 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNOMAD Projection
May 21, 2025The rapid adoption of generative AI has driven an explosion in the size of datasets consumed and produced by AI models. Traditional methods for unstructured data visualization, such as t-SNE and UMAP, have not kept up with the pace of dataset scaling. This presents a significant challenge for AI explainability, which relies on methods such as t-SNE and UMAP for exploratory data analysis. In this paper, we introduce Negative Or Mean Affinity Discrimination (NOMAD) Projection, the first method for unstructured data visualization via nonlinear dimensionality reduction that can run on multiple GPUs at train time. We provide theory that situates NOMAD Projection as an approximate upper bound on the InfoNC-t-SNE loss, and empirical results that demonstrate NOMAD Projection's superior performance and speed profile compared to existing state-of-the-art methods. We demonstrate the scalability of NOMAD Projection by computing the first complete data map of Multilingual Wikipedia.
Repurposing the scientific literature with vision-language models
Feb 26, 2025Research in AI for Science often focuses on using AI technologies to augment components of the scientific process, or in some cases, the entire scientific method; how about AI for scientific publications? Peer-reviewed journals are foundational repositories of specialized knowledge, written in discipline-specific language that differs from general Internet content used to train most large language models (LLMs) and vision-language models (VLMs). We hypothesized that by combining a family of scientific journals with generative AI models, we could invent novel tools for scientific communication, education, and clinical care. We converted 23,000 articles from Neurosurgery Publications into a multimodal database - NeuroPubs - of 134 million words and 78,000 image-caption pairs to develop six datasets for building AI models. We showed that the content of NeuroPubs uniquely represents neurosurgery-specific clinical contexts compared with broader datasets and PubMed. For publishing, we employed generalist VLMs to automatically generate graphical abstracts from articles. Editorial board members rated 70% of these as ready for publication without further edits. For education, we generated 89,587 test questions in the style of the ABNS written board exam, which trainee and faculty neurosurgeons found indistinguishable from genuine examples 54% of the time. We used these questions alongside a curriculum learning process to track knowledge acquisition while training our 34 billion-parameter VLM (CNS-Obsidian). In a blinded, randomized controlled trial, we demonstrated the non-inferiority of CNS-Obsidian to GPT-4o (p = 0.1154) as a diagnostic copilot for a neurosurgical service. Our findings lay a novel foundation for AI with Science and establish a framework to elevate scientific communication using state-of-the-art generative artificial intelligence while maintaining rigorous quality standards.
Training Sparse Mixture Of Experts Text Embedding Models
Feb 11, 2025Transformer-based text embedding models have improved their performance on benchmarks like MIRACL and BEIR by increasing their parameter counts. However, this scaling approach introduces significant deployment challenges, including increased inference latency and memory usage. These challenges are particularly severe in retrieval-augmented generation (RAG) applications, where large models' increased memory requirements constrain dataset ingestion capacity, and their higher latency directly impacts query-time performance. While causal language models have addressed similar efficiency challenges using Mixture of Experts (MoE) architectures, this approach hasn't been successfully adapted to the general text embedding setting. In this paper, we introduce Nomic Embed v2, the first general purpose MoE text embedding model. Our model outperforms models in the same parameter class on both monolingual and multilingual benchmarks while also maintaining competitive performance with models twice its size. We open-source all code, models, and evaluation data to ensure full reproducibility of our training pipeline.
CoRNStack: High-Quality Contrastive Data for Better Code Ranking
Dec 01, 2024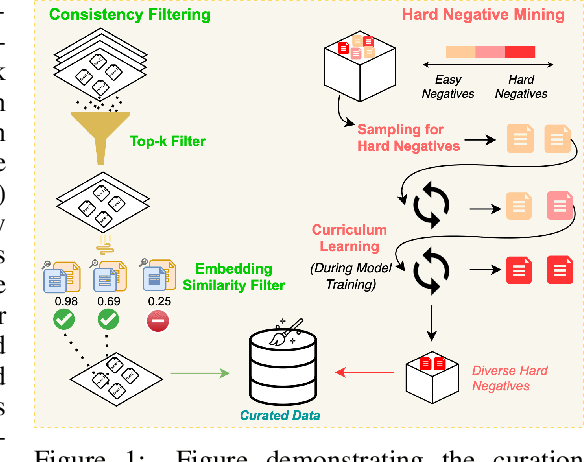

