 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$Δ$VLA: Prior-Guided Vision-Language-Action Models via World Knowledge Variation
Mar 09, 2026Recent vision-language-action (VLA) models have significantly advanced robotic manipulation by unifying perception, reasoning, and control. To achieve such integration, recent studies adopt a predictive paradigm that models future visual states or world knowledge to guide action generation. However, these models emphasize forecasting outcomes rather than reasoning about the underlying process of change, which is essential for determining how to act. To address this, we propose $Δ$VLA, a prior-guided framework that models world-knowledge variations relative to an explicit current-world knowledge prior for action generation, rather than regressing absolute future world states. Specifically, 1) to construct the current world knowledge prior, we propose the Prior-Guided WorldKnowledge Extractor (PWKE). It extracts manipulable regions, spatial relations, and semantic cues from the visual input, guided by auxiliary heads and prior pseudo labels, thus reducing redundancy. 2) Building upon this, to represent how world knowledge evolves under actions, we introduce the Latent World Variation Quantization (LWVQ). It learns a discrete latent space via a VQ-VAE objective to encode world knowledge variations, shifting prediction from full modalities to compact latent. 3)Moreover, to mitigate interference during variation modeling, we design the Conditional Variation Attention (CV-Atten), whichpromotes disentangled learning and preserves the independence of knowledge representations. Extensive experiments on both simulated benchmarks and real-world robotic tasks demonstrate $Δ$VLA achieves state-of-the-art performance while improving efficiency. Code and real-world execution videos are available at https://github.com/JiuTian-VL/DeltaVLA.
SUGAR: Learning Skeleton Representation with Visual-Motion Knowledge for Action Recognition
Nov 13, 2025Large Language Models (LLMs) hold rich implicit knowledge and powerful transferability. In this paper, we explore the combination of LLMs with the human skeleton to perform action classification and description. However, when treating LLM as a recognizer, two questions arise: 1) How can LLMs understand skeleton? 2) How can LLMs distinguish among actions? To address these problems, we introduce a novel paradigm named learning Skeleton representation with visUal-motion knowledGe for Action Recognition (SUGAR). In our pipeline, we first utilize off-the-shelf large-scale video models as a knowledge base to generate visual, motion information related to actions. Then, we propose to supervise skeleton learning through this prior knowledge to yield discrete representations. Finally, we use the LLM with untouched pre-training weights to understand these representations and generate the desired action targets and descriptions. Notably, we present a Temporal Query Projection (TQP) module to continuously model the skeleton signals with long sequences. Experiments on several skeleton-based action classification benchmarks demonstrate the efficacy of our SUGAR. Moreover, experiments on zero-shot scenarios show that SUGAR is more versatile than linear-based methods.
Denoising and Alignment: Rethinking Domain Generalization for Multimodal Face Anti-Spoofing
May 14, 2025Face Anti-Spoofing (FAS) is essential for the security of facial recognition systems in diverse scenarios such as payment processing and surveillance. Current multimodal FAS methods often struggle with effective generalization, mainly due to modality-specific biases and domain shifts. To address these challenges, we introduce the \textbf{M}ulti\textbf{m}odal \textbf{D}enoising and \textbf{A}lignment (\textbf{MMDA}) framework. By leveraging the zero-shot generalization capability of CLIP, the MMDA framework effectively suppresses noise in multimodal data through denoising and alignment mechanisms, thereby significantly enhancing the generalization performance of cross-modal alignment. The \textbf{M}odality-\textbf{D}omain Joint \textbf{D}ifferential \textbf{A}ttention (\textbf{MD2A}) module in MMDA concurrently mitigates the impacts of domain and modality noise by refining the attention mechanism based on extracted common noise features. Furthermore, the \textbf{R}epresentation \textbf{S}pace \textbf{S}oft (\textbf{RS2}) Alignment strategy utilizes the pre-trained CLIP model to align multi-domain multimodal data into a generalized representation space in a flexible manner, preserving intricate representations and enhancing the model's adaptability to various unseen conditions. We also design a \textbf{U}-shaped \textbf{D}ual \textbf{S}pace \textbf{A}daptation (\textbf{U-DSA}) module to enhance the adaptability of representations while maintaining generalization performance. These improvements not only enhance the framework's generalization capabilities but also boost its ability to represent complex representations. Our experimental results on four benchmark datasets under different evaluation protocols demonstrate that the MMDA framework outperforms existing state-of-the-art methods in terms of cross-domain generalization and multimodal detection accuracy. The code will be released soon.
