 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Quality-Centric Framework for Generic Deepfake Detection
Nov 08, 2024



This paper addresses the generalization issue in deepfake detection by harnessing forgery quality in training data. Generally, the forgery quality of different deepfakes varies: some have easily recognizable forgery clues, while others are highly realistic. Existing works often train detectors on a mix of deepfakes with varying forgery qualities, potentially leading detectors to short-cut the easy-to-spot artifacts from low-quality forgery samples, thereby hurting generalization performance. To tackle this issue, we propose a novel quality-centric framework for generic deepfake detection, which is composed of a Quality Evaluator, a low-quality data enhancement module, and a learning pacing strategy that explicitly incorporates forgery quality into the training process. The framework is inspired by curriculum learning, which is designed to gradually enable the detector to learn more challenging deepfake samples, starting with easier samples and progressing to more realistic ones. We employ both static and dynamic assessments to assess the forgery quality, combining their scores to produce a final rating for each training sample. The rating score guides the selection of deepfake samples for training, with higher-rated samples having a higher probability of being chosen. Furthermore, we propose a novel frequency data augmentation method specifically designed for low-quality forgery samples, which helps to reduce obvious forgery traces and improve their overall realism. Extensive experiments show that our method can be applied in a plug-and-play manner and significantly enhance the generalization performance.
Multi-modal Document Presentation Attack Detection With Forensics Trace Disentanglement
Apr 10, 2024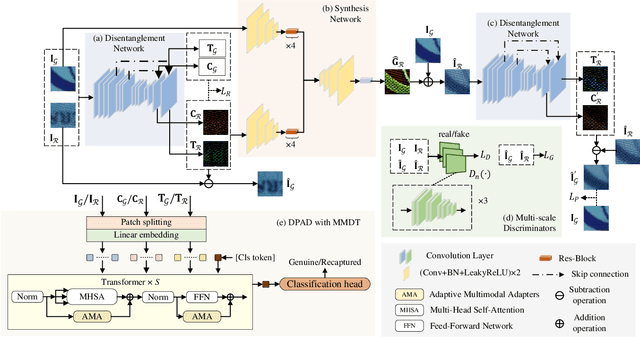
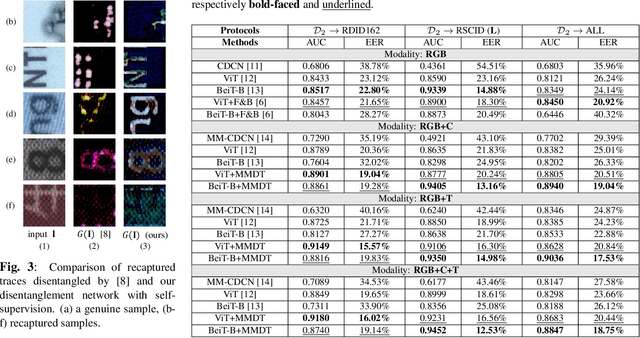
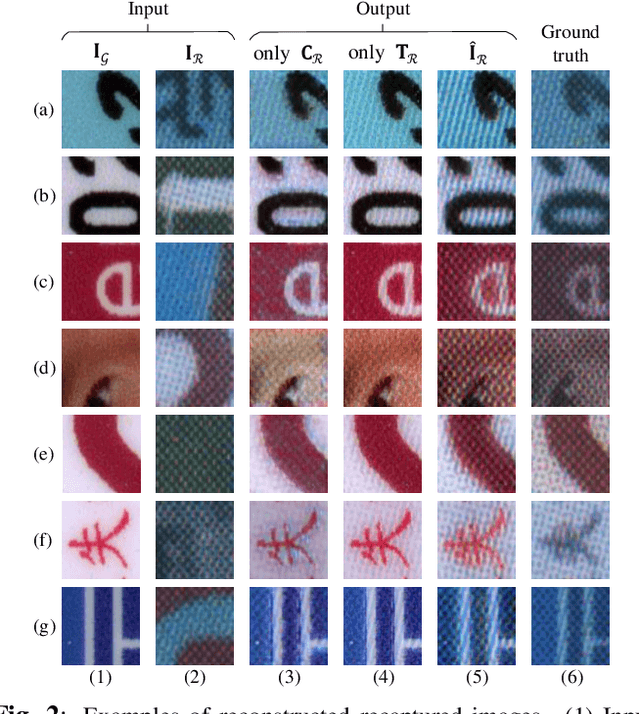

Document Presentation Attack Detection (DPAD) is an important measure in protecting the authenticity of a document image. However, recent DPAD methods demand additional resources, such as manual effort in collecting additional data or knowing the parameters of acquisition devices. This work proposes a DPAD method based on multi-modal disentangled traces (MMDT) without the above drawbacks. We first disentangle the recaptured traces by a self-supervised disentanglement and synthesis network to enhance the generalization capacity in document images with different contents and layouts. Then, unlike the existing DPAD approaches that rely only on data in the RGB domain, we propose to explicitly employ the disentangled recaptured traces as new modalities in the transformer backbone through adaptive multi-modal adapters to fuse RGB/trace features efficiently. Visualization of the disentangled traces confirms the effectiveness of the proposed method in different document contents. Extensive experiments on three benchmark datasets demonstrate the superiority of our MMDT method on representing forensic traces of recapturing distortion.
