 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROGLE: Robust Global-Local Alignment with Automated Region Supervision for Text-Based Person Search
Jun 01, 2026Text-Based Person Search (TBPS) aims to retrieve pedestrian images using natural language queries. However, existing TBPS models, especially those based on CLIP, struggle with fine-grained understanding due to global representational bias and semantic sparsity inherited from training on short captions. This results in weak fine-grained alignment, exacerbated by the scarcity of region-level annotations. To address this, we propose ROGLE (Robust Global-Local Embedding), a unified framework that overcomes reliance on costly manual annotations through an automated Region-to-Sentence Matching (RSM) strategy. RSM automatically mines pseudo region-sentence pairs for scalable fine-grained supervision. Furthermore, ROGLE employs a multi-granular learning strategy that fuses global contrastive learning with region-level local alignment. We also introduce the P-VLG Benchmark, a large-scale dataset constructed by curating and enriching images from established public benchmarks. It features over 100,000 annotated regions and rich long-form captions, making it the first TBPS benchmark to support both global and local assessment protocols. Extensive experiments show that ROGLE significantly outperforms existing approaches, particularly on challenging long-form queries. Code and the P-VLG benchmark will be made publicly available.
Seedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Chat-Driven Text Generation and Interaction for Person Retrieval
Sep 16, 2025Text-based person search (TBPS) enables the retrieval of person images from large-scale databases using natural language descriptions, offering critical value in surveillance applications. However, a major challenge lies in the labor-intensive process of obtaining high-quality textual annotations, which limits scalability and practical deployment. To address this, we introduce two complementary modules: Multi-Turn Text Generation (MTG) and Multi-Turn Text Interaction (MTI). MTG generates rich pseudo-labels through simulated dialogues with MLLMs, producing fine-grained and diverse visual descriptions without manual supervision. MTI refines user queries at inference time through dynamic, dialogue-based reasoning, enabling the system to interpret and resolve vague, incomplete, or ambiguous descriptions - characteristics often seen in real-world search scenarios. Together, MTG and MTI form a unified and annotation-free framework that significantly improves retrieval accuracy, robustness, and usability. Extensive evaluations demonstrate that our method achieves competitive or superior results while eliminating the need for manual captions, paving the way for scalable and practical deployment of TBPS systems.
TAP: Parameter-efficient Task-Aware Prompting for Adverse Weather Removal
Aug 11, 2025Image restoration under adverse weather conditions has been extensively explored, leading to numerous high-performance methods. In particular, recent advances in All-in-One approaches have shown impressive results by training on multi-task image restoration datasets. However, most of these methods rely on dedicated network modules or parameters for each specific degradation type, resulting in a significant parameter overhead. Moreover, the relatedness across different restoration tasks is often overlooked. In light of these issues, we propose a parameter-efficient All-in-One image restoration framework that leverages task-aware enhanced prompts to tackle various adverse weather degradations.Specifically, we adopt a two-stage training paradigm consisting of a pretraining phase and a prompt-tuning phase to mitigate parameter conflicts across tasks. We first employ supervised learning to acquire general restoration knowledge, and then adapt the model to handle specific degradation via trainable soft prompts. Crucially, we enhance these task-specific prompts in a task-aware manner. We apply low-rank decomposition to these prompts to capture both task-general and task-specific characteristics, and impose contrastive constraints to better align them with the actual inter-task relatedness. These enhanced prompts not only improve the parameter efficiency of the restoration model but also enable more accurate task modeling, as evidenced by t-SNE analysis. Experimental results on different restoration tasks demonstrate that the proposed method achieves superior performance with only 2.75M parameters.
IRBridge: Solving Image Restoration Bridge with Pre-trained Generative Diffusion Models
May 30, 2025Bridge models in image restoration construct a diffusion process from degraded to clear images. However, existing methods typically require training a bridge model from scratch for each specific type of degradation, resulting in high computational costs and limited performance. This work aims to efficiently leverage pretrained generative priors within existing image restoration bridges to eliminate this requirement. The main challenge is that standard generative models are typically designed for a diffusion process that starts from pure noise, while restoration tasks begin with a low-quality image, resulting in a mismatch in the state distributions between the two processes. To address this challenge, we propose a transition equation that bridges two diffusion processes with the same endpoint distribution. Based on this, we introduce the IRBridge framework, which enables the direct utilization of generative models within image restoration bridges, offering a more flexible and adaptable approach to image restoration. Extensive experiments on six image restoration tasks demonstrate that IRBridge efficiently integrates generative priors, resulting in improved robustness and generalization performance. Code will be available at GitHub.
