 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Verification to Amplification: Auditing Reverse Image Search as Algorithmic Gatekeeping in Visual Misinformation Fact-checking
Mar 10, 2026As visual misinformation becomes increasingly prevalent, platform algorithms act as intermediaries that curate information for users' verification practices. Yet, it remains unclear how algorithmic gatekeeping tools, such as reverse image search (RIS), shape users' information exposure during fact-checking. This study systematically audits Google RIS by reversely searching newly identified misleading images over a 15-day window and analyzing 34,486 collected top-ranked search results. We find that Google RIS returns a substantial volume of irrelevant information and repeated misinformation, whereas debunking content constitutes less than 30% of search results. Debunking content faces visibility challenges in rankings amid repeated misinformation and irrelevant information. Our findings also indicate an inverted U-shaped curve of RIS results page quality over time, likely due to search engine "data voids" when visual falsehoods first appear. These findings contribute to scholarship of visual misinformation verification, and extend algorithmic gatekeeping research to the visual domain.
GVGAI-LLM: Evaluating Large Language Model Agents with Infinite Games
Aug 11, 2025We introduce GVGAI-LLM, a video game benchmark for evaluating the reasoning and problem-solving capabilities of large language models (LLMs). Built on the General Video Game AI framework, it features a diverse collection of arcade-style games designed to test a model's ability to handle tasks that differ from most existing LLM benchmarks. The benchmark leverages a game description language that enables rapid creation of new games and levels, helping to prevent overfitting over time. Each game scene is represented by a compact set of ASCII characters, allowing for efficient processing by language models. GVGAI-LLM defines interpretable metrics, including the meaningful step ratio, step efficiency, and overall score, to assess model behavior. Through zero-shot evaluations across a broad set of games and levels with diverse challenges and skill depth, we reveal persistent limitations of LLMs in spatial reasoning and basic planning. Current models consistently exhibit spatial and logical errors, motivating structured prompting and spatial grounding techniques. While these interventions lead to partial improvements, the benchmark remains very far from solved. GVGAI-LLM provides a reproducible testbed for advancing research on language model capabilities, with a particular emphasis on agentic behavior and contextual reasoning.
Astrea: A MOE-based Visual Understanding Model with Progressive Alignment
Mar 12, 2025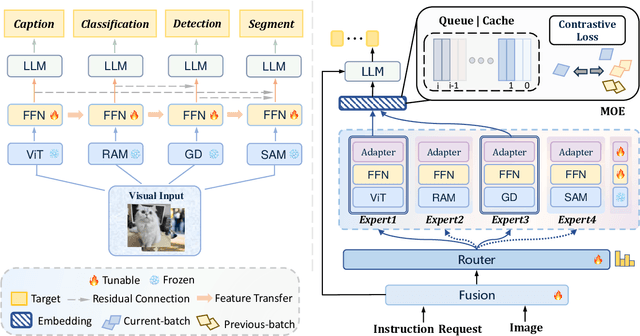
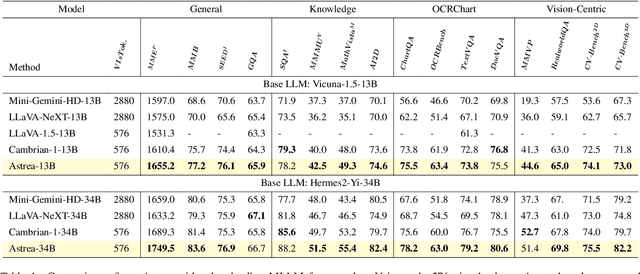
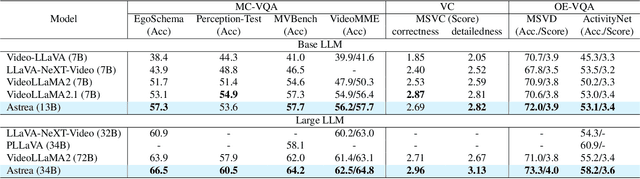
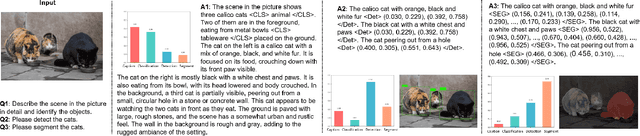
Vision-Language Models (VLMs) based on Mixture-of-Experts (MoE) architectures have emerged as a pivotal paradigm in multimodal understanding, offering a powerful framework for integrating visual and linguistic information. However, the increasing complexity and diversity of tasks present significant challenges in coordinating load balancing across heterogeneous visual experts, where optimizing one specialist's performance often compromises others' capabilities. To address task heterogeneity and expert load imbalance, we propose Astrea, a novel multi-expert collaborative VLM architecture based on progressive pre-alignment. Astrea introduces three key innovations: 1) A heterogeneous expert coordination mechanism that integrates four specialized models (detection, segmentation, classification, captioning) into a comprehensive expert matrix covering essential visual comprehension elements; 2) A dynamic knowledge fusion strategy featuring progressive pre-alignment to harmonize experts within the VLM latent space through contrastive learning, complemented by probabilistically activated stochastic residual connections to preserve knowledge continuity; 3) An enhanced optimization framework utilizing momentum contrastive learning for long-range dependency modeling and adaptive weight allocators for real-time expert contribution calibration. Extensive evaluations across 12 benchmark tasks spanning VQA, image captioning, and cross-modal retrieval demonstrate Astrea's superiority over state-of-the-art models, achieving an average performance gain of +4.7\%. This study provides the first empirical demonstration that progressive pre-alignment strategies enable VLMs to overcome task heterogeneity limitations, establishing new methodological foundations for developing general-purpose multimodal agents.
