 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProving the Coding Interview: A Benchmark for Formally Verified Code Generation
Feb 08, 2025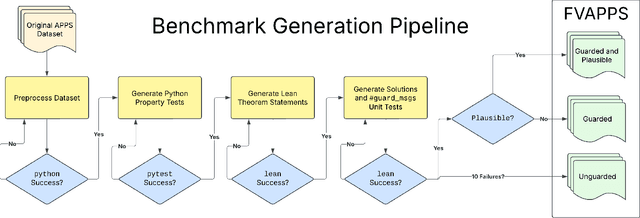

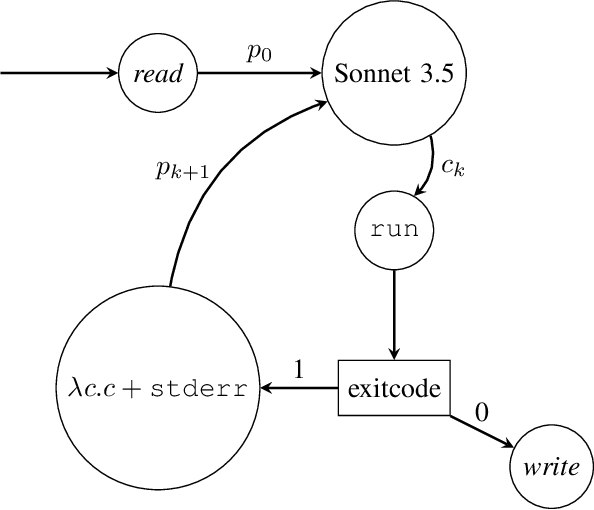
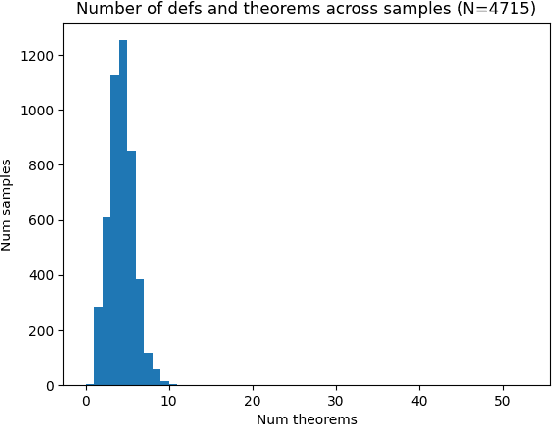
We introduce the Formally Verified Automated Programming Progress Standards, or FVAPPS, a benchmark of 4715 samples for writing programs and proving their correctness, the largest formal verification benchmark, including 1083 curated and quality controlled samples. Previously, APPS provided a benchmark and dataset for programming puzzles to be completed in Python and checked against unit tests, of the kind seen in technical assessments in the software engineering industry. Building upon recent approaches for benchmarks in interactive theorem proving, we generalize the unit tests to Lean 4 theorems given without proof (i.e., using Lean's "sorry" keyword). On the 406 theorems of 100 randomly selected samples, Sonnet correctly proves 30% and Gemini correctly proves 18%. We challenge the machine learning and program synthesis communities to solve both each general purpose programming problem and its associated correctness specifications. The benchmark is available at https://huggingface.co/datasets/quinn-dougherty/fvapps.
The Benefits of Balance: From Information Projections to Variance Reduction
Aug 27, 2024



Data balancing across multiple modalities/sources appears in various forms in several foundation models (e.g., CLIP and DINO) achieving universal representation learning. We show that this iterative algorithm, usually used to avoid representation collapse, enjoys an unsuspected benefit: reducing the variance of estimators that are functionals of the empirical distribution over these sources. We provide non-asymptotic bounds quantifying this variance reduction effect and relate them to the eigendecays of appropriately defined Markov operators. We explain how various forms of data balancing in contrastive multimodal learning and self-supervised clustering can be interpreted as instances of this variance reduction scheme.
A Primal-Dual Algorithm for Faster Distributionally Robust Optimization
Mar 16, 2024



We consider the penalized distributionally robust optimization (DRO) problem with a closed, convex uncertainty set, a setting that encompasses the $f$-DRO, Wasserstein-DRO, and spectral/$L$-risk formulations used in practice. We present Drago, a stochastic primal-dual algorithm that achieves a state-of-the-art linear convergence rate on strongly convex-strongly concave DRO problems. The method combines both randomized and cyclic components with mini-batching, which effectively handles the unique asymmetric nature of the primal and dual problems in DRO. We support our theoretical results with numerical benchmarks in classification and regression.
Distributionally Robust Optimization with Bias and Variance Reduction
Oct 21, 2023