SHIELD : An Evaluation Benchmark for Face Spoofing and Forgery Detection with Multimodal Large Language Models
Feb 06, 2024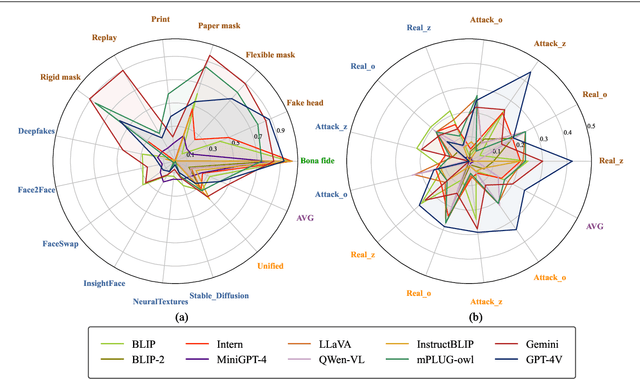
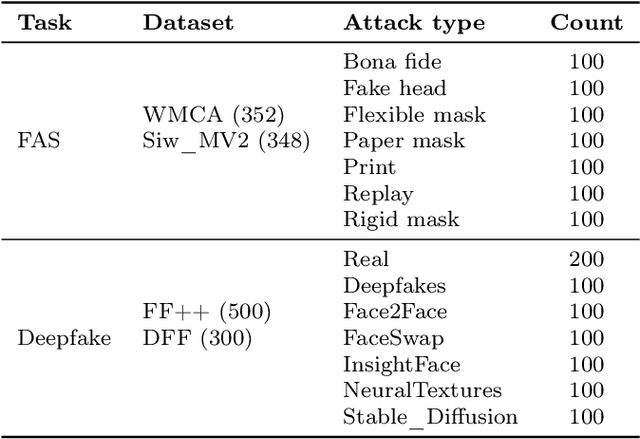

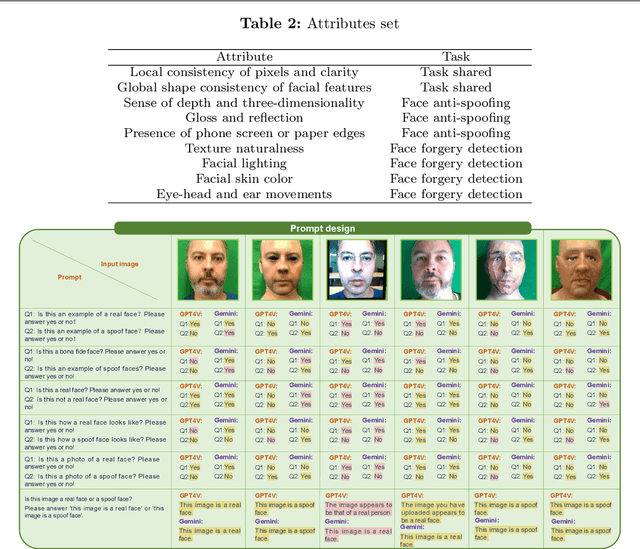
Multimodal large language models (MLLMs) have demonstrated remarkable problem-solving capabilities in various vision fields (e.g., generic object recognition and grounding) based on strong visual semantic representation and language reasoning ability. However, whether MLLMs are sensitive to subtle visual spoof/forged clues and how they perform in the domain of face attack detection (e.g., face spoofing and forgery detection) is still unexplored. In this paper, we introduce a new benchmark, namely SHIELD, to evaluate the ability of MLLMs on face spoofing and forgery detection. Specifically, we design true/false and multiple-choice questions to evaluate multimodal face data in these two face security tasks. For the face anti-spoofing task, we evaluate three different modalities (i.e., RGB, infrared, depth) under four types of presentation attacks (i.e., print attack, replay attack, rigid mask, paper mask). For the face forgery detection task, we evaluate GAN-based and diffusion-based data with both visual and acoustic modalities. Each question is subjected to both zero-shot and few-shot tests under standard and chain of thought (COT) settings. The results indicate that MLLMs hold substantial potential in the face security domain, offering advantages over traditional specific models in terms of interpretability, multimodal flexible reasoning, and joint face spoof and forgery detection. Additionally, we develop a novel Multi-Attribute Chain of Thought (MA-COT) paradigm for describing and judging various task-specific and task-irrelevant attributes of face images, which provides rich task-related knowledge for subtle spoof/forged clue mining. Extensive experiments in separate face anti-spoofing, separate face forgery detection, and joint detection tasks demonstrate the effectiveness of the proposed MA-COT. The project is available at https$:$//github.com/laiyingxin2/SHIELD