FaceShield: Explainable Face Anti-Spoofing with Multimodal Large Language Models
May 14, 2025
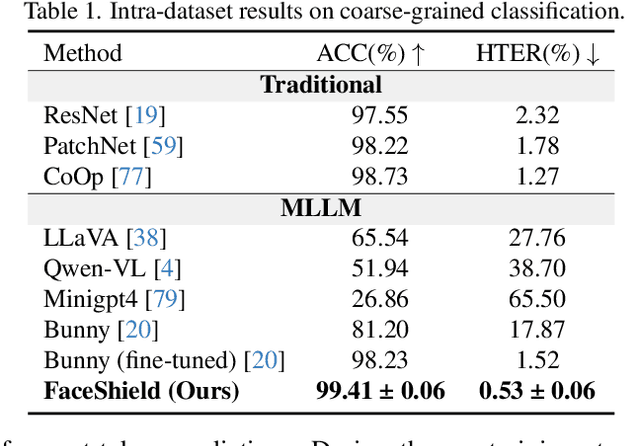
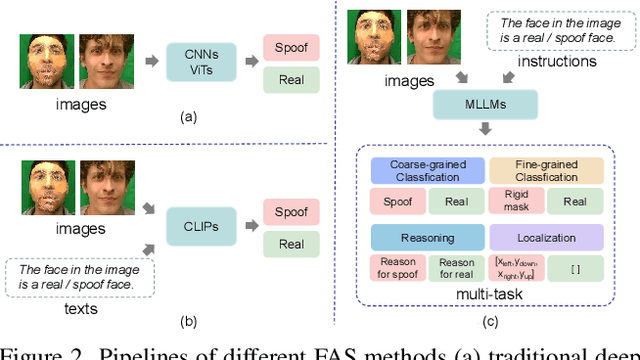
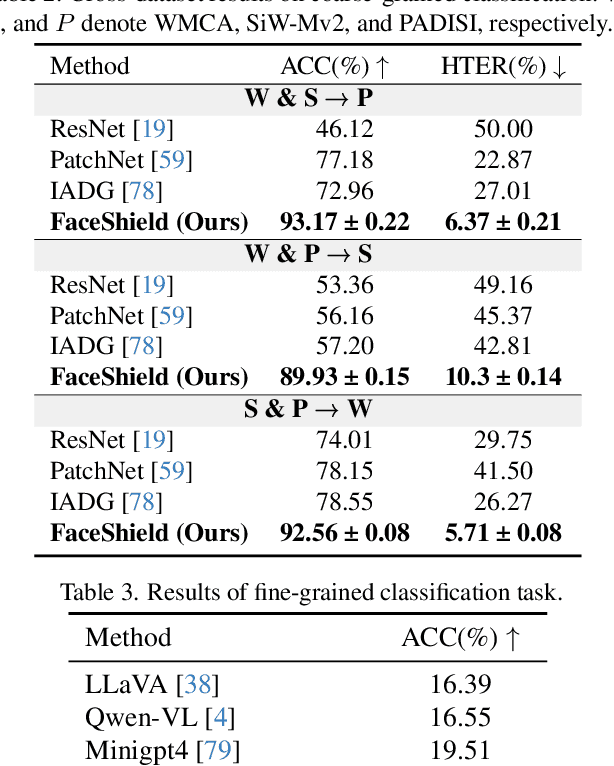
Face anti-spoofing (FAS) is crucial for protecting facial recognition systems from presentation attacks. Previous methods approached this task as a classification problem, lacking interpretability and reasoning behind the predicted results. Recently, multimodal large language models (MLLMs) have shown strong capabilities in perception, reasoning, and decision-making in visual tasks. However, there is currently no universal and comprehensive MLLM and dataset specifically designed for FAS task. To address this gap, we propose FaceShield, a MLLM for FAS, along with the corresponding pre-training and supervised fine-tuning (SFT) datasets, FaceShield-pre10K and FaceShield-sft45K. FaceShield is capable of determining the authenticity of faces, identifying types of spoofing attacks, providing reasoning for its judgments, and detecting attack areas. Specifically, we employ spoof-aware vision perception (SAVP) that incorporates both the original image and auxiliary information based on prior knowledge. We then use an prompt-guided vision token masking (PVTM) strategy to random mask vision tokens, thereby improving the model's generalization ability. We conducted extensive experiments on three benchmark datasets, demonstrating that FaceShield significantly outperforms previous deep learning models and general MLLMs on four FAS tasks, i.e., coarse-grained classification, fine-grained classification, reasoning, and attack localization. Our instruction datasets, protocols, and codes will be released soon.
