 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHARP: Sleep-based Hierarchical Accelerated Replay for Long Range Non-Stationary Temporal Pattern Recognition
May 30, 2026Learning long-range non-stationary temporal patterns remains a core challenge for modern sequence models, particularly in strict streaming settings. In these settings, data arrive sequentially and must be processed in a single pass without simultaneously revisiting past observations. Standard architectures, including recurrent neural networks and transformers, are constrained by either truncated backpropagation through time horizon or explicit input window length for long range credit assignment. To address these limitations, we propose SHARP (Sleep-based Hierarchical Accelerated Replay), a framework that decomposes temporal learning into two complementary components: a memory module that accumulates a structured history of past inputs, and a pattern-recognition module that operates over this memory. This separation enables resource- and compute-efficient adaptation to non-stationary dynamics by eliminating the need for backpropagation through time across many steps for long-range credit assignment. Inspired by the accelerated replay observed in rodents during slow-wave sleep, SHARP incorporates offline (sleep) phases in which temporally structured memory traces are replayed in an accelerated form and integrated into higher-level memory representations, improving long-range context retention. Through controlled simulations and ablation studies, we characterize the key properties of the proposed framework. In benchmark datasets such as text8 and PG-19, we demonstrate that SHARP improves over recurrent baselines by retaining next-token predictive performance on previously seen data while continuing to learn from the current stream and generalizing to future unseen data. These gains are enabled by its hierarchical structure, which yields an exponentially increasing effective temporal context with only linear-time computational cost.
Out-of-distribution and in-distribution posterior calibration using Kernel Density Polytopes
Feb 14, 2022

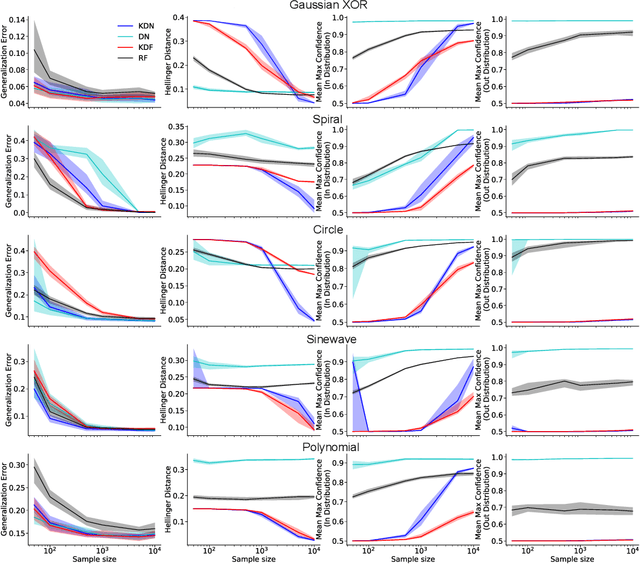
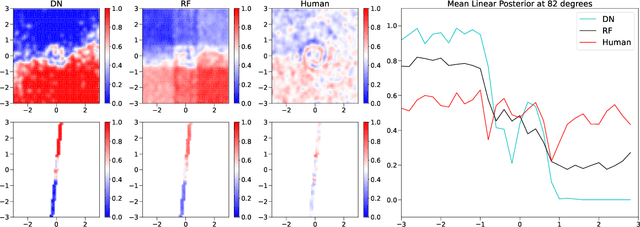
Any reasonable machine learning (ML) model should not only interpolate efficiently in between the training samples provided (in-distribution region), but also approach the extrapolative or out-of-distribution (OOD) region without being overconfident. Our experiment on human subjects justifies the aforementioned properties for human intelligence as well. Many state-of-the-art algorithms have tried to fix the overconfidence problem of ML models in the OOD region. However, in doing so, they have often impaired the in-distribution performance of the model. Our key insight is that ML models partition the feature space into polytopes and learn constant (random forests) or affine (ReLU networks) functions over those polytopes. This leads to the OOD overconfidence problem for the polytopes which lie in the training data boundary and extend to infinity. To resolve this issue, we propose kernel density methods that fit Gaussian kernel over the polytopes, which are learned using ML models. Specifically, we introduce two variants of kernel density polytopes: Kernel Density Forest (KDF) and Kernel Density Network (KDN) based on random forests and deep networks, respectively. Studies on various simulation settings show that both KDF and KDN achieve uniform confidence over the classes in the OOD region while maintaining good in-distribution accuracy compared to that of their respective parent models.