S-Adapter: Generalizing Vision Transformer for Face Anti-Spoofing with Statistical Tokens
Sep 07, 2023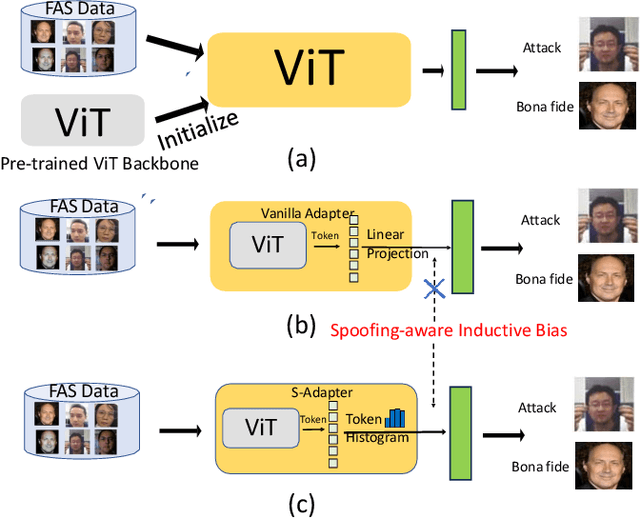
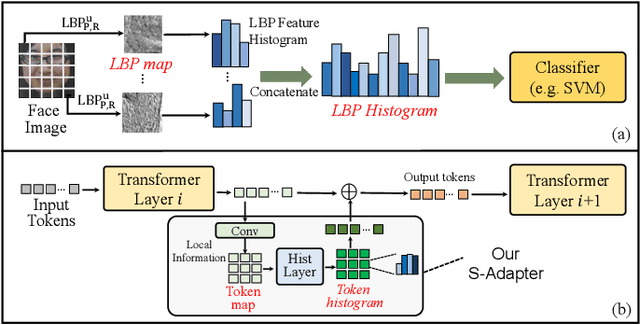
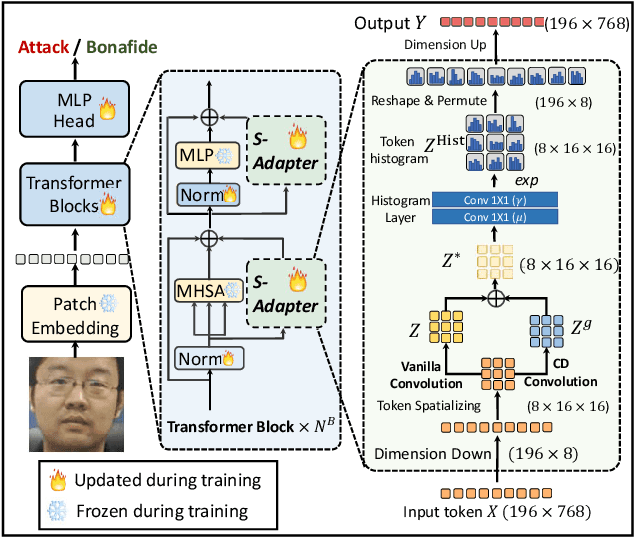
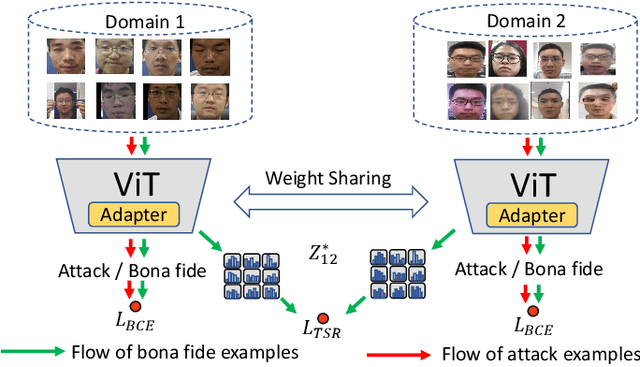
Face Anti-Spoofing (FAS) aims to detect malicious attempts to invade a face recognition system by presenting spoofed faces. State-of-the-art FAS techniques predominantly rely on deep learning models but their cross-domain generalization capabilities are often hindered by the domain shift problem, which arises due to different distributions between training and testing data. In this study, we develop a generalized FAS method under the Efficient Parameter Transfer Learning (EPTL) paradigm, where we adapt the pre-trained Vision Transformer models for the FAS task. During training, the adapter modules are inserted into the pre-trained ViT model, and the adapters are updated while other pre-trained parameters remain fixed. We find the limitations of previous vanilla adapters in that they are based on linear layers, which lack a spoofing-aware inductive bias and thus restrict the cross-domain generalization. To address this limitation and achieve cross-domain generalized FAS, we propose a novel Statistical Adapter (S-Adapter) that gathers local discriminative and statistical information from localized token histograms. To further improve the generalization of the statistical tokens, we propose a novel Token Style Regularization (TSR), which aims to reduce domain style variance by regularizing Gram matrices extracted from tokens across different domains. Our experimental results demonstrate that our proposed S-Adapter and TSR provide significant benefits in both zero-shot and few-shot cross-domain testing, outperforming state-of-the-art methods on several benchmark tests. We will release the source code upon acceptance.
Image Copy-Move Forgery Detection via Deep Cross-Scale PatchMatch
Aug 08, 2023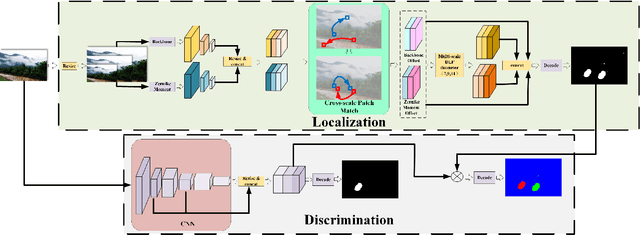
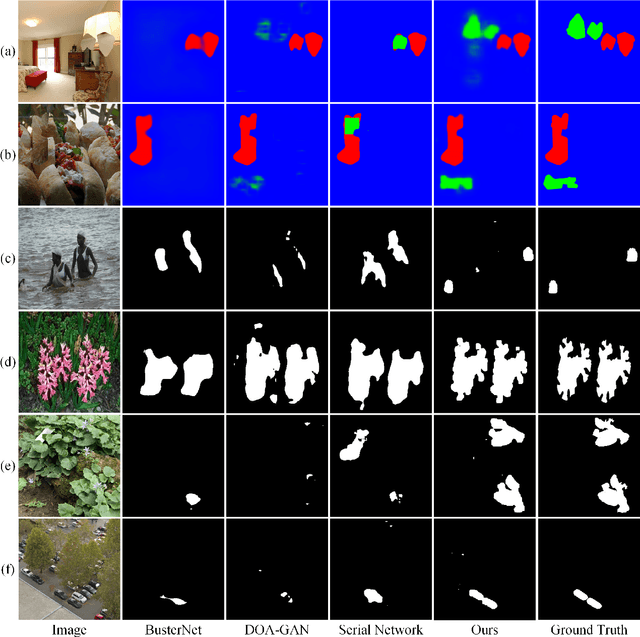
