 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSibylSense: Adaptive Rubric Learning via Memory Tuning and Adversarial Probing
Feb 24, 2026Designing aligned and robust rewards for open-ended generation remains a key barrier to RL post-training. Rubrics provide structured, interpretable supervision, but scaling rubric construction is difficult: expert rubrics are costly, prompted rubrics are often superficial or inconsistent, and fixed-pool discriminative rubrics can saturate and drift, enabling reward hacking. We present SibylSense, an inference-time learning approach that adapts a frozen rubric generator through a tunable memory bank of validated rubric items. Memory is updated via verifier-based item rewards measured by reference-candidate answer discriminative gaps from a handful of examples. SibylSense alternates memory tuning with a rubric-adversarial policy update that produces rubric-satisfying candidate answers, shrinking discriminative gaps and driving the rubric generator to capture new quality dimensions. Experiments on two open-ended tasks show that SibylSense yields more discriminative rubrics and improves downstream RL performance over static and non-adaptive baselines.
LocalBench: Benchmarking LLMs on County-Level Local Knowledge and Reasoning
Nov 17, 2025Large language models (LLMs) have been widely evaluated on macro-scale geographic tasks, such as global factual recall, event summarization, and regional reasoning. Yet, their ability to handle hyper-local knowledge remains poorly understood. This gap is increasingly consequential as real-world applications, from civic platforms to community journalism, demand AI systems that can reason about neighborhood-specific dynamics, cultural narratives, and local governance. Existing benchmarks fall short in capturing this complexity, often relying on coarse-grained data or isolated references. We present LocalBench, the first benchmark designed to systematically evaluate LLMs on county-level local knowledge across the United States. Grounded in the Localness Conceptual Framework, LocalBench includes 14,782 validated question-answer pairs across 526 U.S. counties in 49 states, integrating diverse sources such as Census statistics, local subreddit discourse, and regional news. It spans physical, cognitive, and relational dimensions of locality. Using LocalBench, we evaluate 13 state-of-the-art LLMs under both closed-book and web-augmented settings. Our findings reveal critical limitations: even the best-performing models reach only 56.8% accuracy on narrative-style questions and perform below 15.5% on numerical reasoning. Moreover, larger model size and web augmentation do not guarantee better performance, for example, search improves Gemini's accuracy by +13.6%, but reduces GPT-series performance by -11.4%. These results underscore the urgent need for language models that can support equitable, place-aware AI systems: capable of engaging with the diverse, fine-grained realities of local communities across geographic and cultural contexts.
VADTree: Explainable Training-Free Video Anomaly Detection via Hierarchical Granularity-Aware Tree
Oct 26, 2025Video anomaly detection (VAD) focuses on identifying anomalies in videos. Supervised methods demand substantial in-domain training data and fail to deliver clear explanations for anomalies. In contrast, training-free methods leverage the knowledge reserves and language interactivity of large pre-trained models to detect anomalies. However, the current fixed-length temporal window sampling approaches struggle to accurately capture anomalies with varying temporal spans. Therefore, we propose VADTree that utilizes a Hierarchical Granularityaware Tree (HGTree) structure for flexible sampling in VAD. VADTree leverages the knowledge embedded in a pre-trained Generic Event Boundary Detection (GEBD) model to characterize potential anomaly event boundaries. Specifically, VADTree decomposes the video into generic event nodes based on boundary confidence, and performs adaptive coarse-fine hierarchical structuring and redundancy removal to construct the HGTree. Then, the multi-dimensional priors are injected into the visual language models (VLMs) to enhance the node-wise anomaly perception, and anomaly reasoning for generic event nodes is achieved via large language models (LLMs). Finally, an inter-cluster node correlation method is used to integrate the multi-granularity anomaly scores. Extensive experiments on three challenging datasets demonstrate that VADTree achieves state-of-the-art performance in training-free settings while drastically reducing the number of sampled video segments. The code will be available at https://github.com/wenlongli10/VADTree.
Direct Reasoning Optimization: LLMs Can Reward And Refine Their Own Reasoning for Open-Ended Tasks
Jun 16, 2025Recent advances in Large Language Models (LLMs) have showcased impressive reasoning abilities in structured tasks like mathematics and programming, largely driven by Reinforcement Learning with Verifiable Rewards (RLVR), which uses outcome-based signals that are scalable, effective, and robust against reward hacking. However, applying similar techniques to open-ended long-form reasoning tasks remains challenging due to the absence of generic, verifiable reward signals. To address this, we propose Direct Reasoning Optimization (DRO), a reinforcement learning framework for fine-tuning LLMs on open-ended, particularly long-form, reasoning tasks, guided by a new reward signal: the Reasoning Reflection Reward (R3). At its core, R3 selectively identifies and emphasizes key tokens in the reference outcome that reflect the influence of the model's preceding chain-of-thought reasoning, thereby capturing the consistency between reasoning and reference outcome at a fine-grained level. Crucially, R3 is computed internally using the same model being optimized, enabling a fully self-contained training setup. Additionally, we introduce a dynamic data filtering strategy based on R3 for open-ended reasoning tasks, reducing cost while improving downstream performance. We evaluate DRO on two diverse datasets -- ParaRev, a long-form paragraph revision task, and FinQA, a math-oriented QA benchmark -- and show that it consistently outperforms strong baselines while remaining broadly applicable across both open-ended and structured domains.
Beamforming for Movable and Rotatable Antenna Enabled Multi-User Communications
Mar 14, 2025