MSConv: Multiplicative and Subtractive Convolution for Face Recognition
Mar 08, 2025In Neural Networks, there are various methods of feature fusion. Different strategies can significantly affect the effectiveness of feature representation, consequently influencing the ability of model to extract representative and discriminative features. In the field of face recognition, traditional feature fusion methods include feature concatenation and feature addition. Recently, various attention mechanism-based fusion strategies have emerged. However, we found that these methods primarily focus on the important features in the image, referred to as salient features in this paper, while neglecting another equally important set of features for image recognition tasks, which we term differential features. This may cause the model to overlook critical local differences when dealing with complex facial samples. Therefore, in this paper, we propose an efficient convolution module called MSConv (Multiplicative and Subtractive Convolution), designed to balance the learning of model about salient and differential features. Specifically, we employ multi-scale mixed convolution to capture both local and broader contextual information from face images, and then utilize Multiplication Operation (MO) and Subtraction Operation (SO) to extract salient and differential features, respectively. Experimental results demonstrate that by integrating both salient and differential features, MSConv outperforms models that only focus on salient features.
From Semantics to Hierarchy: A Hybrid Euclidean-Tangent-Hyperbolic Space Model for Temporal Knowledge Graph Reasoning
Aug 30, 2024Temporal knowledge graph (TKG) reasoning predicts future events based on historical data, but it's challenging due to the complex semantic and hierarchical information involved. Existing Euclidean models excel at capturing semantics but struggle with hierarchy. Conversely, hyperbolic models manage hierarchical features well but fail to represent complex semantics due to limitations in shallow models' parameters and the absence of proper normalization in deep models relying on the L2 norm. Current solutions, as curvature transformations, are insufficient to address these issues. In this work, a novel hybrid geometric space approach that leverages the strengths of both Euclidean and hyperbolic models is proposed. Our approach transitions from single-space to multi-space parameter modeling, effectively capturing both semantic and hierarchical information. Initially, complex semantics are captured through a fact co-occurrence and autoregressive method with normalizations in Euclidean space. The embeddings are then transformed into Tangent space using a scaling mechanism, preserving semantic information while relearning hierarchical structures through a query-candidate separated modeling approach, which are subsequently transformed into Hyperbolic space. Finally, a hybrid inductive bias for hierarchical and semantic learning is achieved by combining hyperbolic and Euclidean scoring functions through a learnable query-specific mixing coefficient, utilizing embeddings from hyperbolic and Euclidean spaces. Experimental results on four TKG benchmarks demonstrate that our method reduces error relatively by up to 15.0% in mean reciprocal rank on YAGO compared to previous single-space models. Additionally, enriched visualization analysis validates the effectiveness of our approach, showing adaptive capabilities for datasets with varying levels of semantic and hierarchical complexity.