The recently developed deep algorithms achieve promising progress in the field of image copy-move forgery detection (CMFD). However, they have limited generalizability in some practical scenarios, where the copy-move objects may not appear in the training images or cloned regions are from the background. To address the above issues, in this work, we propose a novel end-to-end CMFD framework by integrating merits from both conventional and deep methods. Specifically, we design a deep cross-scale patchmatch method tailored for CMFD to localize copy-move regions. In contrast to existing deep models, our scheme aims to seek explicit and reliable point-to-point matching between source and target regions using features extracted from high-resolution scales. Further, we develop a manipulation region location branch for source/target separation. The proposed CMFD framework is completely differentiable and can be trained in an end-to-end manner. Extensive experimental results demonstrate the high generalizability of our method to different copy-move contents, and the proposed scheme achieves significantly better performance than existing approaches.
Visual Prompt Flexible-Modal Face Anti-Spoofing
Jul 26, 2023Recently, vision transformer based multimodal learning methods have been proposed to improve the robustness of face anti-spoofing (FAS) systems. However, multimodal face data collected from the real world is often imperfect due to missing modalities from various imaging sensors. Recently, flexible-modal FAS~\cite{yu2023flexible} has attracted more attention, which aims to develop a unified multimodal FAS model using complete multimodal face data but is insensitive to test-time missing modalities. In this paper, we tackle one main challenge in flexible-modal FAS, i.e., when missing modality occurs either during training or testing in real-world situations. Inspired by the recent success of the prompt learning in language models, we propose \textbf{V}isual \textbf{P}rompt flexible-modal \textbf{FAS} (VP-FAS), which learns the modal-relevant prompts to adapt the frozen pre-trained foundation