AttFC: Attention Fully-Connected Layer for Large-Scale Face Recognition with One GPU
Mar 10, 2025Nowadays, with the advancement of deep neural networks (DNNs) and the availability of large-scale datasets, the face recognition (FR) model has achieved exceptional performance. However, since the parameter magnitude of the fully connected (FC) layer directly depends on the number of identities in the dataset. If training the FR model on large-scale datasets, the size of the model parameter will be excessively huge, leading to substantial demand for computational resources, such as time and memory. This paper proposes the attention fully connected (AttFC) layer, which could significantly reduce computational resources. AttFC employs an attention loader to generate the generative class center (GCC), and dynamically store the class center with Dynamic Class Container (DCC). DCC only stores a small subset of all class centers in FC, thus its parameter count is substantially less than the FC layer. Also, training face recognition models on large-scale datasets with one GPU often encounter out-of-memory (OOM) issues. AttFC overcomes this and achieves comparable performance to state-of-the-art methods.
MSConv: Multiplicative and Subtractive Convolution for Face Recognition
Mar 08, 2025In Neural Networks, there are various methods of feature fusion. Different strategies can significantly affect the effectiveness of feature representation, consequently influencing the ability of model to extract representative and discriminative features. In the field of face recognition, traditional feature fusion methods include feature concatenation and feature addition. Recently, various attention mechanism-based fusion strategies have emerged. However, we found that these methods primarily focus on the important features in the image, referred to as salient features in this paper, while neglecting another equally important set of features for image recognition tasks, which we term differential features. This may cause the model to overlook critical local differences when dealing with complex facial samples. Therefore, in this paper, we propose an efficient convolution module called MSConv (Multiplicative and Subtractive Convolution), designed to balance the learning of model about salient and differential features. Specifically, we employ multi-scale mixed convolution to capture both local and broader contextual information from face images, and then utilize Multiplication Operation (MO) and Subtraction Operation (SO) to extract salient and differential features, respectively. Experimental results demonstrate that by integrating both salient and differential features, MSConv outperforms models that only focus on salient features.
IMAN: An Adaptive Network for Robust NPC Mortality Prediction with Missing Modalities
Oct 24, 2024Accurate prediction of mortality in nasopharyngeal carcinoma (NPC), a complex malignancy particularly challenging in advanced stages, is crucial for optimizing treatment strategies and improving patient outcomes. However, this predictive process is often compromised by the high-dimensional and heterogeneous nature of NPC-related data, coupled with the pervasive issue of incomplete multi-modal data, manifesting as missing radiological images or incomplete diagnostic reports. Traditional machine learning approaches suffer significant performance degradation when faced with such incomplete data, as they fail to effectively handle the high-dimensionality and intricate correlations across modalities. Even advanced multi-modal learning techniques like Transformers struggle to maintain robust performance in the presence of missing modalities, as they lack specialized mechanisms to adaptively integrate and align the diverse data types, while also capturing nuanced patterns and contextual relationships within the complex NPC data. To address these problem, we introduce IMAN: an adaptive network for robust NPC mortality prediction with missing modalities.