Prospective Learning: Back to the Future
Jan 19, 2022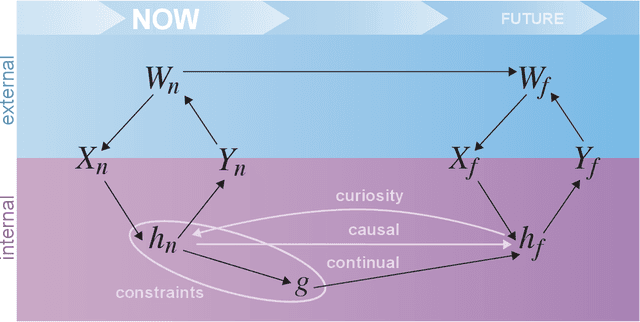

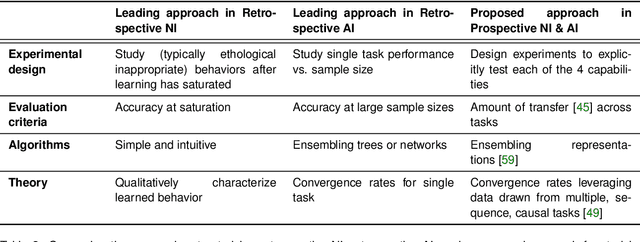
Research on both natural intelligence (NI) and artificial intelligence (AI) generally assumes that the future resembles the past: intelligent agents or systems (what we call 'intelligence') observe and act on the world, then use this experience to act on future experiences of the same kind. We call this 'retrospective learning'. For example, an intelligence may see a set of pictures of objects, along with their names, and learn to name them. A retrospective learning intelligence would merely be able to name more pictures of the same objects. We argue that this is not what true intelligence is about. In many real world problems, both NIs and AIs will have to learn for an uncertain future. Both must update their internal models to be useful for future tasks, such as naming fundamentally new objects and using these objects effectively in a new context or to achieve previously unencountered goals. This ability to learn for the future we call 'prospective learning'. We articulate four relevant factors that jointly define prospective learning. Continual learning enables intelligences to remember those aspects of the past which it believes will be most useful in the future. Prospective constraints (including biases and priors) facilitate the intelligence finding general solutions that will be applicable to future problems. Curiosity motivates taking actions that inform future decision making, including in previously unmet situations. Causal estimation enables learning the structure of relations that guide choosing actions for specific outcomes, even when the specific action-outcome contingencies have never been observed before. We argue that a paradigm shift from retrospective to prospective learning will enable the communities that study intelligence to unite and overcome existing bottlenecks to more effectively explain, augment, and engineer intelligences.
Streaming Decision Trees and Forests
Oct 16, 2021
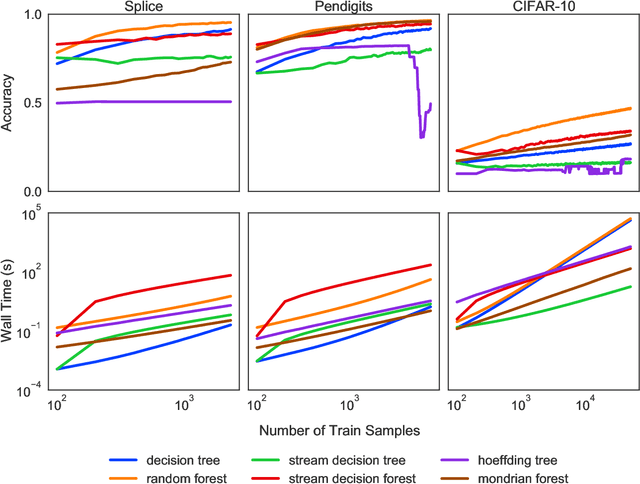
Machine learning has successfully leveraged modern data and provided computational solutions to innumerable real-world problems, including physical and biomedical discoveries. Currently, estimators could handle both scenarios with all samples available and situations requiring continuous updates. However, there is still room for improvement on streaming algorithms based on batch decision trees and random forests, which are the leading methods in batch data tasks. In this paper, we explore the simplest partial fitting algorithm to extend batch trees and test our models: stream decision tree (SDT) and stream decision forest (SDF) on three classification tasks of varying complexities. For reference, both existing streaming trees (Hoeffding trees and Mondrian forests) and batch estimators are included in the experiments. In all three tasks, SDF consistently produces high accuracy, whereas existing estimators encounter space restraints and accuracy fluctuations. Thus, our streaming trees and forests show great potential for further improvements, which are good candidates for solving problems like distribution drift and transfer learning.