model to downstream flexible-modal FAS task. Specifically, both vanilla visual prompts and residual contextual prompts are plugged into multimodal transformers to handle general missing-modality cases, while only requiring less than 4\% learnable parameters compared to training the entire model. Furthermore, missing-modality regularization is proposed to force models to learn consistent multimodal feature embeddings when missing partial modalities. Extensive experiments conducted on two multimodal FAS benchmark datasets demonstrate the effectiveness of our VP-FAS framework that improves the performance under various missing-modality cases while alleviating the requirement of heavy model re-training.
Forensicability Assessment of Questioned Images in Recapturing Detection
Sep 05, 2022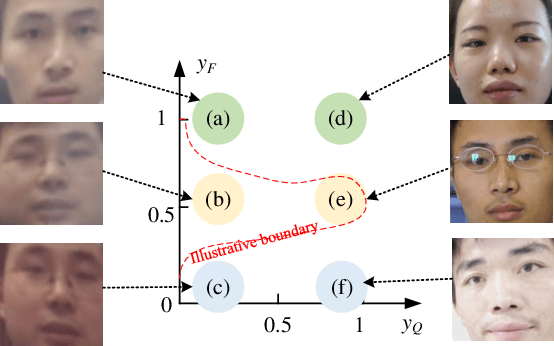

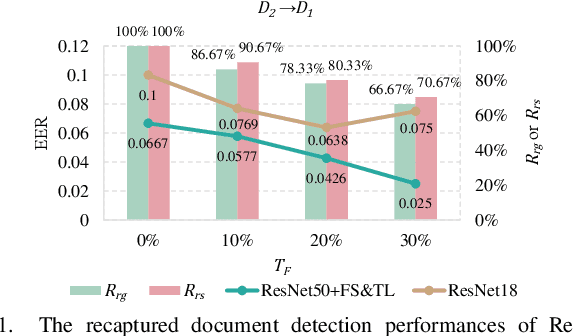
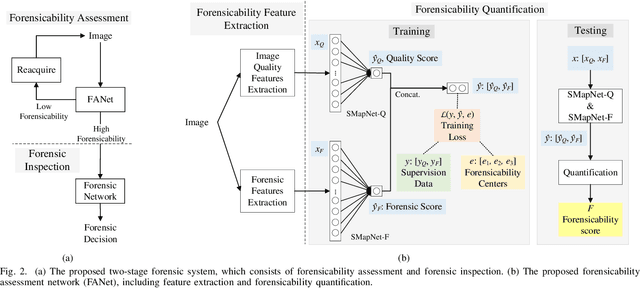
Recapture detection of face and document images is an important forensic task. With deep learning, the performances of face anti-spoofing (FAS) and recaptured document detection have been improved significantly. However, the performances are not yet satisfactory on samples with weak forensic cues. The amount of forensic cues can be quantified to allow a reliable forensic result. In this work, we propose a forensicability assessment network to quantify the forensicability of the questioned samples. The low-forensicability samples are rejected before the actual recapturing detection process to improve the efficiency of recapturing detection systems. We first extract forensicability features related to both image quality assessment and forensic tasks. By exploiting domain knowledge of the forensic application in image quality and forensic features, we define three task-specific forensicability classes and the initialized locations in the feature space. Based on the extracted features and the defined centers, we train the proposed forensic assessment network (FANet) with cross-entropy loss and update the centers with a momentum-based update method. We integrate the trained FANet