We consider the distributionally robust optimization (DRO) problem with spectral risk-based uncertainty set and $f$-divergence penalty. This formulation includes common risk-sensitive learning objectives such as regularized condition value-at-risk (CVaR) and average top-$k$ loss. We present Prospect, a stochastic gradient-based algorithm that only requires tuning a single learning rate hyperparameter, and prove that it enjoys linear convergence for smooth regularized losses. This contrasts with previous algorithms that either require tuning multiple hyperparameters or potentially fail to converge due to biased gradient estimates or inadequate regularization. Empirically, we show that Prospect can converge 2-3$\times$ faster than baselines such as stochastic gradient and stochastic saddle-point methods on distribution shift and fairness benchmarks spanning tabular, vision, and language domains.
Stochastic Optimization for Spectral Risk Measures
Dec 10, 2022



Spectral risk objectives - also called $L$-risks - allow for learning systems to interpolate between optimizing average-case performance (as in empirical risk minimization) and worst-case performance on a task. We develop stochastic algorithms to optimize these quantities by characterizing their subdifferential and addressing challenges such as biasedness of subgradient estimates and non-smoothness of the objective. We show theoretically and experimentally that out-of-the-box approaches such as stochastic subgradient and dual averaging are hindered by bias and that our approach outperforms them.
Deep Unlearning via Randomized Conditionally Independent Hessians
Apr 15, 2022
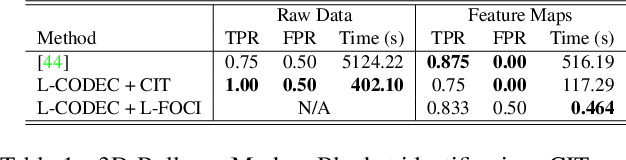


Recent legislation has led to interest in machine unlearning, i.e., removing specific training samples from a predictive model as if they never existed in the training dataset. Unlearning may also be required due to corrupted/adversarial data or simply a user's updated privacy requirement. For models which require no training (k-NN), simply deleting the closest original sample can be effective. But this idea is inapplicable to models which learn richer representations. Recent ideas leveraging optimization-based updates scale poorly with the model dimension d, due to inverting the Hessian of the loss function. We use a variant of a new conditional independence coefficient, L-CODEC, to identify a subset of the model parameters with the most semantic overlap on an individual sample level. Our approach completely avoids the need to invert a (possibly) huge matrix. By utilizing a Markov blanket selection, we premise that L-CODEC is also suitable for deep unlearning, as well as other applications in vision. Compared to alternatives, L-CODEC makes approximate unlearning possible in settings that would otherwise be infeasible, including vision models used for face recognition, person re-identification and NLP models that may require unlearning samples identified for exclusion. Code can be found at https://github.com/vsingh-group/LCODEC-deep-unlearning/
Towards a theory of out-of-distribution learning
Oct 07, 2021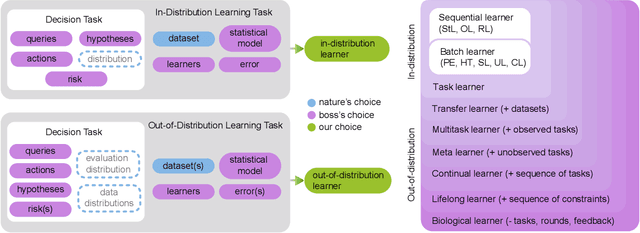
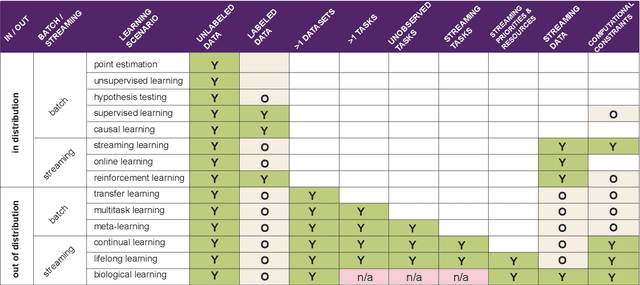
What is learning? 20$^{st}$ century formalizations of learning theory -- which precipitated revolutions in artificial intelligence -- focus primarily on $\mathit{in-distribution}$ learning, that is, learning under the assumption that the training data are sampled from the same distribution as the evaluation distribution. This assumption renders these theories inadequate for characterizing 21$^{st}$ century real world data problems, which are typically characterized by evaluation distributions that differ from the training data distributions (referred to as out-of-distribution learning). We therefore make a small change to existing formal definitions of learnability by relaxing that assumption. We then introduce $\mathbf{learning\ efficiency}$ (LE) to quantify the amount a learner is able to leverage data for a given problem, regardless of whether it is an in- or out-of-distribution problem. We then define and prove the relationship between generalized notions of learnability, and show how this framework is sufficiently general to characterize transfer, multitask, meta, continual, and lifelong learning. We hope this unification helps bridge the gap between empirical practice and theoretical guidance in real world problems. Finally, because biological learning continues to outperform machine learning algorithms on certain OOD challenges, we discuss the limitations of this framework vis-\'a-vis its ability to formalize biological learning, suggesting multiple avenues for future research.
DUAL-GLOW: Conditional Flow-Based Generative Model for Modality Transfer
Aug 21, 2019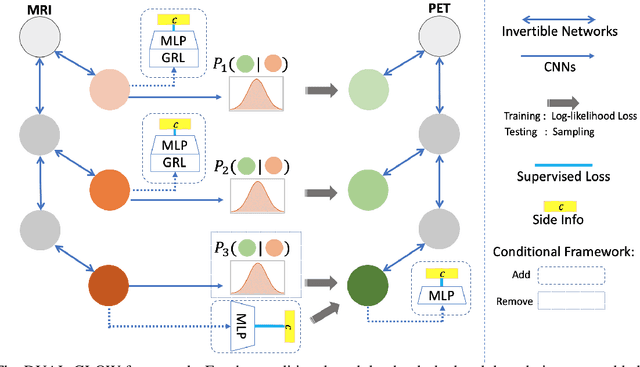