Semantic Residual for Multimodal Unified Discrete Representation
Dec 26, 2024Recent research in the domain of multimodal unified representations predominantly employs codebook as representation forms, utilizing Vector Quantization(VQ) for quantization, yet there has been insufficient exploration of other quantization representation forms. Our work explores more precise quantization methods and introduces a new framework, Semantic Residual Cross-modal Information Disentanglement (SRCID), inspired by the numerical residual concept inherent to Residual Vector Quantization (RVQ). SRCID employs semantic residual-based information disentanglement for multimodal data to better handle the inherent discrepancies between different modalities. Our method enhances the capabilities of unified multimodal representations and demonstrates exceptional performance in cross-modal generalization and cross-modal zero-shot retrieval. Its average results significantly surpass existing state-of-the-art models, as well as previous attempts with RVQ and Finite Scalar Quantization (FSQ) based on these modals.
Unlocking the Potential of Multimodal Unified Discrete Representation through Training-Free Codebook Optimization and Hierarchical Alignment
Mar 08, 2024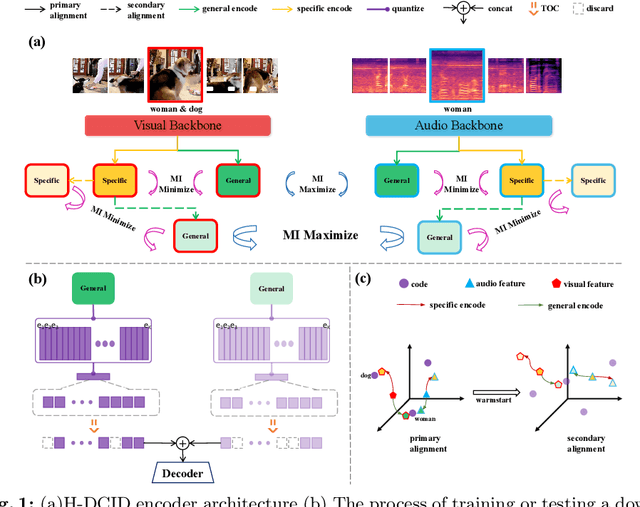
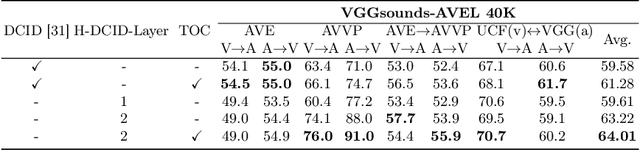
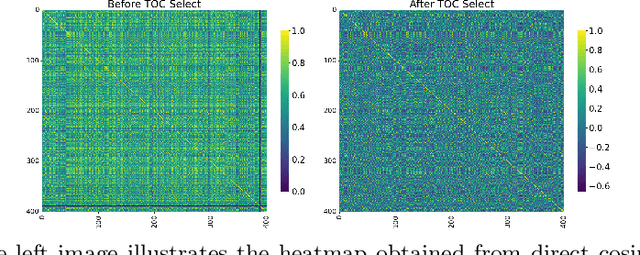
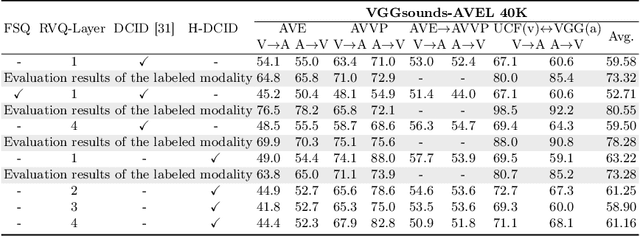
Recent advances in representation learning have demonstrated the significance of multimodal alignment. The Dual Cross-modal Information Disentanglement (DCID) model, utilizing a unified codebook, shows promising results in achieving fine-grained representation and cross-modal generalization. However, it is still hindered by equal treatment of all channels and neglect of minor event information, resulting in interference from irrelevant channels and limited performance in fine-grained tasks. Thus, in this work, We propose a Training-free Optimization of Codebook (TOC) method to enhance model performance by selecting important channels in the unified space without retraining. Additionally, we introduce the Hierarchical Dual Cross-modal Information Disentanglement (H-DCID) approach to extend information separation and alignment to two levels, capturing more cross-modal details. The experiment results demonstrate significant improvements across various downstream tasks, with TOC contributing to an average improvement of 1.70% for DCID on four tasks, and H-DCID surpassing DCID by an average of 3.64%. The combination of TOC and H-DCID further enhances performance, exceeding DCID by 4.43%. These findings highlight the effectiveness of our methods in facilitating robust and nuanced cross-modal learning, opening avenues for future enhancements. The source code and pre-trained models can be accessed at https://github.com/haihuangcode/TOC_H-DCID.
