 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavBench: Benchmarking Reasoning, Colloquialism, and Paralinguistics for End-to-End Spoken Dialogue Models
Feb 13, 2026With the rapid integration of advanced reasoning capabilities into spoken dialogue models, the field urgently demands benchmarks that transcend simple interactions to address real-world complexity. However, current evaluations predominantly adhere to text-generation standards, overlooking the unique audio-centric characteristics of paralinguistics and colloquialisms, alongside the cognitive depth required by modern agents. To bridge this gap, we introduce WavBench, a comprehensive benchmark designed to evaluate realistic conversational abilities where prior works fall short. Uniquely, WavBench establishes a tripartite framework: 1) Pro subset, designed to rigorously challenge reasoning-enhanced models with significantly increased difficulty; 2) Basic subset, defining a novel standard for spoken colloquialism that prioritizes "listenability" through natural vocabulary, linguistic fluency, and interactive rapport, rather than rigid written accuracy; and 3) Acoustic subset, covering explicit understanding, generation, and implicit dialogue to rigorously evaluate comprehensive paralinguistic capabilities within authentic real-world scenarios. Through evaluating five state-of-the-art models, WavBench offers critical insights into the intersection of complex problem-solving, colloquial delivery, and paralinguistic fidelity, guiding the evolution of robust spoken dialogue models. The benchmark dataset and evaluation toolkit are available at https://naruto-2024.github.io/wavbench.github.io/.
TAP: Parameter-efficient Task-Aware Prompting for Adverse Weather Removal
Aug 11, 2025Image restoration under adverse weather conditions has been extensively explored, leading to numerous high-performance methods. In particular, recent advances in All-in-One approaches have shown impressive results by training on multi-task image restoration datasets. However, most of these methods rely on dedicated network modules or parameters for each specific degradation type, resulting in a significant parameter overhead. Moreover, the relatedness across different restoration tasks is often overlooked. In light of these issues, we propose a parameter-efficient All-in-One image restoration framework that leverages task-aware enhanced prompts to tackle various adverse weather degradations.Specifically, we adopt a two-stage training paradigm consisting of a pretraining phase and a prompt-tuning phase to mitigate parameter conflicts across tasks. We first employ supervised learning to acquire general restoration knowledge, and then adapt the model to handle specific degradation via trainable soft prompts. Crucially, we enhance these task-specific prompts in a task-aware manner. We apply low-rank decomposition to these prompts to capture both task-general and task-specific characteristics, and impose contrastive constraints to better align them with the actual inter-task relatedness. These enhanced prompts not only improve the parameter efficiency of the restoration model but also enable more accurate task modeling, as evidenced by t-SNE analysis. Experimental results on different restoration tasks demonstrate that the proposed method achieves superior performance with only 2.75M parameters.
IRBridge: Solving Image Restoration Bridge with Pre-trained Generative Diffusion Models
May 30, 2025Bridge models in image restoration construct a diffusion process from degraded to clear images. However, existing methods typically require training a bridge model from scratch for each specific type of degradation, resulting in high computational costs and limited performance. This work aims to efficiently leverage pretrained generative priors within existing image restoration bridges to eliminate this requirement. The main challenge is that standard generative models are typically designed for a diffusion process that starts from pure noise, while restoration tasks begin with a low-quality image, resulting in a mismatch in the state distributions between the two processes. To address this challenge, we propose a transition equation that bridges two diffusion processes with the same endpoint distribution. Based on this, we introduce the IRBridge framework, which enables the direct utilization of generative models within image restoration bridges, offering a more flexible and adaptable approach to image restoration. Extensive experiments on six image restoration tasks demonstrate that IRBridge efficiently integrates generative priors, resulting in improved robustness and generalization performance. Code will be available at GitHub.