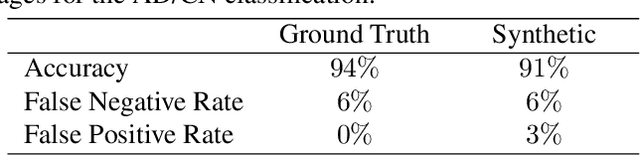
Positron emission tomography (PET) imaging is an imaging modality for diagnosing a number of neurological diseases. In contrast to Magnetic Resonance Imaging (MRI), PET is costly and involves injecting a radioactive substance into the patient. Motivated by developments in modality transfer in vision, we study the generation of certain types of PET images from MRI data. We derive new flow-based generative models which we show perform well in this small sample size regime (much smaller than dataset sizes available in standard vision tasks). Our formulation, DUAL-GLOW, is based on two invertible networks and a relation network that maps the latent spaces to each other. We discuss how given the prior distribution, learning the conditional distribution of PET given the MRI image reduces to obtaining the conditional distribution between the two latent codes w.r.t. the two image types. We also extend our framework to leverage 'side' information (or attributes) when available. By controlling the PET generation through 'conditioning' on age, our model is also able to capture brain FDG-PET (hypometabolism) changes, as a function of age. We present experiments on the Alzheimers Disease Neuroimaging Initiative (ADNI) dataset with 826 subjects, and obtain good performance in PET image synthesis, qualitatively and quantitatively better than recent works.
A Consistent Independence Test for Multivariate Time-Series
Aug 18, 2019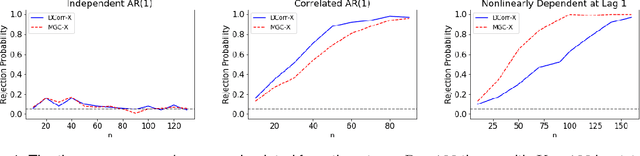
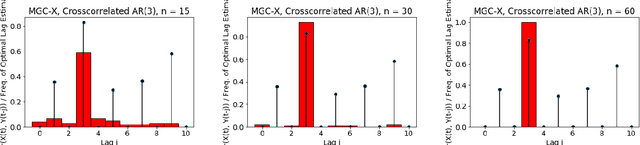
A fundamental problem in statistical data analysis is testing whether two phenomena are related. When the phenomena in question are time series, many challenges emerge. The first is defining a dependence measure between time series at the population level, as well as a sample level test statistic. The second is computing or estimating the distribution of this test statistic under the null, as the permutation test procedure is invalid for most time series structures. This work aims to address these challenges by combining distance correlation and multiscale graph correlation (MGC) from independence testing literature and block permutation testing from time series analysis. Two hypothesis tests for testing the independence of time series are proposed. These procedures also characterize whether the dependence relationship between the series is linear or nonlinear, and the time lag at which this dependence is maximized. For strictly stationary auto-regressive moving average (ARMA) processes, the proposed independence tests are proven valid and consistent. Finally, neural connectivity in the brain is analyzed using fMRI data, revealing linear dependence of signals within the visual network and default mode network, and nonlinear relationships in other regions. This work opens up new theoretical and practical directions for many modern time series analysis problems.
Resource Constrained Neural Network Architecture Search
Apr 08, 2019



The design of neural network architectures is frequently either based on human expertise using trial/error and empirical feedback or tackled via large scale reinforcement learning strategies run over distinct discrete architecture choices. In the latter case, the optimization task is non-differentiable and also not very amenable to derivative-free optimization methods. Most methods in use today require exorbitant computational resources. And if we want networks that additionally satisfy resource constraints, the above challenges are exacerbated because the search procedure must now balance accuracy with certain budget constraints on resources. We formulate this problem as the optimization of a set function - we find that the empirical behavior of this set function often (but not always) satisfies marginal gain and monotonicity principles - properties central to the idea of submodularity. Based on this observation, we adapt algorithms that are well-known within discrete optimization to obtain heuristic schemes for neural network architecture search, with resource constraints on the architecture. This simple scheme when applied on CIFAR-100 and ImageNet, identifies resource-constrained architectures with quantifiably better performance than current state-of-the-art models designed for mobile devices. Specifically, we find high-performing architectures with fewer parameters and computations by a search method that is much faster.