Language-Codec: Reducing the Gaps Between Discrete Codec Representation and Speech Language Models
Feb 20, 2024In recent years, large language models have achieved significant success in generative tasks (e.g., speech cloning and audio generation) related to speech, audio, music, and other signal domains. A crucial element of these models is the discrete acoustic codecs, which serves as an intermediate representation replacing the mel-spectrogram. However, there exist several gaps between discrete codecs and downstream speech language models. Specifically, 1) most codec models are trained on only 1,000 hours of data, whereas most speech language models are trained on 60,000 hours; 2) Achieving good reconstruction performance requires the utilization of numerous codebooks, which increases the burden on downstream speech language models; 3) The initial channel of the codebooks contains excessive information, making it challenging to directly generate acoustic tokens from weakly supervised signals such as text in downstream tasks. Consequently, leveraging the characteristics of speech language models, we propose Language-Codec. In the Language-Codec, we introduce a Mask Channel Residual Vector Quantization (MCRVQ) mechanism along with improved Fourier transform structures and larger training datasets to address the aforementioned gaps. We compare our method with competing audio compression algorithms and observe significant outperformance across extensive evaluations. Furthermore, we also validate the efficiency of the Language-Codec on downstream speech language models. The source code and pre-trained models can be accessed at https://github.com/jishengpeng/languagecodec .
On Linear Separation Capacity of Self-Supervised Representation Learning
Oct 29, 2023
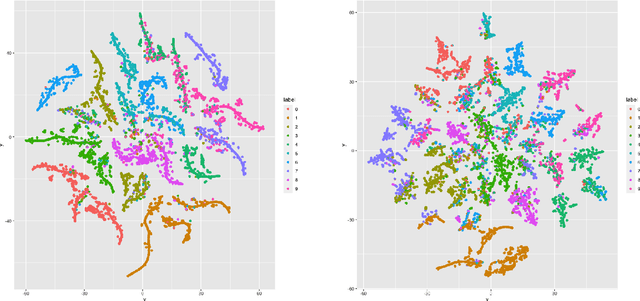

Recent advances in self-supervised learning have highlighted the efficacy of data augmentation in learning data representation from unlabeled data. Training a linear model atop these enhanced representations can yield an adept classifier. Despite the remarkable empirical performance, the underlying mechanisms that enable data augmentation to unravel nonlinear data structures into linearly separable representations remain elusive. This paper seeks to bridge this gap by investigating under what conditions learned representations can linearly separate manifolds when data is drawn from a multi-manifold model. Our investigation reveals that data augmentation offers additional information beyond observed data and can thus improve the information-theoretic optimal rate of linear separation capacity. In particular, we show that self-supervised learning can linearly separate manifolds with a smaller distance than unsupervised learning, underscoring the additional benefits of data augmentation. Our theoretical analysis further underscores that the performance of downstream linear classifiers primarily hinges on the linear separability of data representations rather than the size of the labeled data set, reaffirming the viability of constructing efficient classifiers with limited labeled data amid an expansive unlabeled data set.
Augmentation Invariant Manifold Learning
Nov 01, 2022



Data augmentation is a widely used technique and an essential ingredient in the recent advance in self-supervised representation learning. By preserving the similarity between augmented data, the resulting data representation can improve various downstream analyses and achieve state-of-art performance in many applications. To demystify the role of data augmentation, we develop a statistical framework on a low-dimension product manifold to theoretically understand why the unlabeled augmented data can lead to useful data representation. Under this framework, we propose a new representation learning method called augmentation invariant manifold learning and develop the corresponding loss function, which can work with a deep neural network to learn data representations. Compared with existing methods, the new data representation simultaneously exploits the manifold's geometric structure and invariant property of augmented data. Our theoretical investigation precisely characterizes how the data representation learned from augmented data can improve the $k$-nearest neighbor classifier in the downstream analysis, showing that a more complex data augmentation leads to more improvement in downstream analysis. Finally, numerical experiments on simulated and real datasets are presented to support the theoretical results in this paper.