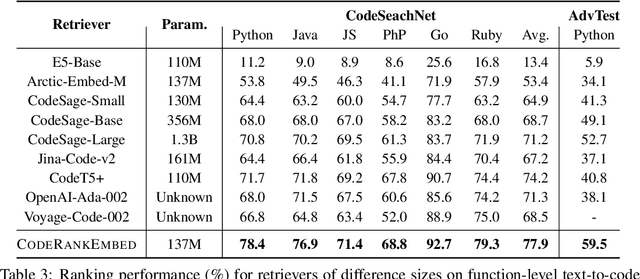

Effective code retrieval plays a crucial role in advancing code generation, bug fixing, and software maintenance, particularly as software systems increase in complexity. While current code embedding models have demonstrated promise in retrieving code snippets for small-scale, well-defined tasks, they often underperform in more demanding real-world applications such as bug localization within GitHub repositories. We hypothesize that a key issue is their reliance on noisy and inconsistent datasets for training, which impedes their ability to generalize to more complex retrieval scenarios. To address these limitations, we introduce CoRNStack, a large-scale, high-quality contrastive training dataset for code that spans multiple programming languages. This dataset is curated using consistency filtering to eliminate noisy positives and is further enriched with mined hard negatives, thereby facilitating more effective learning. We demonstrate that contrastive training of embedding models using CoRNStack leads to state-of-the-art performance across a variety of code retrieval tasks. Furthermore, the dataset can be leveraged for training code reranking models, a largely underexplored area compared to text reranking. Our finetuned code reranking model significantly improves the ranking quality over the retrieved results. Finally, by employing our code retriever and reranker together, we demonstrate significant improvements in function localization for GitHub issues, an important component of real-world software development.
Embedding-based statistical inference on generative models
Oct 01, 2024



The recent cohort of publicly available generative models can produce human expert level content across a variety of topics and domains. Given a model in this cohort as a base model, methods such as parameter efficient fine-tuning, in-context learning, and constrained decoding have further increased generative capabilities and improved both computational and data efficiency. Entire collections of derivative models have emerged as a byproduct of these methods and each of these models has a set of associated covariates such as a score on a benchmark, an indicator for if the model has (or had) access to sensitive information, etc. that may or may not be available to the user. For some model-level covariates, it is possible to use "similar" models to predict an unknown covariate. In this paper we extend recent results related to embedding-based representations of generative models -- the data kernel perspective space -- to classical statistical inference settings. We demonstrate that using the perspective space as the basis of a notion of "similar" is effective for multiple model-level inference tasks.
Tracking the perspectives of interacting language models
Jun 17, 2024Large language models (LLMs) are capable of producing high quality information at unprecedented rates. As these models continue to entrench themselves in society, the content they produce will become increasingly pervasive in databases that are, in turn, incorporated into the pre-training data, fine-tuning data, retrieval data, etc. of other language models. In this paper we formalize the idea of a communication network of LLMs and introduce a method for representing the perspective of individual models within a collection of LLMs. Given these tools we systematically study information diffusion in the communication network of LLMs in various simulated settings.
Nomic Embed: Training a Reproducible Long Context Text Embedder
Feb 02, 2024