with practical recapturing detection schemes in face anti-spoofing and recaptured document detection tasks. Experimental results show that, for a generic CNN-based FAS scheme, FANet reduces the EERs from 33.75% to 19.23% under ROSE to IDIAP protocol by rejecting samples with the lowest 30% forensicability scores. The performance of FAS schemes is poor in the rejected samples, with EER as high as 56.48%. Similar performances in rejecting low-forensicability samples have been observed for the state-of-the-art approaches in FAS and recaptured document detection tasks. To the best of our knowledge, this is the first work that assesses the forensicability of recaptured document images and improves the system efficiency.
DRL-FAS: A Novel Framework Based on Deep Reinforcement Learning for Face Anti-Spoofing
Sep 18, 2020
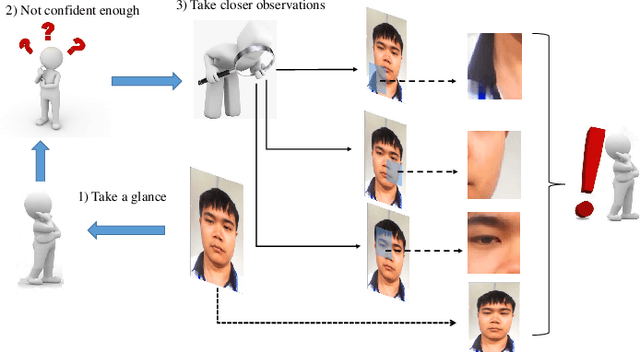
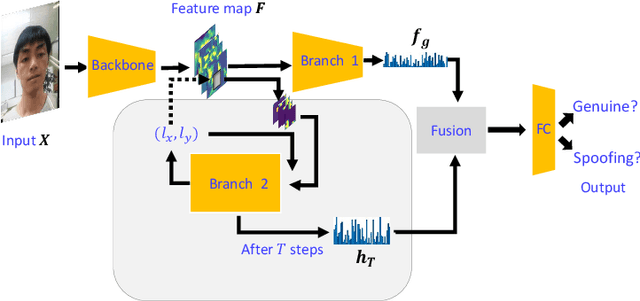
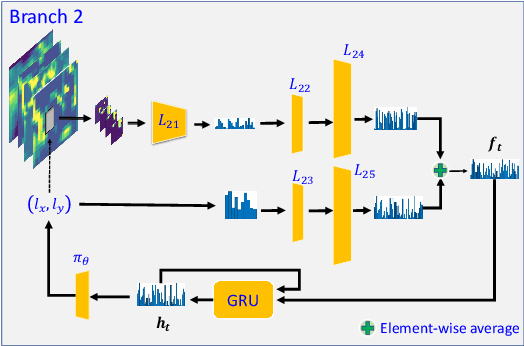
Inspired by the philosophy employed by human beings to determine whether a presented face example is genuine or not, i.e., to glance at the example globally first and then carefully observe the local regions to gain more discriminative information, for the face anti-spoofing problem, we propose a novel framework based on the Convolutional Neural Network (CNN) and the Recurrent Neural Network (RNN). In particular, we model the behavior of exploring face-spoofing-related information from image sub-patches by leveraging deep reinforcement learning. We further introduce a recurrent mechanism to learn representations of local information sequentially from the explored sub-patches with an RNN. Finally, for the classification purpose, we fuse the local information with the global one, which can be learned from the original input image through a CNN. Moreover, we conduct extensive experiments, including ablation study and visualization analysis, to evaluate our proposed framework on various public databases. The experiment results show that our method can generally achieve state-of-the-art performance among all scenarios, demonstrating its effectiveness.
