 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffuGR: Generative Document Retrieval with Diffusion Language Models
Nov 19, 2025Generative retrieval (GR) re-frames document retrieval as a sequence-based document identifier (DocID) generation task, memorizing documents with model parameters and enabling end-to-end retrieval without explicit indexing. Existing GR methods are based on auto-regressive generative models, i.e., the token generation is performed from left to right. However, such auto-regressive methods suffer from: (1) mismatch between DocID generation and natural language generation, e.g., an incorrect DocID token generated in early left steps would lead to totally erroneous retrieval; and (2) failure to balance the trade-off between retrieval efficiency and accuracy dynamically, which is crucial for practical applications. To address these limitations, we propose generative document retrieval with diffusion language models, dubbed DiffuGR. It models DocID generation as a discrete diffusion process: during training, DocIDs are corrupted through a stochastic masking process, and a diffusion language model is learned to recover them under a retrieval-aware objective. For inference, DiffuGR attempts to generate DocID tokens in parallel and refines them through a controllable number of denoising steps. In contrast to conventional left-to-right auto-regressive decoding, DiffuGR provides a novel mechanism to first generate more confident DocID tokens and refine the generation through diffusion-based denoising. Moreover, DiffuGR also offers explicit runtime control over the qualitylatency tradeoff. Extensive experiments on benchmark retrieval datasets show that DiffuGR is competitive with strong auto-regressive generative retrievers, while offering flexible speed and accuracy tradeoffs through variable denoising budgets. Overall, our results indicate that non-autoregressive diffusion models are a practical and effective alternative for generative document retrieval.
TABNet: A Triplet Augmentation Self-Recovery Framework with Boundary-Aware Pseudo-Labels for Medical Image Segmentation
Jul 03, 2025Background and objective: Medical image segmentation is a core task in various clinical applications. However, acquiring large-scale, fully annotated medical image datasets is both time-consuming and costly. Scribble annotations, as a form of sparse labeling, provide an efficient and cost-effective alternative for medical image segmentation. However, the sparsity of scribble annotations limits the feature learning of the target region and lacks sufficient boundary supervision, which poses significant challenges for training segmentation networks. Methods: We propose TAB Net, a novel weakly-supervised medical image segmentation framework, consisting of two key components: the triplet augmentation self-recovery (TAS) module and the boundary-aware pseudo-label supervision (BAP) module. The TAS module enhances feature learning through three complementary augmentation strategies: intensity transformation improves the model's sensitivity to texture and contrast variations, cutout forces the network to capture local anatomical structures by masking key regions, and jigsaw augmentation strengthens the modeling of global anatomical layout by disrupting spatial continuity. By guiding the network to recover complete masks from diverse augmented inputs, TAS promotes a deeper semantic understanding of medical images under sparse supervision. The BAP module enhances pseudo-supervision accuracy and boundary modeling by fusing dual-branch predictions into a loss-weighted pseudo-label and introducing a boundary-aware loss for fine-grained contour refinement. Results: Experimental evaluations on two public datasets, ACDC and MSCMR seg, demonstrate that TAB Net significantly outperforms state-of-the-art methods for scribble-based weakly supervised segmentation. Moreover, it achieves performance comparable to that of fully supervised methods.