This technical report describes the training of nomic-embed-text-v1, the first fully reproducible, open-source, open-weights, open-data, 8192 context length English text embedding model that outperforms both OpenAI Ada-002 and OpenAI text-embedding-3-small on short and long-context tasks. We release the training code and model weights under an Apache 2 license. In contrast with other open-source models, we release a training data loader with 235 million curated text pairs that allows for the full replication of nomic-embed-text-v1. You can find code and data to replicate the model at https://github.com/nomic-ai/contrastors
GPT4All: An Ecosystem of Open Source Compressed Language Models
Nov 06, 2023Large language models (LLMs) have recently achieved human-level performance on a range of professional and academic benchmarks. The accessibility of these models has lagged behind their performance. State-of-the-art LLMs require costly infrastructure; are only accessible via rate-limited, geo-locked, and censored web interfaces; and lack publicly available code and technical reports. In this paper, we tell the story of GPT4All, a popular open source repository that aims to democratize access to LLMs. We outline the technical details of the original GPT4All model family, as well as the evolution of the GPT4All project from a single model into a fully fledged open source ecosystem. It is our hope that this paper acts as both a technical overview of the original GPT4All models as well as a case study on the subsequent growth of the GPT4All open source ecosystem.
Comparing Foundation Models using Data Kernels
May 18, 2023


Recent advances in self-supervised learning and neural network scaling have enabled the creation of large models, known as foundation models, which can be easily adapted to a wide range of downstream tasks. The current paradigm for comparing foundation models involves evaluating them with aggregate metrics on various benchmark datasets. This method of model comparison is heavily dependent on the chosen evaluation metric, which makes it unsuitable for situations where the ideal metric is either not obvious or unavailable. In this work, we present a methodology for directly comparing the embedding space geometry of foundation models, which facilitates model comparison without the need for an explicit evaluation metric. Our methodology is grounded in random graph theory and enables valid hypothesis testing of embedding similarity on a per-datum basis. Further, we demonstrate how our methodology can be extended to facilitate population level model comparison. In particular, we show how our framework can induce a manifold of models equipped with a distance function that correlates strongly with several downstream metrics. We remark on the utility of this population level model comparison as a first step towards a taxonomic science of foundation models.
A partition-based similarity for classification distributions
Nov 12, 2020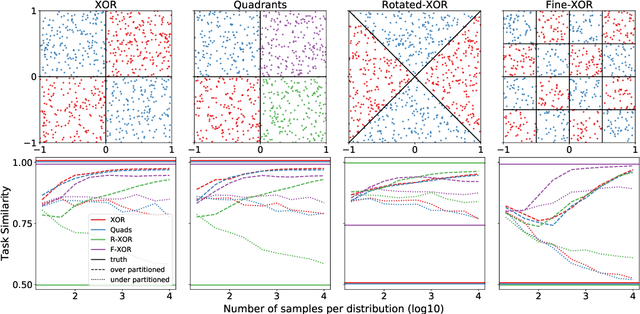
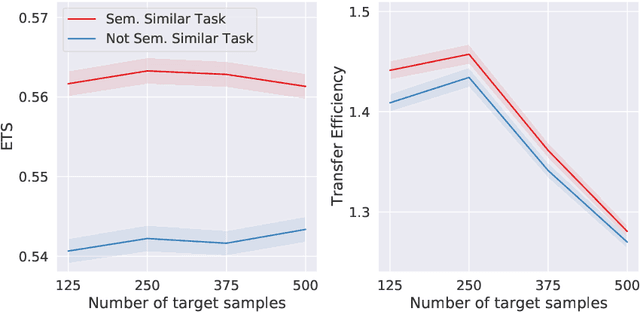
Herein we define a measure of similarity between classification distributions that is both principled from the perspective of statistical pattern recognition and useful from the perspective of machine learning practitioners. In particular, we propose a novel similarity on classification distributions, dubbed task similarity, that quantifies how an optimally-transformed optimal representation for a source distribution performs when applied to inference related to a target distribution. The definition of task similarity allows for natural definitions of adversarial and orthogonal distributions. We highlight limiting properties of representations induced by (universally) consistent decision rules and demonstrate in simulation that an empirical estimate of task similarity is a function of the decision rule deployed for inference. We demonstrate that for a given target distribution, both transfer efficiency and semantic similarity of candidate source distributions correlate with empirical task similarity.