TAGE: Trustworthy Attribute Group Editing for Stable Few-shot Image Generation
Oct 23, 2024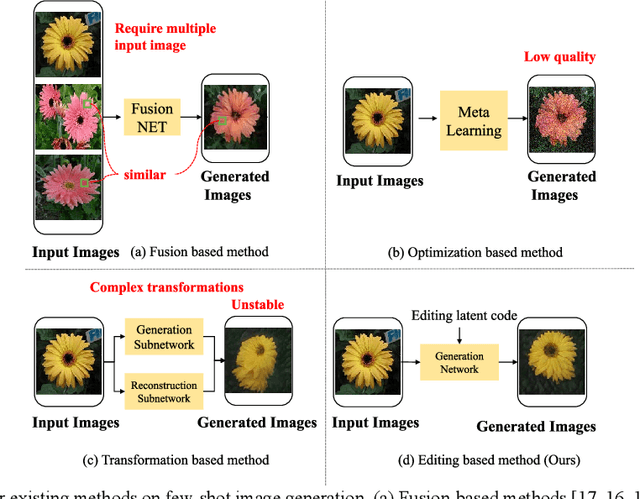
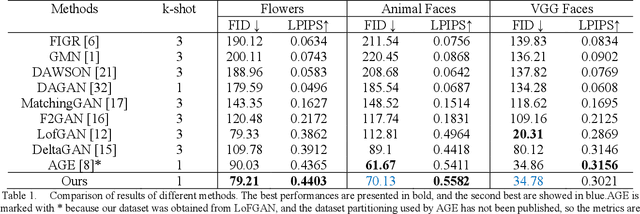


Generative Adversarial Networks (GANs) have emerged as a prominent research focus for image editing tasks, leveraging the powerful image generation capabilities of the GAN framework to produce remarkable results.However, prevailing approaches are contingent upon extensive training datasets and explicit supervision, presenting a significant challenge in manipulating the diverse attributes of new image classes with limited sample availability. To surmount this hurdle, we introduce TAGE, an innovative image generation network comprising three integral modules: the Codebook Learning Module (CLM), the Code Prediction Module (CPM) and the Prompt-driven Semantic Module (PSM). The CPM module delves into the semantic dimensions of category-agnostic attributes, encapsulating them within a discrete codebook. This module is predicated on the concept that images are assemblages of attributes, and thus, by editing these category-independent attributes, it is theoretically possible to generate images from unseen categories. Subsequently, the CPM module facilitates naturalistic image editing by predicting indices of category-independent attribute vectors within the codebook. Additionally, the PSM module generates semantic cues that are seamlessly integrated into the Transformer architecture of the CPM, enhancing the model's comprehension of the targeted attributes for editing. With these semantic cues, the model can generate images that accentuate desired attributes more prominently while maintaining the integrity of the original category, even with a limited number of samples. We have conducted extensive experiments utilizing the Animal Faces, Flowers, and VGGFaces datasets. The results of these experiments demonstrate that our proposed method not only achieves superior performance but also exhibits a high degree of stability when compared to other few-shot image generation techniques.
MHLR: Moving Haar Learning Rate Scheduler for Large-scale Face Recognition Training with One GPU
Apr 17, 2024



Face recognition (FR) has seen significant advancements due to the utilization of large-scale datasets. Training deep FR models on large-scale datasets with multiple GPUs is now a common practice. In fact, computing power has evolved into a foundational and indispensable resource in the area of deep learning. It is nearly impossible to train a deep FR model without holding adequate hardware resources. Recognizing this challenge, some FR approaches have started exploring ways to reduce the time complexity of the fully-connected layer in FR models. Unlike other approaches, this paper introduces a simple yet highly effective approach, Moving Haar Learning Rate (MHLR) scheduler, for scheduling the learning rate promptly and accurately in the training process. MHLR supports large-scale FR training with only one GPU, which is able to accelerate the model to 1/4 of its original training time without sacrificing more than 1% accuracy. More specifically, MHLR only needs $30$ hours to train the model ResNet100 on the dataset WebFace12M containing more than 12M face images with 0.6M identities. Extensive experiments validate the efficiency and effectiveness of MHLR.
Adaptive Query Prompting for Multi-Domain Landmark Detection
Apr 01, 2024



Medical landmark detection is crucial in various medical imaging modalities and procedures. Although deep learning-based methods have achieve promising performance, they are mostly designed for specific anatomical regions or tasks. In this work, we propose a universal model for multi-domain landmark detection by leveraging transformer architecture and developing a prompting component, named as Adaptive Query Prompting (AQP). Instead of embedding additional modules in the backbone network, we design a separate module to generate prompts that can be effectively extended to any other transformer network. In our proposed AQP, prompts are learnable parameters maintained in a memory space called prompt pool. The central idea is to keep the backbone frozen and then optimize prompts to instruct the model inference process. Furthermore, we employ a lightweight decoder to decode landmarks from the extracted features, namely Light-MLD. Thanks to the lightweight nature of the decoder and AQP, we can handle multiple datasets by sharing the backbone encoder and then only perform partial parameter tuning without incurring much additional cost. It has the potential to be extended to more landmark detection tasks. We conduct experiments on three widely used X-ray datasets for different medical landmark detection tasks. Our proposed Light-MLD coupled with AQP achieves SOTA performance on many metrics even without the use of elaborate structural designs or complex frameworks.