MHLR: Moving Haar Learning Rate Scheduler for Large-scale Face Recognition Training with One GPU
Apr 17, 2024



Face recognition (FR) has seen significant advancements due to the utilization of large-scale datasets. Training deep FR models on large-scale datasets with multiple GPUs is now a common practice. In fact, computing power has evolved into a foundational and indispensable resource in the area of deep learning. It is nearly impossible to train a deep FR model without holding adequate hardware resources. Recognizing this challenge, some FR approaches have started exploring ways to reduce the time complexity of the fully-connected layer in FR models. Unlike other approaches, this paper introduces a simple yet highly effective approach, Moving Haar Learning Rate (MHLR) scheduler, for scheduling the learning rate promptly and accurately in the training process. MHLR supports large-scale FR training with only one GPU, which is able to accelerate the model to 1/4 of its original training time without sacrificing more than 1% accuracy. More specifically, MHLR only needs $30$ hours to train the model ResNet100 on the dataset WebFace12M containing more than 12M face images with 0.6M identities. Extensive experiments validate the efficiency and effectiveness of MHLR.
SUGAR: Spherical Ultrafast Graph Attention Framework for Cortical Surface Registration
Jul 02, 2023



Cortical surface registration plays a crucial role in aligning cortical functional and anatomical features across individuals. However, conventional registration algorithms are computationally inefficient. Recently, learning-based registration algorithms have emerged as a promising solution, significantly improving processing efficiency. Nonetheless, there remains a gap in the development of a learning-based method that exceeds the state-of-the-art conventional methods simultaneously in computational efficiency, registration accuracy, and distortion control, despite the theoretically greater representational capabilities of deep learning approaches. To address the challenge, we present SUGAR, a unified unsupervised deep-learning framework for both rigid and non-rigid registration. SUGAR incorporates a U-Net-based spherical graph attention network and leverages the Euler angle representation for deformation. In addition to the similarity loss, we introduce fold and multiple distortion losses, to preserve topology and minimize various types of distortions. Furthermore, we propose a data augmentation strategy specifically tailored for spherical surface registration, enhancing the registration performance. Through extensive evaluation involving over 10,000 scans from 7 diverse datasets, we showed that our framework exhibits comparable or superior registration performance in accuracy, distortion, and test-retest reliability compared to conventional and learning-based methods. Additionally, SUGAR achieves remarkable sub-second processing times, offering a notable speed-up of approximately 12,000 times in registering 9,000 subjects from the UK Biobank dataset in just 32 minutes. This combination of high registration performance and accelerated processing time may greatly benefit large-scale neuroimaging studies.
KDCTime: Knowledge Distillation with Calibration on InceptionTime for Time-series Classification
Dec 04, 2021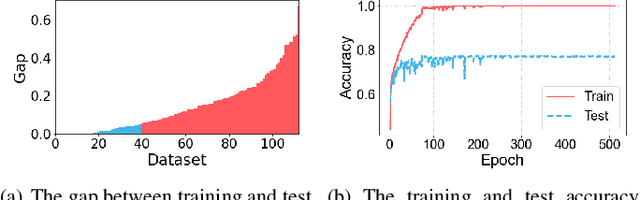


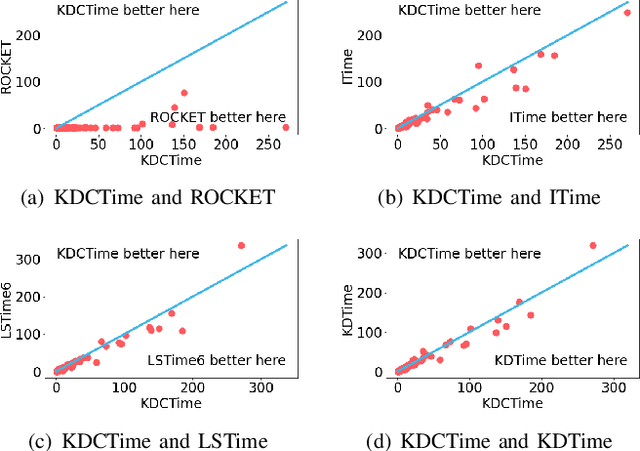
Time-series classification approaches based on deep neural networks are easy to be overfitting on UCR datasets, which is caused by the few-shot problem of those datasets. Therefore, in order to alleviate the overfitting phenomenon for further improving the accuracy, we first propose Label Smoothing for InceptionTime (LSTime), which adopts the information of soft labels compared to just hard labels. Next, instead of manually adjusting soft labels by LSTime, Knowledge Distillation for InceptionTime (KDTime) is proposed in order to automatically generate soft labels by the teacher model. At last, in order to rectify the incorrect predicted soft labels from the teacher model, Knowledge Distillation with Calibration for InceptionTime (KDCTime) is proposed, where it contains two optional calibrating strategies, i.e. KDC by Translating (KDCT) and KDC by Reordering (KDCR). The experimental results show that the accuracy of KDCTime is promising, while its inference time is two orders of magnitude faster than ROCKET with an acceptable training time overhead.
