 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
Nov 28, 2023
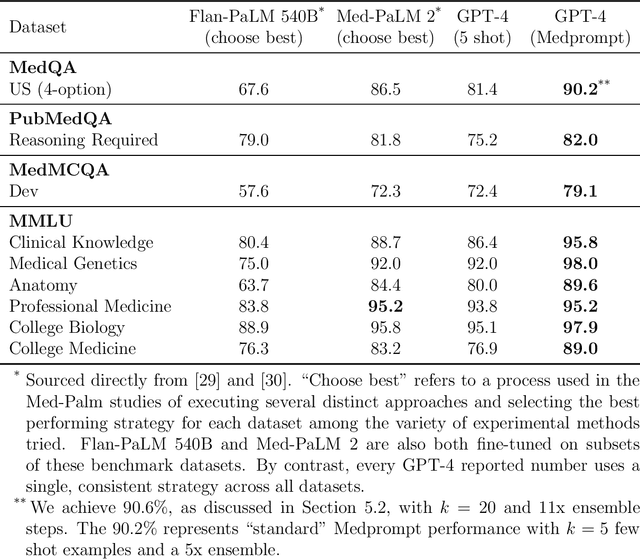


Generalist foundation models such as GPT-4 have displayed surprising capabilities in a wide variety of domains and tasks. Yet, there is a prevalent assumption that they cannot match specialist capabilities of fine-tuned models. For example, most explorations to date on medical competency benchmarks have leveraged domain-specific training, as exemplified by efforts on BioGPT and Med-PaLM. We build on a prior study of GPT-4's capabilities on medical challenge benchmarks in the absence of special training. Rather than using simple prompting to highlight the model's out-of-the-box capabilities, we perform a systematic exploration of prompt engineering. We find that prompting innovation can unlock deeper specialist capabilities and show that GPT-4 easily tops prior leading results for medical benchmarks. The prompting methods we explore are general purpose, and make no specific use of domain expertise, removing the need for expert-curated content. Our experimental design carefully controls for overfitting during the prompt engineering process. We introduce Medprompt, based on a composition of several prompting strategies. With Medprompt, GPT-4 achieves state-of-the-art results on all nine of the benchmark datasets in the MultiMedQA suite. The method outperforms leading specialist models such as Med-PaLM 2 by a significant margin with an order of magnitude fewer calls to the model. Steering GPT-4 with Medprompt achieves a 27% reduction in error rate on the MedQA dataset over the best methods to date achieved with specialist models and surpasses a score of 90% for the first time. Beyond medical problems, we show the power of Medprompt to generalize to other domains and provide evidence for the broad applicability of the approach via studies of the strategy on exams in electrical engineering, machine learning, philosophy, accounting, law, nursing, and clinical psychology.
Beyond One-Model-Fits-All: A Survey of Domain Specialization for Large Language Models
May 31, 2023



Large language models (LLMs) have significantly advanced the field of natural language processing (NLP), providing a highly useful, task-agnostic foundation for a wide range of applications. The great promise of LLMs as general task solvers motivated people to extend their functionality largely beyond just a ``chatbot'', and use it as an assistant or even replacement for domain experts and tools in specific domains such as healthcare, finance, and education. However, directly applying LLMs to solve sophisticated problems in specific domains meets many hurdles, caused by the heterogeneity of domain data, the sophistication of domain knowledge, the uniqueness of domain objectives, and the diversity of the constraints (e.g., various social norms, cultural conformity, religious beliefs, and ethical standards in the domain applications). To fill such a gap, explosively-increase research, and practices have been conducted in very recent years on the domain specialization of LLMs, which, however, calls for a comprehensive and systematic review to better summarizes and guide this promising domain. In this survey paper, first, we propose a systematic taxonomy that categorizes the LLM domain-specialization techniques based on the accessibility to LLMs and summarizes the framework for all the subcategories as well as their relations and differences to each other. We also present a comprehensive taxonomy of critical application domains that can benefit from specialized LLMs, discussing their practical significance and open challenges. Furthermore, we offer insights into the current research status and future trends in this area.