T2A-Feedback: Improving Basic Capabilities of Text-to-Audio Generation via Fine-grained AI Feedback
May 15, 2025

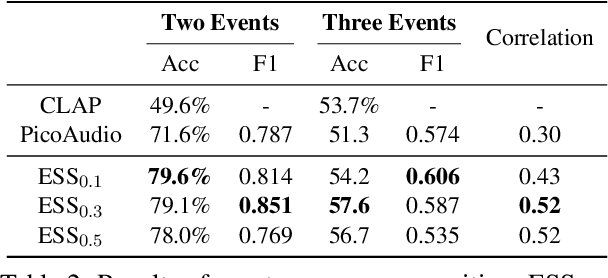

Text-to-audio (T2A) generation has achieved remarkable progress in generating a variety of audio outputs from language prompts. However, current state-of-the-art T2A models still struggle to satisfy human preferences for prompt-following and acoustic quality when generating complex multi-event audio. To improve the performance of the model in these high-level applications, we propose to enhance the basic capabilities of the model with AI feedback learning. First, we introduce fine-grained AI audio scoring pipelines to: 1) verify whether each event in the text prompt is present in the audio (Event Occurrence Score), 2) detect deviations in event sequences from the language description (Event Sequence Score), and 3) assess the overall acoustic and harmonic quality of the generated audio (Acoustic&Harmonic Quality). We evaluate these three automatic scoring pipelines and find that they correlate significantly better with human preferences than other evaluation metrics. This highlights their value as both feedback signals and evaluation metrics. Utilizing our robust scoring pipelines, we construct a large audio preference dataset, T2A-FeedBack, which contains 41k prompts and 249k audios, each accompanied by detailed scores. Moreover, we introduce T2A-EpicBench, a benchmark that focuses on long captions, multi-events, and story-telling scenarios, aiming to evaluate the advanced capabilities of T2A models. Finally, we demonstrate how T2A-FeedBack can enhance current state-of-the-art audio model. With simple preference tuning, the audio generation model exhibits significant improvements in both simple (AudioCaps test set) and complex (T2A-EpicBench) scenarios.
WavReward: Spoken Dialogue Models With Generalist Reward Evaluators
May 14, 2025End-to-end spoken dialogue models such as GPT-4o-audio have recently garnered significant attention in the speech domain. However, the evaluation of spoken dialogue models' conversational performance has largely been overlooked. This is primarily due to the intelligent chatbots convey a wealth of non-textual information which cannot be easily measured using text-based language models like ChatGPT. To address this gap, we propose WavReward, a reward feedback model based on audio language models that can evaluate both the IQ and EQ of spoken dialogue systems with speech input. Specifically, 1) based on audio language models, WavReward incorporates the deep reasoning process and the nonlinear reward mechanism for post-training. By utilizing multi-sample feedback via the reinforcement learning algorithm, we construct a specialized evaluator tailored to spoken dialogue models. 2) We introduce ChatReward-30K, a preference dataset used to train WavReward. ChatReward-30K includes both comprehension and generation aspects of spoken dialogue models. These scenarios span various tasks, such as text-based chats, nine acoustic attributes of instruction chats, and implicit chats. WavReward outperforms previous state-of-the-art evaluation models across multiple spoken dialogue scenarios, achieving a substantial improvement about Qwen2.5-Omni in objective accuracy from 55.1$\%$ to 91.5$\%$. In subjective A/B testing, WavReward also leads by a margin of 83$\%$. Comprehensive ablation studies confirm the necessity of each component of WavReward. All data and code will be publicly at https://github.com/jishengpeng/WavReward after the paper is accepted.
Astrea: A MOE-based Visual Understanding Model with Progressive Alignment
Mar 12, 2025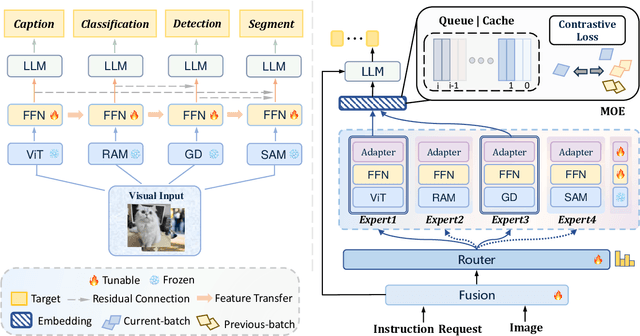
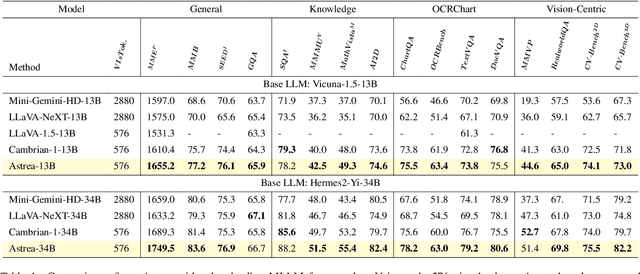
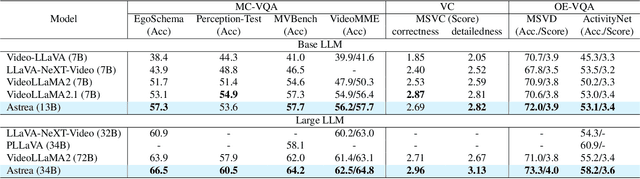
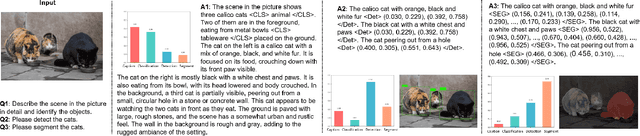