Regularization Matters: A Nonparametric Perspective on Overparametrized Neural Network
Jul 06, 2020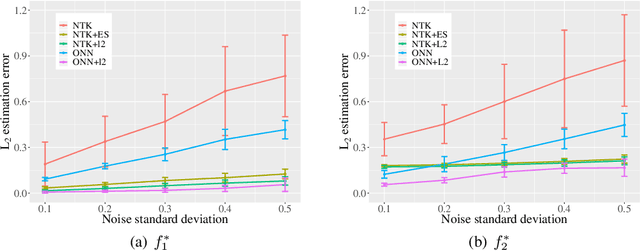

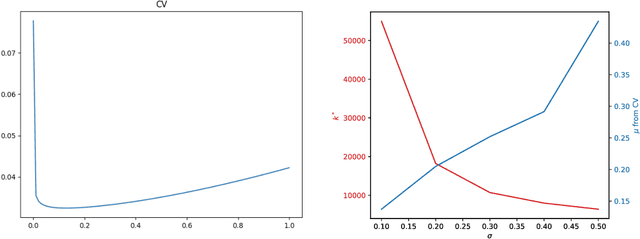
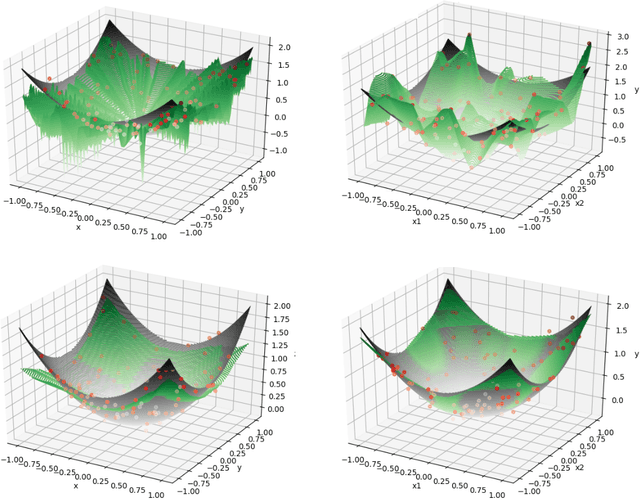
Overparametrized neural networks trained by gradient descent (GD) can provably overfit any training data. However, the generalization guarantee may not hold for noisy data. From a nonparametric perspective, this paper studies how well overparametrized neural networks can recover the true target function in the presence of random noises. We establish a lower bound on the $L_2$ estimation error with respect to the GD iteration, which is away from zero without a delicate choice of early stopping. In turn, through a comprehensive analysis of $\ell_2$-regularized GD trajectories, we prove that for overparametrized one-hidden-layer ReLU neural network with the $\ell_2$ regularization: (1) the output is close to that of the kernel ridge regression with the corresponding neural tangent kernel; (2) minimax {optimal} rate of $L_2$ estimation error is achieved. Numerical experiments confirm our theory and further demonstrate that the $\ell_2$ regularization approach improves the training robustness and works for a wider range of neural networks.