In the development of wireless communication technology, multiple-input multiple-output (MIMO) technology has emerged as a key enabler, significantly enhancing the capacity of communication systems. However, traditional MIMO systems, which rely on fixed-position antennas (FPAs) with spacing limitations, cannot fully exploit the channel variations in the continuous spatial domain, thus limiting the system's spatial multiplexing performance and diversity. To address these limitations, movable antennas (MAs) have been introduced, offering a breakthrough in signal processing and spatial multiplexing by overcoming the constraints of FPA-based systems. Furthermore, this paper extends the functionality of MAs by introducing movable rotatable antennas (MRAs), which enhance the system's ability to optimize performance in the spatial domain by adding rotational degrees of freedom. By incorporating a dynamic precoding framework based on both antenna position and rotation angle optimization, and employing the zero-forcing (ZF) precoding method, this paper proposes an efficient optimization approach aimed at improving signal quality, mitigating interference, and solving the non-linear, constrained optimization problem using the sequential quadratic programming (SQP) algorithm. This approach effectively enhances the communication system's performance.
RLTHF: Targeted Human Feedback for LLM Alignment
Feb 19, 2025



Fine-tuning large language models (LLMs) to align with user preferences is challenging due to the high cost of quality human annotations in Reinforcement Learning from Human Feedback (RLHF) and the generalizability limitations of AI Feedback. To address these challenges, we propose RLTHF, a human-AI hybrid framework that combines LLM-based initial alignment with selective human annotations to achieve full-human annotation alignment with minimal effort. RLTHF identifies hard-to-annotate samples mislabeled by LLMs using a reward model's reward distribution and iteratively enhances alignment by integrating strategic human corrections while leveraging LLM's correctly labeled samples. Evaluations on HH-RLHF and TL;DR datasets show that RLTHF reaches full-human annotation-level alignment with only 6-7% of the human annotation effort. Furthermore, models trained on RLTHF's curated datasets for downstream tasks outperform those trained on fully human-annotated datasets, underscoring the effectiveness of RLTHF's strategic data curation.
CoRNStack: High-Quality Contrastive Data for Better Code Ranking
Dec 01, 2024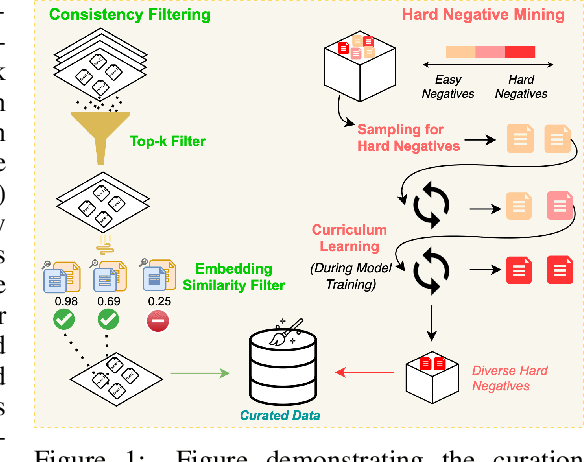