Vision-Language Models (VLMs) based on Mixture-of-Experts (MoE) architectures have emerged as a pivotal paradigm in multimodal understanding, offering a powerful framework for integrating visual and linguistic information. However, the increasing complexity and diversity of tasks present significant challenges in coordinating load balancing across heterogeneous visual experts, where optimizing one specialist's performance often compromises others' capabilities. To address task heterogeneity and expert load imbalance, we propose Astrea, a novel multi-expert collaborative VLM architecture based on progressive pre-alignment. Astrea introduces three key innovations: 1) A heterogeneous expert coordination mechanism that integrates four specialized models (detection, segmentation, classification, captioning) into a comprehensive expert matrix covering essential visual comprehension elements; 2) A dynamic knowledge fusion strategy featuring progressive pre-alignment to harmonize experts within the VLM latent space through contrastive learning, complemented by probabilistically activated stochastic residual connections to preserve knowledge continuity; 3) An enhanced optimization framework utilizing momentum contrastive learning for long-range dependency modeling and adaptive weight allocators for real-time expert contribution calibration. Extensive evaluations across 12 benchmark tasks spanning VQA, image captioning, and cross-modal retrieval demonstrate Astrea's superiority over state-of-the-art models, achieving an average performance gain of +4.7\%. This study provides the first empirical demonstration that progressive pre-alignment strategies enable VLMs to overcome task heterogeneity limitations, establishing new methodological foundations for developing general-purpose multimodal agents.
InSerter: Speech Instruction Following with Unsupervised Interleaved Pre-training
Mar 04, 2025



Recent advancements in speech large language models (SpeechLLMs) have attracted considerable attention. Nonetheless, current methods exhibit suboptimal performance in adhering to speech instructions. Notably, the intelligence of models significantly diminishes when processing speech-form input as compared to direct text-form input. Prior work has attempted to mitigate this semantic inconsistency between speech and text representations through techniques such as representation and behavior alignment, which involve the meticulous design of data pairs during the post-training phase. In this paper, we introduce a simple and scalable training method called InSerter, which stands for Interleaved Speech-Text Representation Pre-training. InSerter is designed to pre-train large-scale unsupervised speech-text sequences, where the speech is synthesized from randomly selected segments of an extensive text corpus using text-to-speech conversion. Consequently, the model acquires the ability to generate textual continuations corresponding to the provided speech segments, obviating the need for intensive data design endeavors. To systematically evaluate speech instruction-following capabilities, we introduce SpeechInstructBench, the first comprehensive benchmark specifically designed for speech-oriented instruction-following tasks. Our proposed InSerter achieves SOTA performance in SpeechInstructBench and demonstrates superior or competitive results across diverse speech processing tasks.
UniCodec: Unified Audio Codec with Single Domain-Adaptive Codebook
Feb 27, 2025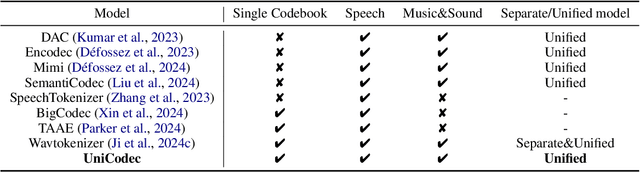

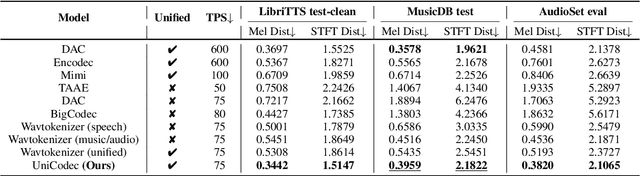
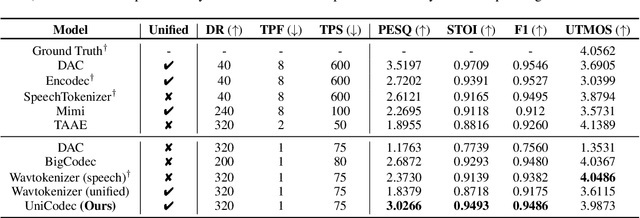
The emergence of audio language models is empowered by neural audio codecs, which establish critical mappings between continuous waveforms and discrete tokens compatible with language model paradigms. The evolutionary trends from multi-layer residual vector quantizer to single-layer quantizer are beneficial for language-autoregressive decoding. However, the capability to handle multi-domain audio signals through a single codebook remains constrained by inter-domain distribution discrepancies. In this work, we introduce UniCodec, a unified audio codec with a single codebook to support multi-domain audio data, including speech, music, and sound. To achieve this, we propose a partitioned domain-adaptive codebook method and domain Mixture-of-Experts strategy to capture the distinct characteristics of each audio domain. Furthermore, to enrich the semantic density of the codec without auxiliary modules, we propose a self-supervised mask prediction modeling approach. Comprehensive objective and subjective evaluations demonstrate that UniCodec achieves excellent audio reconstruction performance across the three audio domains, outperforming existing unified neural codecs with a single codebook, and even surpasses state-of-the-art domain-specific codecs on both acoustic and semantic representation capabilities.
Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis
Feb 26, 2025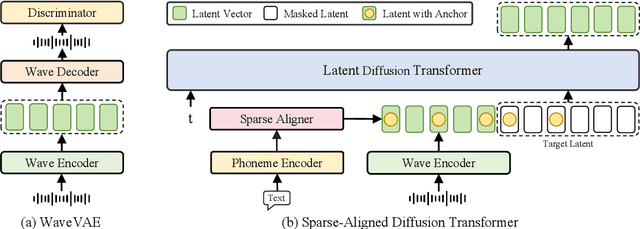
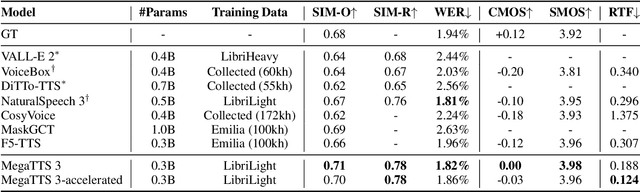
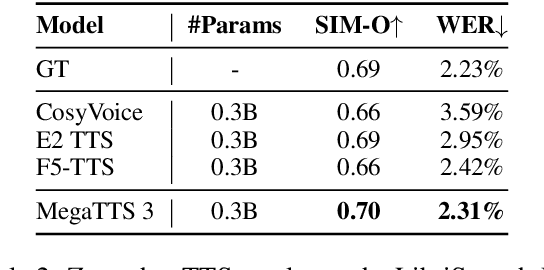

While recent zero-shot text-to-speech (TTS) models have significantly improved speech quality and expressiveness, mainstream systems still suffer from issues related to speech-text alignment modeling: 1) models without explicit speech-text alignment modeling exhibit less robustness, especially for hard sentences in practical applications; 2) predefined alignment-based models suffer from naturalness constraints of forced alignments. This paper introduces \textit{S-DiT}, a TTS system featuring an innovative sparse alignment algorithm that guides the latent diffusion transformer (DiT). Specifically, we provide sparse alignment boundaries to S-DiT to reduce the difficulty of alignment learning without limiting the search space, thereby achieving high naturalness. Moreover, we employ a multi-condition classifier-free guidance strategy for accent intensity adjustment and adopt the piecewise rectified flow technique to accelerate the generation process. Experiments demonstrate that S-DiT achieves state-of-the-art zero-shot TTS speech quality and supports highly flexible control over accent intensity. Notably, our system can generate high-quality one-minute speech with only 8 sampling steps. Audio samples are available at https://sditdemo.github.io/sditdemo/.