Towards a theory of out-of-distribution learning
Oct 07, 2021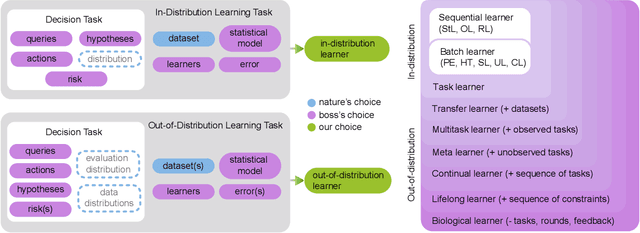
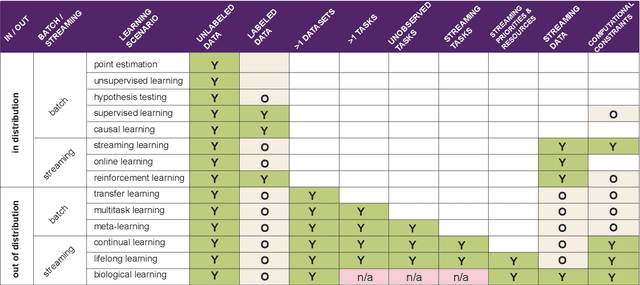
What is learning? 20$^{st}$ century formalizations of learning theory -- which precipitated revolutions in artificial intelligence -- focus primarily on $\mathit{in-distribution}$ learning, that is, learning under the assumption that the training data are sampled from the same distribution as the evaluation distribution. This assumption renders these theories inadequate for characterizing 21$^{st}$ century real world data problems, which are typically characterized by evaluation distributions that differ from the training data distributions (referred to as out-of-distribution learning). We therefore make a small change to existing formal definitions of learnability by relaxing that assumption. We then introduce $\mathbf{learning\ efficiency}$ (LE) to quantify the amount a learner is able to leverage data for a given problem, regardless of whether it is an in- or out-of-distribution problem. We then define and prove the relationship between generalized notions of learnability, and show how this framework is sufficiently general to characterize transfer, multitask, meta, continual, and lifelong learning. We hope this unification helps bridge the gap between empirical practice and theoretical guidance in real world problems. Finally, because biological learning continues to outperform machine learning algorithms on certain OOD challenges, we discuss the limitations of this framework vis-\'a-vis its ability to formalize biological learning, suggesting multiple avenues for future research.
A general approach to progressive learning
Apr 28, 2020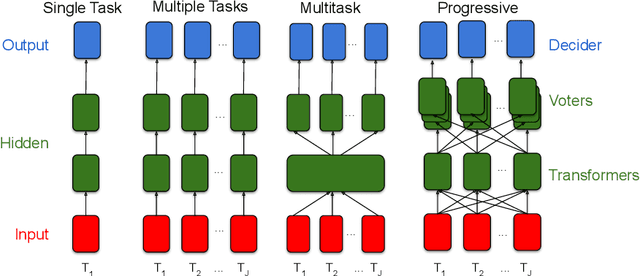
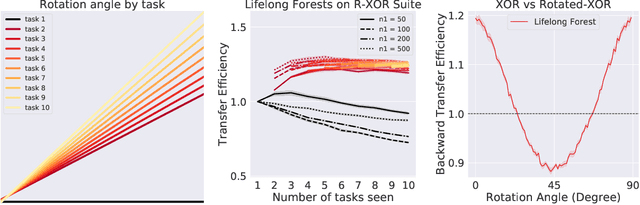

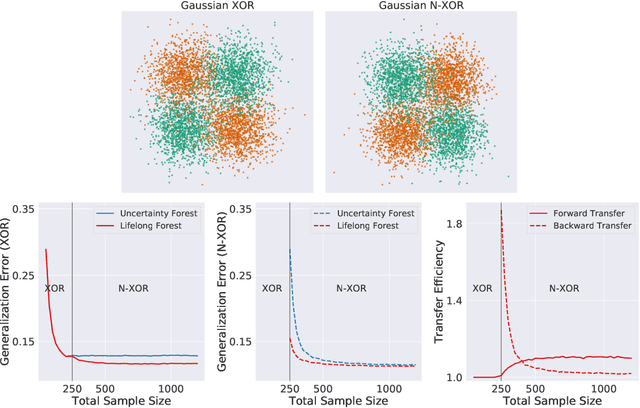
In biological learning, data is used to improve performance on the task at hand, while simultaneously improving performance on both previously encountered tasks and as yet unconsidered future tasks. In contrast, classical machine learning starts from a blank slate, or tabula rasa, using data only for the single task at hand. While typical transfer learning algorithms can improve performance on future tasks, their performance degrades upon learning new tasks. Many recent approaches have attempted to mitigate this issue, called catastrophic forgetting, to maintain performance given new tasks. But striving to avoid forgetting sets the goal unnecessarily low: the goal of progressive learning, whether biological or artificial, is to improve performance on all tasks (including past and future) with any new data. We propose a general approach to progressive learning that ensembles representations, rather than learners. We show that ensembling representations---including representations learned by decision forests or neural networks---enables both forward and backward transfer on a variety of simulated and real data tasks, including vision, language, and adversarial tasks. This work suggests that further improvements in progressive learning may follow from a deeper understanding of how biological learning achieves such high degrees of efficiency.