Prospective Learning: Back to the Future
Jan 19, 2022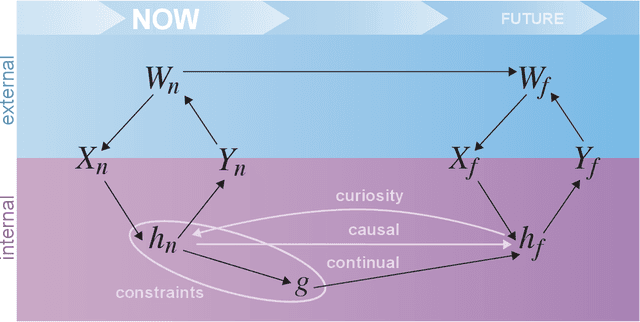

Research on both natural intelligence (NI) and artificial intelligence (AI) generally assumes that the future resembles the past: intelligent agents or systems (what we call 'intelligence') observe and act on the world, then use this experience to act on future experiences of the same kind. We call this 'retrospective learning'. For example, an intelligence may see a set of pictures of objects, along with their names, and learn to name them. A retrospective learning intelligence would merely be able to name more pictures of the same objects. We argue that this is not what true intelligence is about. In many real world problems, both NIs and AIs will have to learn for an uncertain future. Both must update their internal models to be useful for future tasks, such as naming fundamentally new objects and using these objects effectively in a new context or to achieve previously unencountered goals. This ability to learn for the future we call 'prospective learning'. We articulate four relevant factors that jointly define prospective learning. Continual learning enables intelligences to remember those aspects of the past which it believes will be most useful in the future. Prospective constraints (including biases and priors) facilitate the intelligence finding general solutions that will be applicable to future problems. Curiosity motivates taking actions that inform future decision making, including in previously unmet situations. Causal estimation enables learning the structure of relations that guide choosing actions for specific outcomes, even when the specific action-outcome contingencies have never been observed before. We argue that a paradigm shift from retrospective to prospective learning will enable the communities that study intelligence to unite and overcome existing bottlenecks to more effectively explain, augment, and engineer intelligences.
Learning to rank via combining representations
May 20, 2020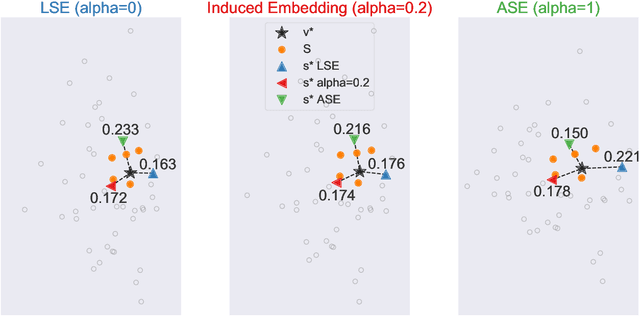
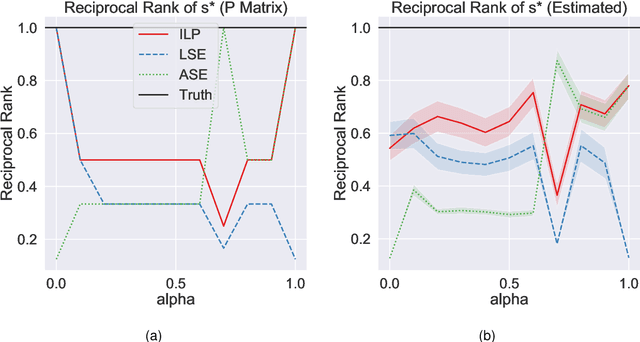
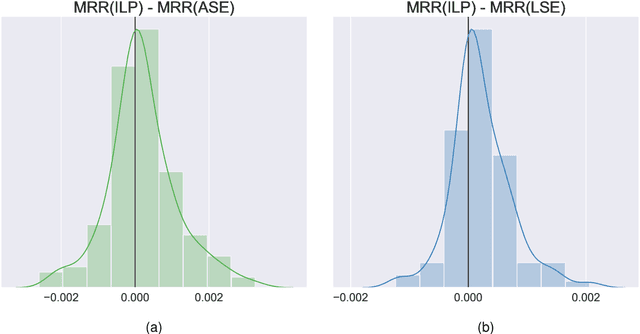
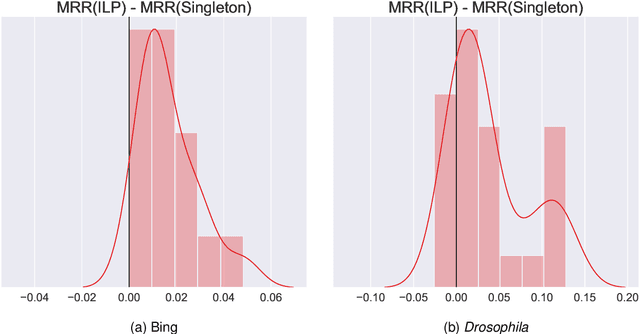
Learning to rank -- producing a ranked list of items specific to a query and with respect to a set of supervisory items -- is a problem of general interest. The setting we consider is one in which no analytic description of what constitutes a good ranking is available. Instead, we have a collection of representations and supervisory information consisting of a (target item, interesting items set) pair. We demonstrate -- analytically, in simulation, and in real data examples -- that learning to rank via combining representations using an integer linear program is effective when the supervision is as light as "these few items are similar to your item of interest." While this nomination task is of general interest, for specificity we present our methodology from the perspective of vertex nomination in graphs. The methodology described herein is model agnostic.