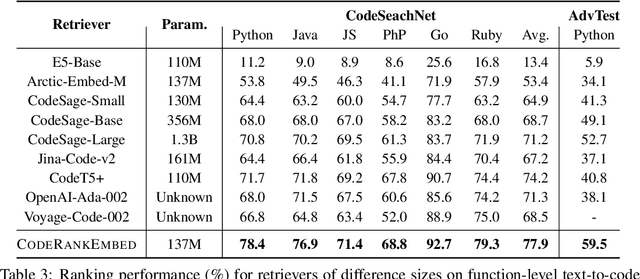

Effective code retrieval plays a crucial role in advancing code generation, bug fixing, and software maintenance, particularly as software systems increase in complexity. While current code embedding models have demonstrated promise in retrieving code snippets for small-scale, well-defined tasks, they often underperform in more demanding real-world applications such as bug localization within GitHub repositories. We hypothesize that a key issue is their reliance on noisy and inconsistent datasets for training, which impedes their ability to generalize to more complex retrieval scenarios. To address these limitations, we introduce CoRNStack, a large-scale, high-quality contrastive training dataset for code that spans multiple programming languages. This dataset is curated using consistency filtering to eliminate noisy positives and is further enriched with mined hard negatives, thereby facilitating more effective learning. We demonstrate that contrastive training of embedding models using CoRNStack leads to state-of-the-art performance across a variety of code retrieval tasks. Furthermore, the dataset can be leveraged for training code reranking models, a largely underexplored area compared to text reranking. Our finetuned code reranking model significantly improves the ranking quality over the retrieved results. Finally, by employing our code retriever and reranker together, we demonstrate significant improvements in function localization for GitHub issues, an important component of real-world software development.
System States Forecasting of Microservices with Dynamic Spatio-Temporal Data
Aug 15, 2024



In the AIOps (Artificial Intelligence for IT Operations) era, accurately forecasting system states is crucial. In microservices systems, this task encounters the challenge of dynamic and complex spatio-temporal relationships among microservice instances, primarily due to dynamic deployments, diverse call paths, and cascading effects among instances. Current time-series forecasting methods, which focus mainly on intrinsic patterns, are insufficient in environments where spatial relationships are critical. Similarly, spatio-temporal graph approaches often neglect the nature of temporal trend, concentrating mostly on message passing between nodes. Moreover, current research in microservices domain frequently underestimates the importance of network metrics and topological structures in capturing the evolving dynamics of systems. This paper introduces STMformer, a model tailored for forecasting system states in microservices environments, capable of handling multi-node and multivariate time series. Our method leverages dynamic network connection data and topological information to assist in modeling the intricate spatio-temporal relationships within the system. Additionally, we integrate the PatchCrossAttention module to compute the impact of cascading effects globally. We have developed a dataset based on a microservices system and conducted comprehensive experiments with STMformer against leading methods. In both short-term and long-term forecasting tasks, our model consistently achieved a 8.6% reduction in MAE(Mean Absolute Error) and a 2.2% reduction in MSE (Mean Squared Error). The source code is available at https://github.com/xuyifeiiie/STMformer.
FIRST: Faster Improved Listwise Reranking with Single Token Decoding
Jun 21, 2024



Large Language Models (LLMs) have significantly advanced the field of information retrieval, particularly for reranking. Listwise LLM rerankers have showcased superior performance and generalizability compared to existing supervised approaches. However, conventional listwise LLM reranking methods lack efficiency as they provide ranking output in the form of a generated ordered sequence of candidate passage identifiers. Further, they are trained with the typical language modeling objective, which treats all ranking errors uniformly--potentially at the cost of misranking highly relevant passages. Addressing these limitations, we introduce FIRST, a novel listwise LLM reranking approach leveraging the output logits of the first generated identifier to directly obtain a ranked ordering of the candidates. Further, we incorporate a learning-to-rank loss during training, prioritizing ranking accuracy for the more relevant passages. Empirical results demonstrate that FIRST accelerates inference by 50% while maintaining a robust ranking performance with gains across the BEIR benchmark. Finally, to illustrate the practical effectiveness of listwise LLM rerankers, we investigate their application in providing relevance feedback for retrievers during inference. Our results show that LLM rerankers can provide a stronger distillation signal compared to cross-encoders, yielding substantial improvements in retriever recall after relevance feedback.
Mitigate Target-level Insensitivity of Infrared Small Target Detection via Posterior Distribution Modeling
Mar 13, 2024



Infrared Small Target Detection (IRSTD) aims to segment small targets from infrared clutter background. Existing methods mainly focus on discriminative approaches, i.e., a pixel-level front-background binary segmentation. Since infrared small targets are small and low signal-to-clutter ratio, empirical risk has few disturbances when a certain false alarm and missed detection exist, which seriously affect the further improvement of such methods. Motivated by the dense prediction generative methods, in this paper, we propose a diffusion model framework for Infrared Small Target Detection which compensates pixel-level discriminant with mask posterior distribution modeling. Furthermore, we design a Low-frequency Isolation in the wavelet domain to suppress the interference of intrinsic infrared noise on the diffusion noise estimation. This transition from the discriminative paradigm to generative one enables us to bypass the target-level insensitivity. Experiments show that the proposed method achieves competitive performance gains over state-of-the-art methods on NUAA-SIRST, IRSTD-1k, and NUDT-SIRST datasets. Code are available at https://github.com/Li-Haoqing/IRSTD-Diff.