 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularization Matters: A Nonparametric Perspective on Overparametrized Neural Network
Paper and Code
Jul 06, 2020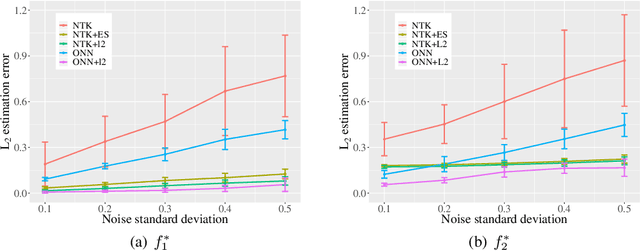

Overparametrized neural networks trained by gradient descent (GD) can provably overfit any training data. However, the generalization guarantee may not hold for noisy data. From a nonparametric perspective, this paper studies how well overparametrized neural networks can recover the true target function in the presence of random noises. We establish a lower bound on the $L_2$ estimation error with respect to the GD iteration, which is away from zero without a delicate choice of early stopping. In turn, through a comprehensive analysis of $\ell_2$-regularized GD trajectories, we prove that for overparametrized one-hidden-layer ReLU neural network with the $\ell_2$ regularization: (1) the output is close to that of the kernel ridge regression with the corresponding neural tangent kernel; (2) minimax {optimal} rate of $L_2$ estimation error is achieved. Numerical experiments confirm our theory and further demonstrate that the $\ell_2$ regularization approach improves the training robustness and works for a wider range of neural networks.