A general approach to progressive learning
Apr 28, 2020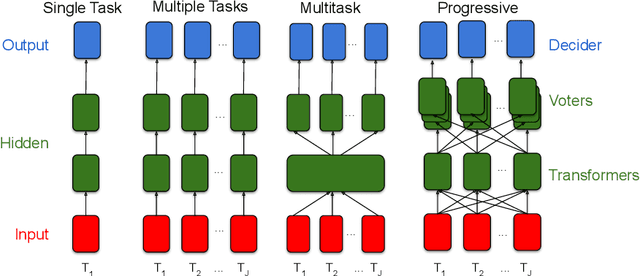
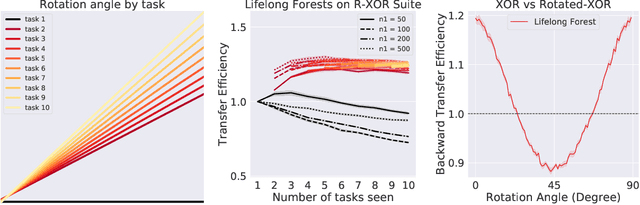

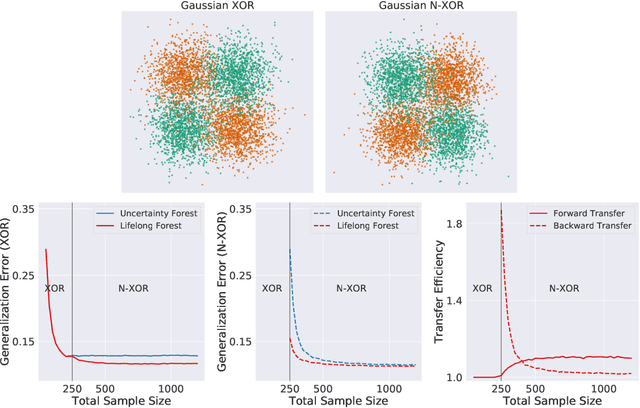
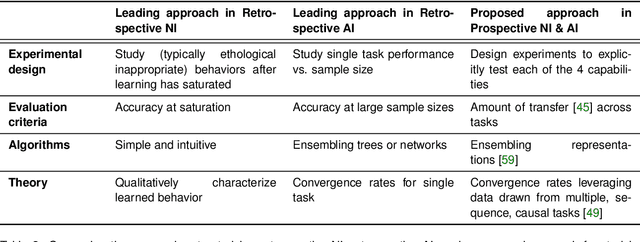
In biological learning, data is used to improve performance on the task at hand, while simultaneously improving performance on both previously encountered tasks and as yet unconsidered future tasks. In contrast, classical machine learning starts from a blank slate, or tabula rasa, using data only for the single task at hand. While typical transfer learning algorithms can improve performance on future tasks, their performance degrades upon learning new tasks. Many recent approaches have attempted to mitigate this issue, called catastrophic forgetting, to maintain performance given new tasks. But striving to avoid forgetting sets the goal unnecessarily low: the goal of progressive learning, whether biological or artificial, is to improve performance on all tasks (including past and future) with any new data. We propose a general approach to progressive learning that ensembles representations, rather than learners. We show that ensembling representations---including representations learned by decision forests or neural networks---enables both forward and backward transfer on a variety of simulated and real data tasks, including vision, language, and adversarial tasks. This work suggests that further improvements in progressive learning may follow from a deeper understanding of how biological learning achieves such high degrees of efficiency.