 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Kernel Perspective Space Performance Guarantees for Synthetic Data from Transformer Models
Feb 04, 2026Scarcity of labeled training data remains the long pole in the tent for building performant language technology and generative AI models. Transformer models -- particularly LLMs -- are increasingly being used to mitigate the data scarcity problem via synthetic data generation. However, because the models are black boxes, the properties of the synthetic data are difficult to predict. In practice it is common for language technology engineers to 'fiddle' with the LLM temperature setting and hope that what comes out the other end improves the downstream model. Faced with this uncertainty, here we propose Data Kernel Perspective Space (DKPS) to provide the foundation for mathematical analysis yielding concrete statistical guarantees for the quality of the outputs of transformer models. We first show the mathematical derivation of DKPS and how it provides performance guarantees. Next we show how DKPS performance guarantees can elucidate performance of a downstream task, such as neural machine translation models or LLMs trained using Contrastive Preference Optimization (CPO). Limitations of the current work and future research are also discussed.
Concentration bounds on response-based vector embeddings of black-box generative models
Nov 11, 2025
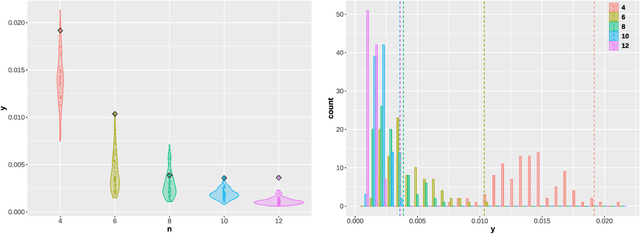

Generative models, such as large language models or text-to-image diffusion models, can generate relevant responses to user-given queries. Response-based vector embeddings of generative models facilitate statistical analysis and inference on a given collection of black-box generative models. The Data Kernel Perspective Space embedding is one particular method of obtaining response-based vector embeddings for a given set of generative models, already discussed in the literature. In this paper, under appropriate regularity conditions, we establish high probability concentration bounds on the sample vector embeddings for a given set of generative models, obtained through the method of Data Kernel Perspective Space embedding. Our results tell us the required number of sample responses needed in order to approximate the population-level vector embeddings with a desired level of accuracy. The algebraic tools used to establish our results can be used further for establishing concentration bounds on Classical Multidimensional Scaling embeddings in general, when the dissimilarities are observed with noise.
Graph Neural Networks Powered by Encoder Embedding for Improved Node Learning
Jul 15, 2025Graph neural networks (GNNs) have emerged as a powerful framework for a wide range of node-level graph learning tasks. However, their performance is often constrained by reliance on random or minimally informed initial feature representations, which can lead to slow convergence and suboptimal solutions. In this paper, we leverage a statistically grounded method, one-hot graph encoder embedding (GEE), to generate high-quality initial node features that enhance the end-to-end training of GNNs. We refer to this integrated framework as the GEE-powered GNN (GG), and demonstrate its effectiveness through extensive simulations and real-world experiments across both unsupervised and supervised settings. In node clustering, GG consistently achieves state-of-the-art performance, ranking first across all evaluated real-world datasets, while exhibiting faster convergence compared to the standard GNN. For node classification, we further propose an enhanced variant, GG-C, which concatenates the outputs of GG and GEE and outperforms competing baselines. These results confirm the importance of principled, structure-aware feature initialization in realizing the full potential of GNNs.
Principal Graph Encoder Embedding and Principal Community Detection
Jan 24, 2025In this paper, we introduce the concept of principal communities and propose a principal graph encoder embedding method that concurrently detects these communities and achieves vertex embedding. Given a graph adjacency matrix with vertex labels, the method computes a sample community score for each community, ranking them to measure community importance and estimate a set of principal communities. The method then produces a vertex embedding by retaining only the dimensions corresponding to these principal communities. Theoretically, we define the population version of the encoder embedding and the community score based on a random Bernoulli graph distribution. We prove that the population principal graph encoder embedding preserves the conditional density of the vertex labels and that the population community score successfully distinguishes the principal communities. We conduct a variety of simulations to demonstrate the finite-sample accuracy in detecting ground-truth principal communities, as well as the advantages in embedding visualization and subsequent vertex classification. The method is further applied to a set of real-world graphs, showcasing its numerical advantages, including robustness to label noise and computational scalability.
Embedding-based statistical inference on generative models
Oct 01, 2024



The recent cohort of publicly available generative models can produce human expert level content across a variety of topics and domains. Given a model in this cohort as a base model, methods such as parameter efficient fine-tuning, in-context learning, and constrained decoding have further increased generative capabilities and improved both computational and data efficiency. Entire collections of derivative models have emerged as a byproduct of these methods and each of these models has a set of associated covariates such as a score on a benchmark, an indicator for if the model has (or had) access to sensitive information, etc. that may or may not be available to the user. For some model-level covariates, it is possible to use "similar" models to predict an unknown covariate. In this paper we extend recent results related to embedding-based representations of generative models -- the data kernel perspective space -- to classical statistical inference settings. We demonstrate that using the perspective space as the basis of a notion of "similar" is effective for multiple model-level inference tasks.