Detection of Information Hiding at Anti-Copying 2D Barcodes
Mar 20, 2020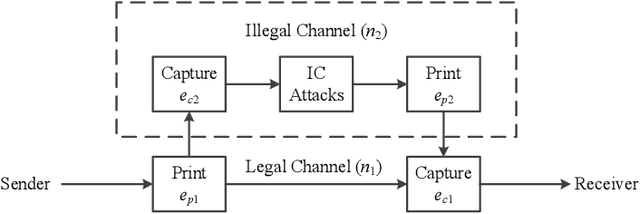
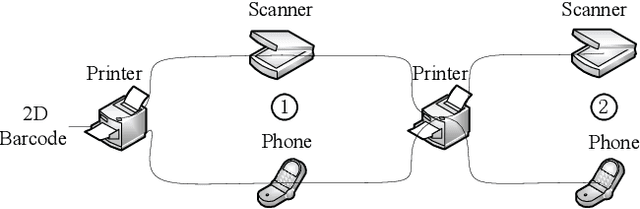
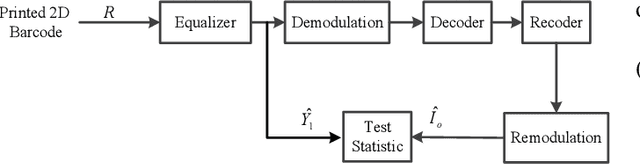
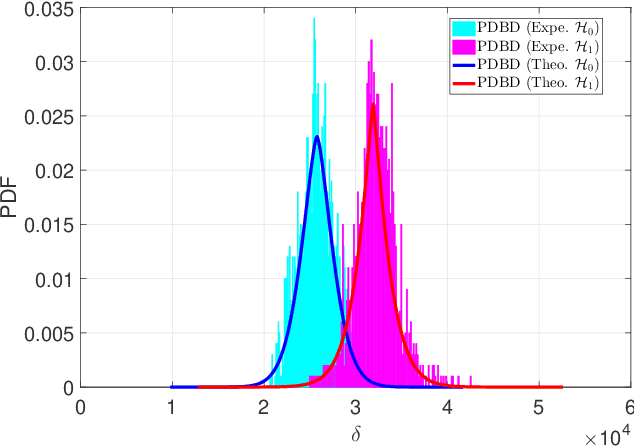
This paper concerns the problem of detecting the use of information hiding at anti-copying 2D barcodes. Prior hidden information detection schemes are either heuristicbased or Machine Learning (ML) based. The key limitation of prior heuristics-based schemes is that they do not answer the fundamental question of why the information hidden at a 2D barcode can be detected. The key limitation of prior MLbased information schemes is that they lack robustness because a printed 2D barcode is very much environmentally dependent, and thus an information hiding detection scheme trained in one environment often does not work well in another environment. In this paper, we propose two hidden information detection schemes at the existing anti-copying 2D barcodes. The first scheme is to directly use the pixel distance to detect the use of an information hiding scheme in a 2D barcode, referred as to the Pixel Distance Based Detection (PDBD) scheme. The second scheme is first to calculate the variance of the raw signal and the covariance between the recovered signal and the raw signal, and then based on the variance results, detects the use of information hiding scheme in a 2D barcode, referred as to the Pixel Variance Based Detection (PVBD) scheme. Moreover, we design advanced IC attacks to evaluate the security of two existing anti-copying 2D barcodes. We implemented our schemes and conducted extensive performance comparison between our schemes and prior schemes under different capturing devices, such as a scanner and a camera phone. Our experimental results show that the PVBD scheme can correctly detect the existence of the hidden information at both the 2LQR code and the LCAC 2D barcode. Moreover, the probability of successfully attacking of our IC attacks achieves 0.6538 for the 2LQR code and 1 for the LCAC 2D barcode.