FaceShield: Explainable Face Anti-Spoofing with Multimodal Large Language Models
May 14, 2025
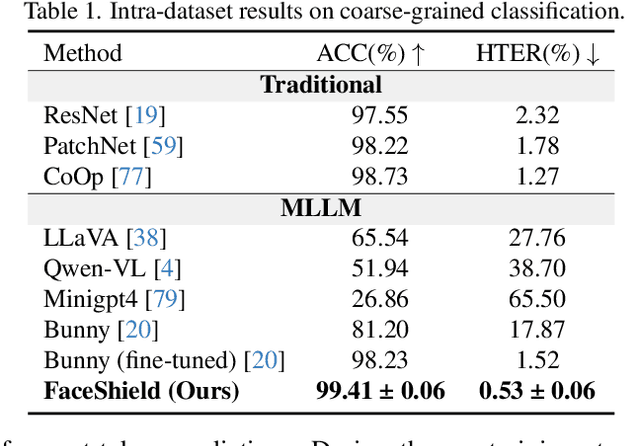
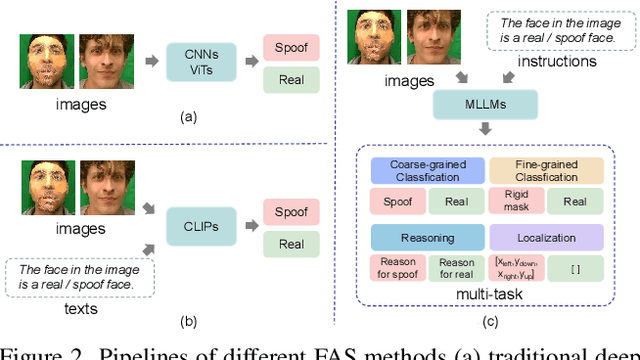
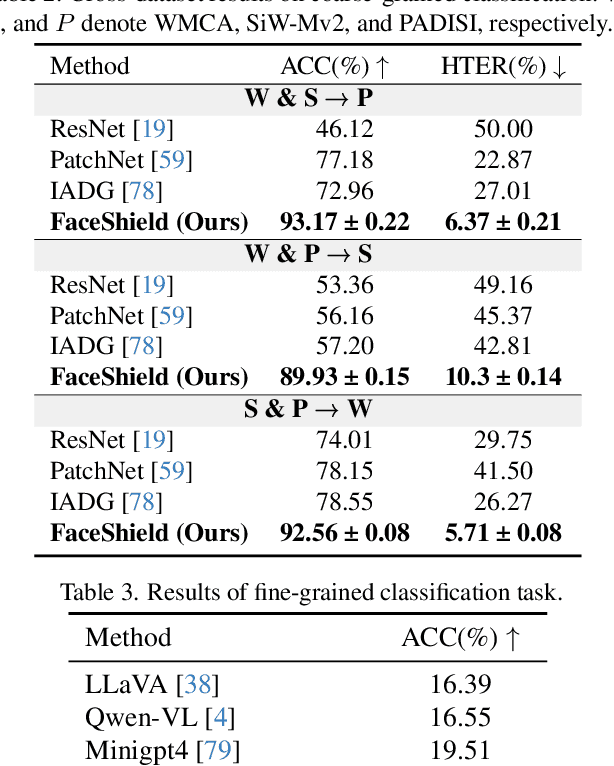
Face anti-spoofing (FAS) is crucial for protecting facial recognition systems from presentation attacks. Previous methods approached this task as a classification problem, lacking interpretability and reasoning behind the predicted results. Recently, multimodal large language models (MLLMs) have shown strong capabilities in perception, reasoning, and decision-making in visual tasks. However, there is currently no universal and comprehensive MLLM and dataset specifically designed for FAS task. To address this gap, we propose FaceShield, a MLLM for FAS, along with the corresponding pre-training and supervised fine-tuning (SFT) datasets, FaceShield-pre10K and FaceShield-sft45K. FaceShield is capable of determining the authenticity of faces, identifying types of spoofing attacks, providing reasoning for its judgments, and detecting attack areas. Specifically, we employ spoof-aware vision perception (SAVP) that incorporates both the original image and auxiliary information based on prior knowledge. We then use an prompt-guided vision token masking (PVTM) strategy to random mask vision tokens, thereby improving the model's generalization ability. We conducted extensive experiments on three benchmark datasets, demonstrating that FaceShield significantly outperforms previous deep learning models and general MLLMs on four FAS tasks, i.e., coarse-grained classification, fine-grained classification, reasoning, and attack localization. Our instruction datasets, protocols, and codes will be released soon.
HELPNet: Hierarchical Perturbations Consistency and Entropy-guided Ensemble for Scribble Supervised Medical Image Segmentation
Dec 25, 2024



Creating fully annotated labels for medical image segmentation is prohibitively time-intensive and costly, emphasizing the necessity for innovative approaches that minimize reliance on detailed annotations. Scribble annotations offer a more cost-effective alternative, significantly reducing the expenses associated with full annotations. However, scribble annotations offer limited and imprecise information, failing to capture the detailed structural and boundary characteristics necessary for accurate organ delineation. To address these challenges, we propose HELPNet, a novel scribble-based weakly supervised segmentation framework, designed to bridge the gap between annotation efficiency and segmentation performance. HELPNet integrates three modules. The Hierarchical perturbations consistency (HPC) module enhances feature learning by employing density-controlled jigsaw perturbations across global, local, and focal views, enabling robust modeling of multi-scale structural representations. Building on this, the Entropy-guided pseudo-label (EGPL) module evaluates the confidence of segmentation predictions using entropy, generating high-quality pseudo-labels. Finally, the structural prior refinement (SPR) module incorporates connectivity and bounded priors to enhance the precision and reliability and pseudo-labels. Experimental results on three public datasets ACDC, MSCMRseg, and CHAOS show that HELPNet significantly outperforms state-of-the-art methods for scribble-based weakly supervised segmentation and achieves performance comparable to fully supervised methods. The code is available at https://github.com/IPMI-NWU/HELPNet.