WavRAG: Audio-Integrated Retrieval Augmented Generation for Spoken Dialogue Models
Feb 20, 2025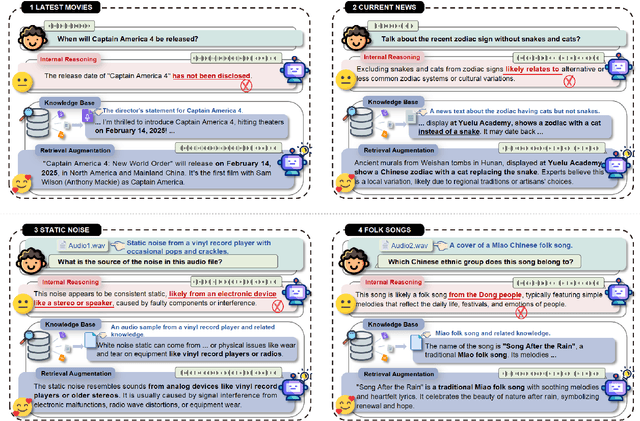
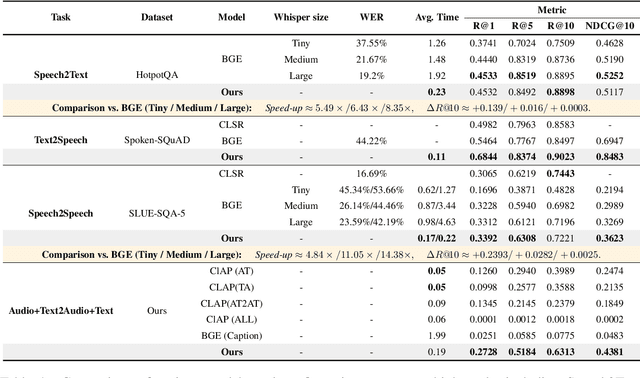
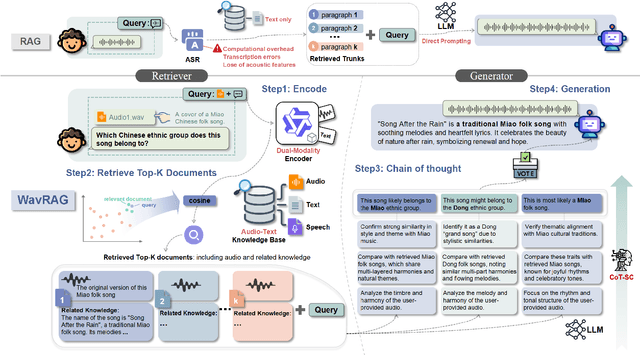
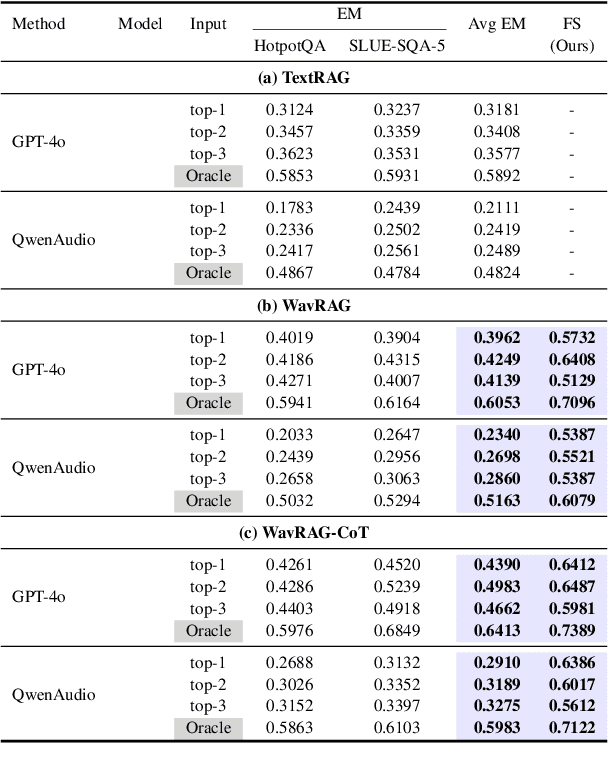
Retrieval Augmented Generation (RAG) has gained widespread adoption owing to its capacity to empower large language models (LLMs) to integrate external knowledge. However, existing RAG frameworks are primarily designed for text-based LLMs and rely on Automatic Speech Recognition to process speech input, which discards crucial audio information, risks transcription errors, and increases computational overhead. Therefore, we introduce WavRAG, the first retrieval augmented generation framework with native, end-to-end audio support. WavRAG offers two key features: 1) Bypassing ASR, WavRAG directly processes raw audio for both embedding and retrieval. 2) WavRAG integrates audio and text into a unified knowledge representation. Specifically, we propose the WavRetriever to facilitate the retrieval from a text-audio hybrid knowledge base, and further enhance the in-context capabilities of spoken dialogue models through the integration of chain-of-thought reasoning. In comparison to state-of-the-art ASR-Text RAG pipelines, WavRAG achieves comparable retrieval performance while delivering a 10x acceleration. Furthermore, WavRAG's unique text-audio hybrid retrieval capability extends the boundaries of RAG to the audio modality.