Self-organization of multi-layer spiking neural networks
Jun 12, 2020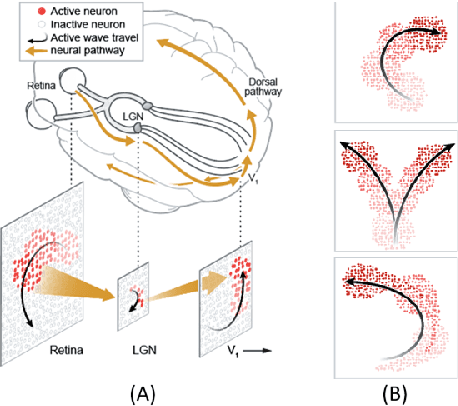
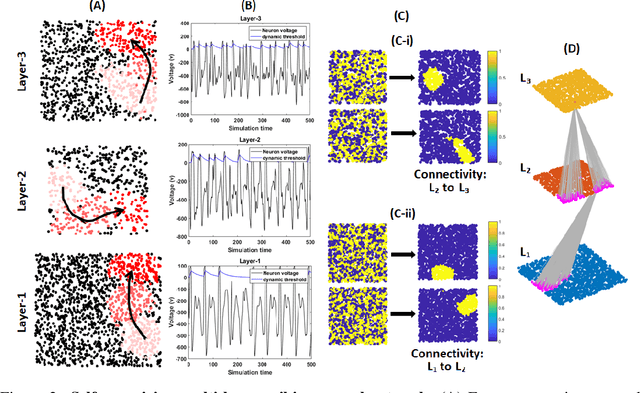
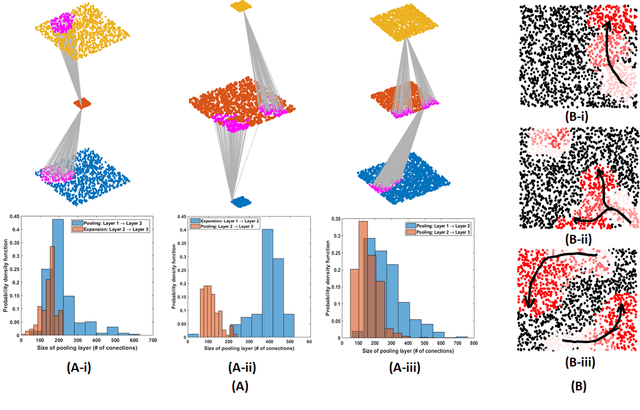
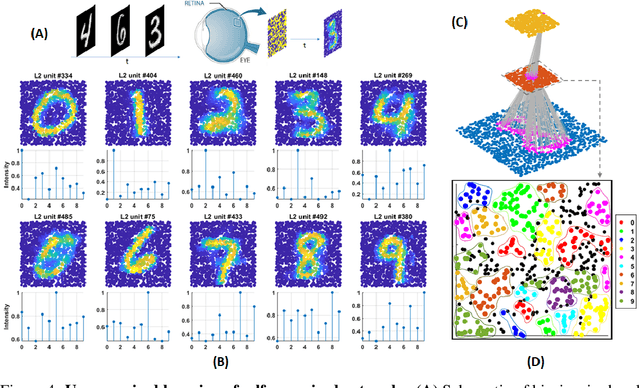
Living neural networks in our brains autonomously self-organize into large, complex architectures during early development to result in an organized and functional organic computational device. A key mechanism that enables the formation of complex architecture in the developing brain is the emergence of traveling spatio-temporal waves of neuronal activity across the growing brain. Inspired by this strategy, we attempt to efficiently self-organize large neural networks with an arbitrary number of layers into a wide variety of architectures. To achieve this, we propose a modular tool-kit in the form of a dynamical system that can be seamlessly stacked to assemble multi-layer neural networks. The dynamical system encapsulates the dynamics of spiking units, their inter/intra layer interactions as well as the plasticity rules that control the flow of information between layers. The key features of our tool-kit are (1) autonomous spatio-temporal waves across multiple layers triggered by activity in the preceding layer and (2) Spike-timing dependent plasticity (STDP) learning rules that update the inter-layer connectivity based on wave activity in the connecting layers. Our framework leads to the self-organization of a wide variety of architectures, ranging from multi-layer perceptrons to autoencoders. We also demonstrate that emergent waves can self-organize spiking network architecture to perform unsupervised learning, and networks can be coupled with a linear classifier to perform classification on classic image datasets like MNIST. Broadly, our work shows that a dynamical systems framework for learning can be used to self-organize large computational devices.