APS-LSTM: Exploiting Multi-Periodicity and Diverse Spatial Dependencies for Flood Forecasting
Dec 07, 2024Accurate flood prediction is crucial for disaster prevention and mitigation. Hydrological data exhibit highly nonlinear temporal patterns and encompass complex spatial relationships between rainfall and flow. Existing flood prediction models struggle to capture these intricate temporal features and spatial dependencies. This paper presents an adaptive periodic and spatial self-attention method based on LSTM (APS-LSTM) to address these challenges. The APS-LSTM learns temporal features from a multi-periodicity perspective and captures diverse spatial dependencies from different period divisions. The APS-LSTM consists of three main stages, (i) Multi-Period Division, that utilizes Fast Fourier Transform (FFT) to divide various periodic patterns; (ii) Spatio-Temporal Information Extraction, that performs periodic and spatial self-attention focusing on intra- and inter-periodic temporal patterns and spatial dependencies; (iii) Adaptive Aggregation, that relies on amplitude strength to aggregate the computational results from each periodic division. The abundant experiments on two real-world datasets demonstrate the superiority of APS-LSTM. The code is available: https://github.com/oopcmd/APS-LSTM.
Gaze-directed Vision GNN for Mitigating Shortcut Learning in Medical Image
Jun 20, 2024



Deep neural networks have demonstrated remarkable performance in medical image analysis. However, its susceptibility to spurious correlations due to shortcut learning raises concerns about network interpretability and reliability. Furthermore, shortcut learning is exacerbated in medical contexts where disease indicators are often subtle and sparse. In this paper, we propose a novel gaze-directed Vision GNN (called GD-ViG) to leverage the visual patterns of radiologists from gaze as expert knowledge, directing the network toward disease-relevant regions, and thereby mitigating shortcut learning. GD-ViG consists of a gaze map generator (GMG) and a gaze-directed classifier (GDC). Combining the global modelling ability of GNNs with the locality of CNNs, GMG generates the gaze map based on radiologists' visual patterns. Notably, it eliminates the need for real gaze data during inference, enhancing the network's practical applicability. Utilizing gaze as the expert knowledge, the GDC directs the construction of graph structures by incorporating both feature distances and gaze distances, enabling the network to focus on disease-relevant foregrounds. Thereby avoiding shortcut learning and improving the network's interpretability. The experiments on two public medical image datasets demonstrate that GD-ViG outperforms the state-of-the-art methods, and effectively mitigates shortcut learning. Our code is available at https://github.com/SX-SS/GD-ViG.
Prompt-Guided Generation of Structured Chest X-Ray Report Using a Pre-trained LLM
Apr 17, 2024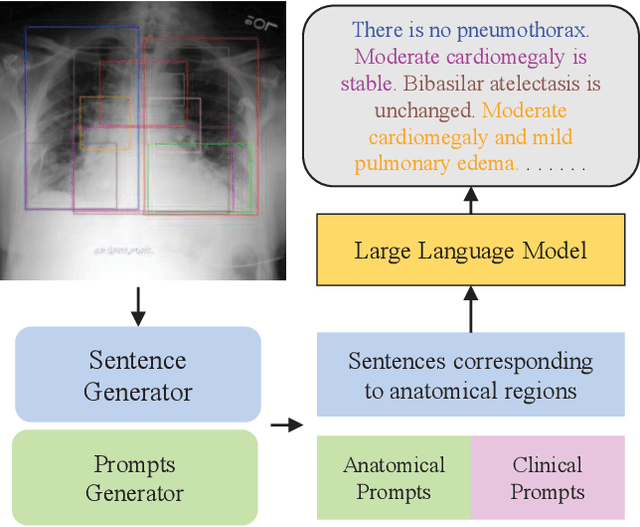
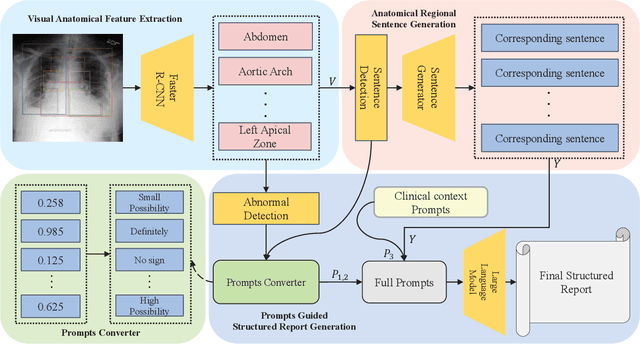
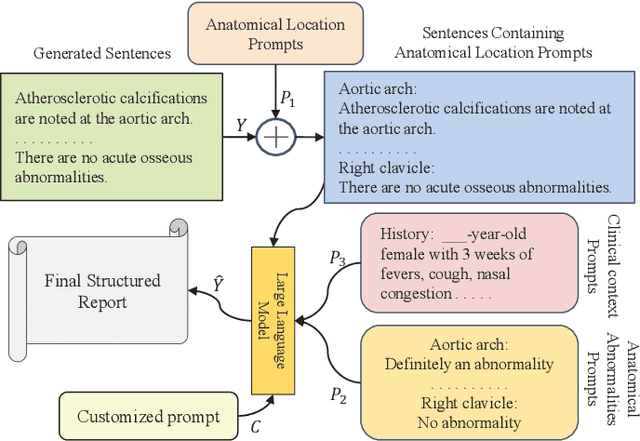