Location Forensics of Media Recordings Utilizing Cascaded SVM and Pole-matching Classifiers
Dec 01, 2019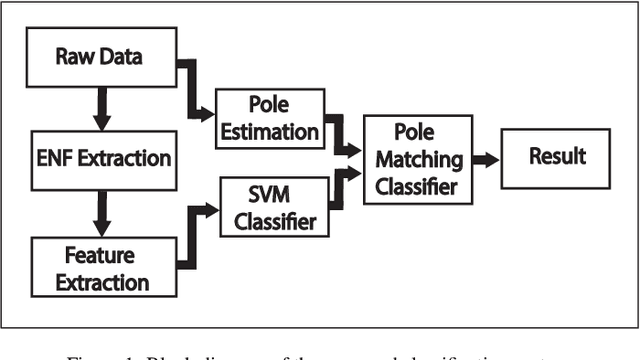


Information regarding the location of power distribution grid can be extracted from the power signature embedded in the multimedia signals (e.g., audio, video data) recorded near electrical activities. This implicit mechanism of identifying the origin-of-recording can be a very promising tool for multimedia forensics and security applications. In this work, we have developed a novel grid-of-origin identification system from media recording that consists of a number of support vector machine (SVM) followed by pole-matching (PM) classifiers. First, we determine the nominal frequency of the grid (50 or 60 Hz) based on the spectral observation. Then an SVM classifier, trained for the detection of a grid with a particular nominal frequency, narrows down the list of possible grids on the basis of different discriminating features extracted from the electric network frequency (ENF) signal. The decision of the SVM classifier is then passed to the PM classifier that detects the final grid based on the minimum distance between the estimated poles of test and training grids. Thus, we start from the problem of classifying grids with different nominal frequencies and simplify the problem of classification in three stages based on nominal frequency, SVM and finally using PM classifier. This cascaded system of classification ensures better accuracy (15.57% higher) compared to traditional ENF-based SVM classifiers described in the literature.
An Ensemble SVM-based Approach for Voice Activity Detection
Feb 05, 2019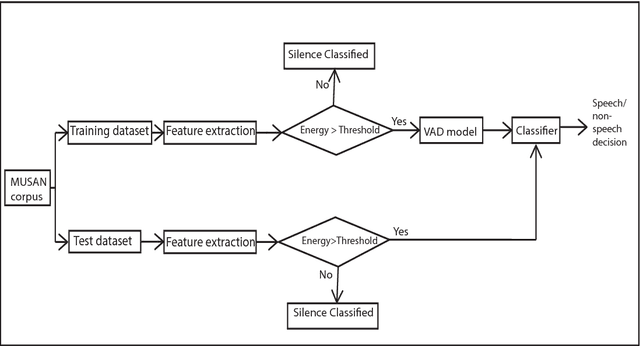
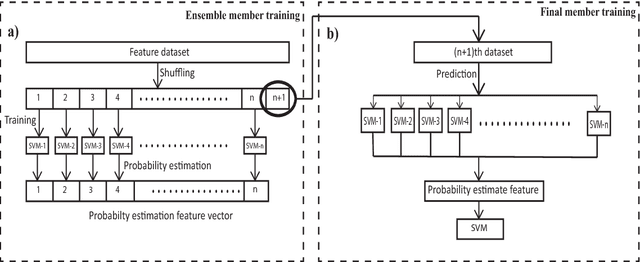
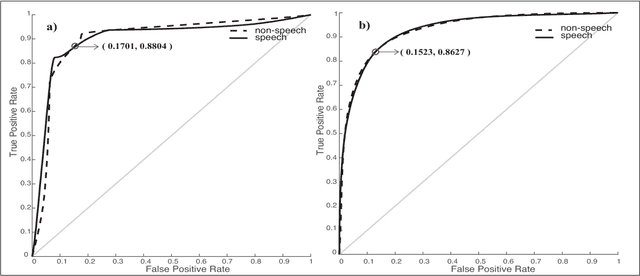

Voice activity detection (VAD), used as the front end of speech enhancement, speech and speaker recognition algorithms, determines the overall accuracy and efficiency of the algorithms. Therefore, a VAD with low complexity and high accuracy is highly desirable for speech processing applications. In this paper, we propose a novel training method on large dataset for supervised learning-based VAD system using support vector machine (SVM). Despite of high classification accuracy of support vector machines (SVM), trivial SVM is not suitable for classification of large data sets needed for a good VAD system because of high training complexity. To overcome this problem, a novel ensemble-based approach using SVM has been proposed in this paper.The performance of the proposed ensemble structure has been compared with a feedforward neural network (NN). Although NN performs better than single SVM-based VAD trained on a small portion of the training data, ensemble SVM gives accuracy comparable to neural network-based VAD. Ensemble SVM and NN give 88.74% and 86.28% accuracy respectively whereas the stand-alone SVM shows 57.05% accuracy on average on the test dataset.