art forgery detection performance under various challenging evaluation settings.
ReLoc: A Restoration-Assisted Framework for Robust Image Tampering Localization
Nov 08, 2022With the spread of tampered images, locating the tampered regions in digital images has drawn increasing attention. The existing image tampering localization methods, however, suffer from severe performance degradation when the tampered images are subjected to some post-processing, as the tampering traces would be distorted by the post-processing operations. The poor robustness against post-processing has become a bottleneck for the practical applications of image tampering localization techniques. In order to address this issue, this paper proposes a novel restoration-assisted framework for image tampering localization (ReLoc). The ReLoc framework mainly consists of an image restoration module and a tampering localization module. The key idea of ReLoc is to use the restoration module to recover a high-quality counterpart of the distorted tampered image, such that the distorted tampering traces can be re-enhanced, facilitating the tampering localization module to identify the tampered regions. To achieve this, the restoration module is optimized not only with the conventional constraints on image visual quality but also with a forensics-oriented objective function. Furthermore, the restoration module and the localization module are trained alternately, which can stabilize the training process and is beneficial for improving the performance. The proposed framework is evaluated by fighting against JPEG compression, the most commonly used post-processing. Extensive experimental results show that ReLoc can significantly improve the robustness against JPEG compression. The restoration module in a well-trained ReLoc model is transferable. Namely, it is still effective when being directly deployed with another tampering localization module.
Forensicability Assessment of Questioned Images in Recapturing Detection
Sep 05, 2022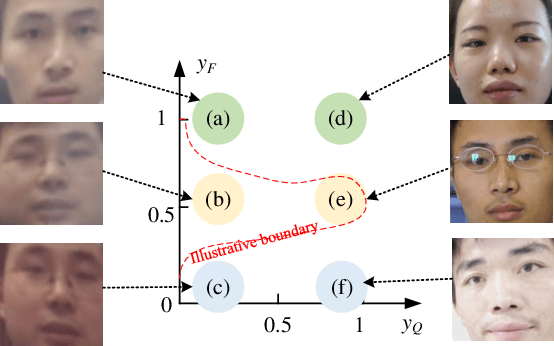

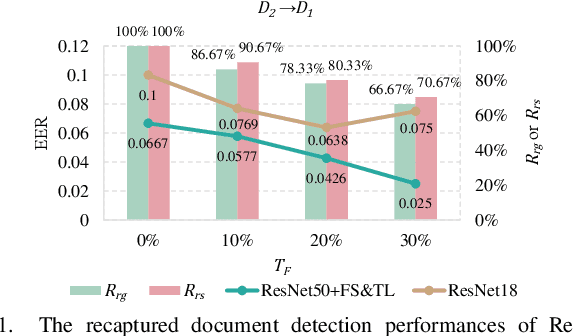
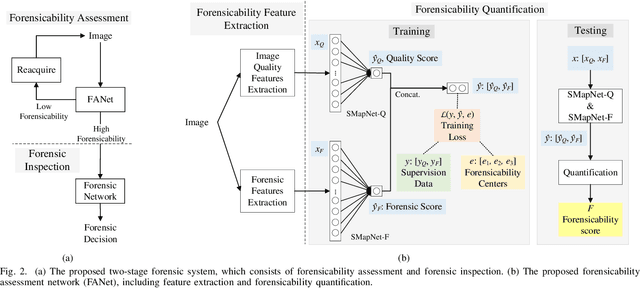
Recapture detection of face and document images is an important forensic task. With deep learning, the performances of face anti-spoofing (FAS) and recaptured document detection have been improved significantly. However, the performances are not yet satisfactory on samples with weak forensic cues. The amount of forensic cues can be quantified to allow a reliable forensic result. In this work, we propose a forensicability assessment network to quantify the forensicability of the questioned samples. The low-forensicability samples are rejected before the actual recapturing detection process to improve the efficiency of recapturing detection systems. We first extract forensicability features related to both image quality assessment and forensic tasks. By exploiting domain knowledge of the forensic application in image quality and forensic features, we define three task-specific forensicability classes and the initialized locations in the feature space. Based on the extracted features and the defined centers, we train the proposed forensic assessment network (FANet) with cross-entropy loss and update the centers with a momentum-based update method. We integrate the trained FANet with practical recapturing detection schemes in face anti-spoofing and recaptured document detection tasks. Experimental results show that, for a generic CNN-based FAS scheme, FANet reduces the EERs from 33.75% to 19.23% under ROSE to IDIAP protocol by rejecting samples with the lowest 30% forensicability scores. The performance of FAS schemes is poor in the rejected samples, with EER as high as 56.48%. Similar performances in rejecting low-forensicability samples have been observed for the state-of-the-art approaches in FAS and recaptured document detection tasks. To the best of our knowledge, this is the first work that assesses the forensicability of recaptured document images and improves the system efficiency.