Medical report generation automates radiology descriptions from images, easing the burden on physicians and minimizing errors. However, current methods lack structured outputs and physician interactivity for clear, clinically relevant reports. Our method introduces a prompt-guided approach to generate structured chest X-ray reports using a pre-trained large language model (LLM). First, we identify anatomical regions in chest X-rays to generate focused sentences that center on key visual elements, thereby establishing a structured report foundation with anatomy-based sentences. We also convert the detected anatomy into textual prompts conveying anatomical comprehension to the LLM. Additionally, the clinical context prompts guide the LLM to emphasize interactivity and clinical requirements. By integrating anatomy-focused sentences and anatomy/clinical prompts, the pre-trained LLM can generate structured chest X-ray reports tailored to prompted anatomical regions and clinical contexts. We evaluate using language generation and clinical effectiveness metrics, demonstrating strong performance.
SHIELD : An Evaluation Benchmark for Face Spoofing and Forgery Detection with Multimodal Large Language Models
Feb 06, 2024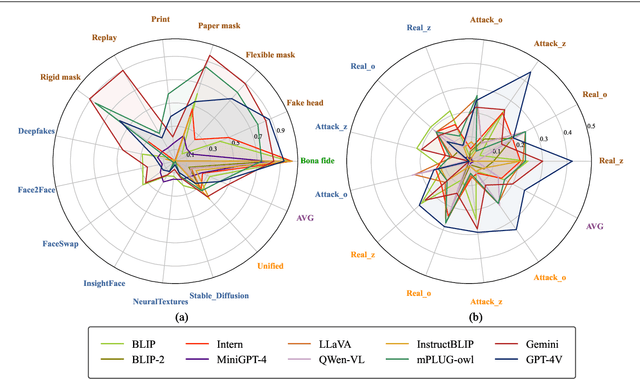
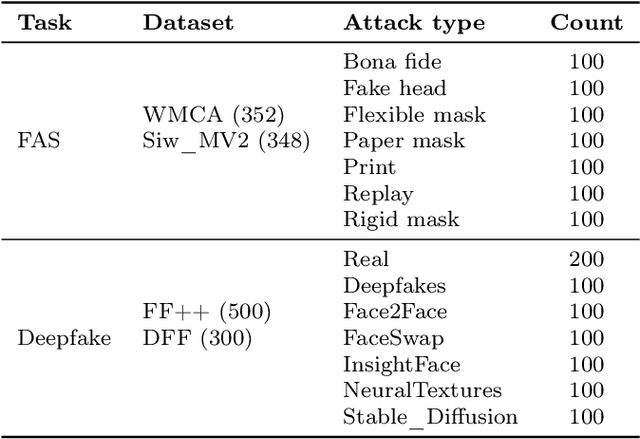

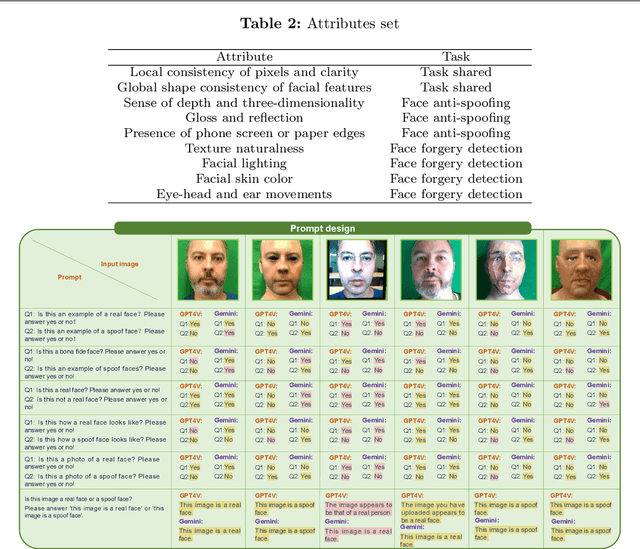
Multimodal large language models (MLLMs) have demonstrated remarkable problem-solving capabilities in various vision fields (e.g., generic object recognition and grounding) based on strong visual semantic representation and language reasoning ability. However, whether MLLMs are sensitive to subtle visual spoof/forged clues and how they perform in the domain of face attack detection (e.g., face spoofing and forgery detection) is still unexplored. In this paper, we introduce a new benchmark, namely SHIELD, to evaluate the ability of MLLMs on face spoofing and forgery detection. Specifically, we design true/false and multiple-choice questions to evaluate multimodal face data in these two face security tasks. For the face anti-spoofing task, we evaluate three different modalities (i.e., RGB, infrared, depth) under four types of presentation attacks (i.e., print attack, replay attack, rigid mask, paper mask). For the face forgery detection task, we evaluate GAN-based and diffusion-based data with both visual and acoustic modalities. Each question is subjected to both zero-shot and few-shot tests under standard and chain of thought (COT) settings. The results indicate that MLLMs hold substantial potential in the face security domain, offering advantages over traditional specific models in terms of interpretability, multimodal flexible reasoning, and joint face spoof and forgery detection. Additionally, we develop a novel Multi-Attribute Chain of Thought (MA-COT) paradigm for describing and judging various task-specific and task-irrelevant attributes of face images, which provides rich task-related knowledge for subtle spoof/forged clue mining. Extensive experiments in separate face anti-spoofing, separate face forgery detection, and joint detection tasks demonstrate the effectiveness of the proposed MA-COT. The project is available at https$:$//github.com/laiyingxin2/SHIELD
Scalable Normalizing Flows Enable Boltzmann Generators for Macromolecules