Learning deep forest with multi-scale Local Binary Pattern features for face anti-spoofing
Oct 09, 2019
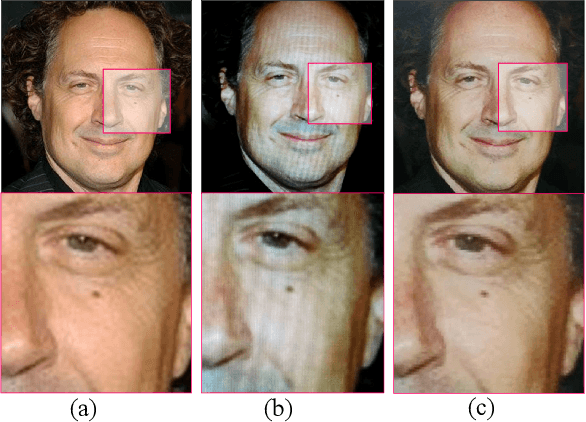
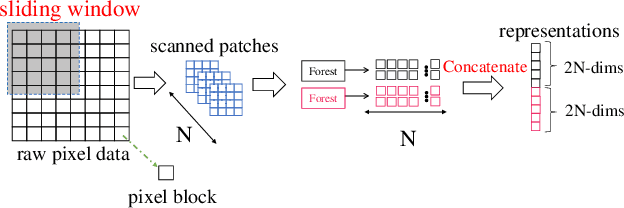
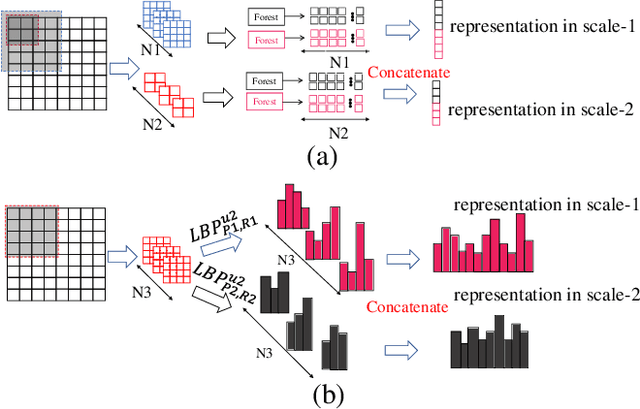
Face Anti-Spoofing (FAS) is significant for the security of face recognition systems. Convolutional Neural Networks (CNNs) have been introduced to the field of the FAS and have achieved competitive performance. However, CNN-based methods are vulnerable to the adversarial attack. Attackers could generate adversarial-spoofing examples to circumvent a CNN-based face liveness detector. Studies about the transferability of the adversarial attack reveal that utilizing handcrafted feature-based methods could improve security in a system-level. Therefore, handcrafted feature-based methods are worth our exploration. In this paper, we introduce the deep forest, which is proposed as an alternative towards CNNs by Zhou et al., in the problem of the FAS. To the best of our knowledge, this is the first attempt at exploiting the deep forest in the problem of FAS. Moreover, we propose to re-devise the representation constructing by using LBP descriptors rather than the Grained-Scanning Mechanism in the original scheme. Our method achieves competitive results. On the benchmark database IDIAP REPLAY-ATTACK, 0\% Equal Error Rate (EER) is achieved. This work provides a competitive option in a fusing scheme for improving system-level security and offers important ideas to those who want to explore methods besides CNNs.