Tracking the perspectives of interacting language models
Jun 17, 2024Large language models (LLMs) are capable of producing high quality information at unprecedented rates. As these models continue to entrench themselves in society, the content they produce will become increasingly pervasive in databases that are, in turn, incorporated into the pre-training data, fine-tuning data, retrieval data, etc. of other language models. In this paper we formalize the idea of a communication network of LLMs and introduce a method for representing the perspective of individual models within a collection of LLMs. Given these tools we systematically study information diffusion in the communication network of LLMs in various simulated settings.
Semisupervised regression in latent structure networks on unknown manifolds
May 04, 2023Random graphs are increasingly becoming objects of interest for modeling networks in a wide range of applications. Latent position random graph models posit that each node is associated with a latent position vector, and that these vectors follow some geometric structure in the latent space. In this paper, we consider random dot product graphs, in which an edge is formed between two nodes with probability given by the inner product of their respective latent positions. We assume that the latent position vectors lie on an unknown one-dimensional curve and are coupled with a response covariate via a regression model. Using the geometry of the underlying latent position vectors, we propose a manifold learning and graph embedding technique to predict the response variable on out-of-sample nodes, and we establish convergence guarantees for these responses. Our theoretical results are supported by simulations and an application to Drosophila brain data.
Discovering Communication Pattern Shifts in Large-Scale Networks using Encoder Embedding and Vertex Dynamics
May 03, 2023The analysis of large-scale time-series network data, such as social media and email communications, remains a significant challenge for graph analysis methodology. In particular, the scalability of graph analysis is a critical issue hindering further progress in large-scale downstream inference. In this paper, we introduce a novel approach called "temporal encoder embedding" that can efficiently embed large amounts of graph data with linear complexity. We apply this method to an anonymized time-series communication network from a large organization spanning 2019-2020, consisting of over 100 thousand vertices and 80 million edges. Our method embeds the data within 10 seconds on a standard computer and enables the detection of communication pattern shifts for individual vertices, vertex communities, and the overall graph structure. Through supporting theory and synthesis studies, we demonstrate the theoretical soundness of our approach under random graph models and its numerical effectiveness through simulation studies.
Graph Encoder Ensemble for Simultaneous Vertex Embedding and Community Detection
Jan 18, 2023In this paper we propose a novel and computationally efficient method to simultaneously achieve vertex embedding, community detection, and community size determination. By utilizing a normalized one-hot graph encoder and a new rank-based cluster size measure, the proposed graph encoder ensemble algorithm achieves excellent numerical performance throughout a variety of simulations and real data experiments.
Dynamic Network Sampling for Community Detection
Aug 29, 2022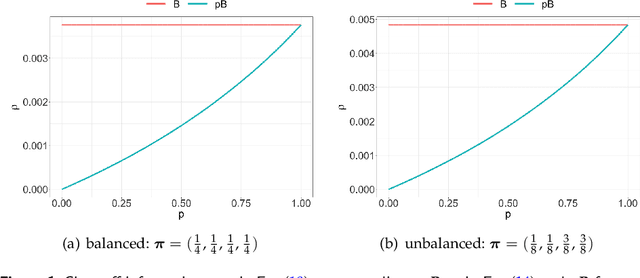
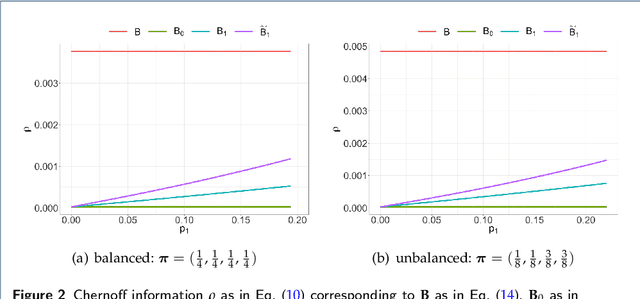
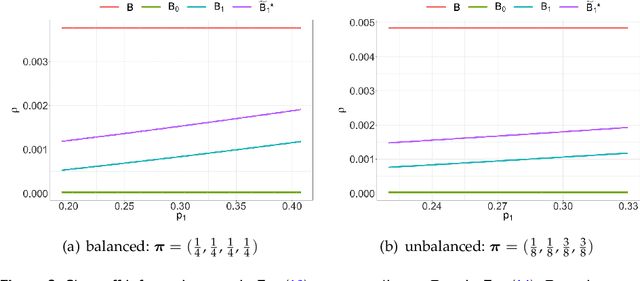
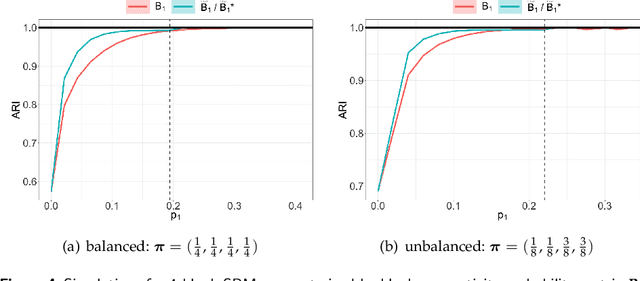
We propose a dynamic network sampling scheme to optimize block recovery for stochastic blockmodel (SBM) in the case where it is prohibitively expensive to observe the entire graph. Theoretically, we provide justification of our proposed Chernoff-optimal dynamic sampling scheme via the Chernoff information. Practically, we evaluate the performance, in terms of block recovery, of our method on several real datasets from different domains. Both theoretically and practically results suggest that our method can identify vertices that have the most impact on block structure so that one can only check whether there are edges between them to save significant resources but still recover the block structure.