Jan 08, 2024The Boltzmann distribution of a protein provides a roadmap to all of its functional states. Normalizing flows are a promising tool for modeling this distribution, but current methods are intractable for typical pharmacological targets; they become computationally intractable due to the size of the system, heterogeneity of intra-molecular potential energy, and long-range interactions. To remedy these issues, we present a novel flow architecture that utilizes split channels and gated attention to efficiently learn the conformational distribution of proteins defined by internal coordinates. We show that by utilizing a 2-Wasserstein loss, one can smooth the transition from maximum likelihood training to energy-based training, enabling the training of Boltzmann Generators for macromolecules. We evaluate our model and training strategy on villin headpiece HP35(nle-nle), a 35-residue subdomain, and protein G, a 56-residue protein. We demonstrate that standard architectures and training strategies, such as maximum likelihood alone, fail while our novel architecture and multi-stage training strategy are able to model the conformational distributions of protein G and HP35.
Cross-Corpus Multilingual Speech Emotion Recognition: Amharic vs. Other Languages
Jul 20, 2023In a conventional Speech emotion recognition (SER) task, a classifier for a given language is trained on a pre-existing dataset for that same language. However, where training data for a language does not exist, data from other languages can be used instead. We experiment with cross-lingual and multilingual SER, working with Amharic, English, German and URDU. For Amharic, we use our own publicly-available Amharic Speech Emotion Dataset (ASED). For English, German and Urdu we use the existing RAVDESS, EMO-DB and URDU datasets. We followed previous research in mapping labels for all datasets to just two classes, positive and negative. Thus we can compare performance on different languages directly, and combine languages for training and testing. In Experiment 1, monolingual SER trials were carried out using three classifiers, AlexNet, VGGE (a proposed variant of VGG), and ResNet50. Results averaged for the three models were very similar for ASED and RAVDESS, suggesting that Amharic and English SER are equally difficult. Similarly, German SER is more difficult, and Urdu SER is easier. In Experiment 2, we trained on one language and tested on another, in both directions for each pair: Amharic<->German, Amharic<->English, and Amharic<->Urdu. Results with Amharic as target suggested that using English or German as source will give the best result. In Experiment 3, we trained on several non-Amharic languages and then tested on Amharic. The best accuracy obtained was several percent greater than the best accuracy in Experiment 2, suggesting that a better result can be obtained when using two or three non-Amharic languages for training than when using just one non-Amharic language. Overall, the results suggest that cross-lingual and multilingual training can be an effective strategy for training a SER classifier when resources for a language are scarce.