 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSibylSense: Adaptive Rubric Learning via Memory Tuning and Adversarial Probing
Feb 24, 2026Designing aligned and robust rewards for open-ended generation remains a key barrier to RL post-training. Rubrics provide structured, interpretable supervision, but scaling rubric construction is difficult: expert rubrics are costly, prompted rubrics are often superficial or inconsistent, and fixed-pool discriminative rubrics can saturate and drift, enabling reward hacking. We present SibylSense, an inference-time learning approach that adapts a frozen rubric generator through a tunable memory bank of validated rubric items. Memory is updated via verifier-based item rewards measured by reference-candidate answer discriminative gaps from a handful of examples. SibylSense alternates memory tuning with a rubric-adversarial policy update that produces rubric-satisfying candidate answers, shrinking discriminative gaps and driving the rubric generator to capture new quality dimensions. Experiments on two open-ended tasks show that SibylSense yields more discriminative rubrics and improves downstream RL performance over static and non-adaptive baselines.
Direct Reasoning Optimization: LLMs Can Reward And Refine Their Own Reasoning for Open-Ended Tasks
Jun 16, 2025Recent advances in Large Language Models (LLMs) have showcased impressive reasoning abilities in structured tasks like mathematics and programming, largely driven by Reinforcement Learning with Verifiable Rewards (RLVR), which uses outcome-based signals that are scalable, effective, and robust against reward hacking. However, applying similar techniques to open-ended long-form reasoning tasks remains challenging due to the absence of generic, verifiable reward signals. To address this, we propose Direct Reasoning Optimization (DRO), a reinforcement learning framework for fine-tuning LLMs on open-ended, particularly long-form, reasoning tasks, guided by a new reward signal: the Reasoning Reflection Reward (R3). At its core, R3 selectively identifies and emphasizes key tokens in the reference outcome that reflect the influence of the model's preceding chain-of-thought reasoning, thereby capturing the consistency between reasoning and reference outcome at a fine-grained level. Crucially, R3 is computed internally using the same model being optimized, enabling a fully self-contained training setup. Additionally, we introduce a dynamic data filtering strategy based on R3 for open-ended reasoning tasks, reducing cost while improving downstream performance. We evaluate DRO on two diverse datasets -- ParaRev, a long-form paragraph revision task, and FinQA, a math-oriented QA benchmark -- and show that it consistently outperforms strong baselines while remaining broadly applicable across both open-ended and structured domains.
RLTHF: Targeted Human Feedback for LLM Alignment
Feb 19, 2025



Fine-tuning large language models (LLMs) to align with user preferences is challenging due to the high cost of quality human annotations in Reinforcement Learning from Human Feedback (RLHF) and the generalizability limitations of AI Feedback. To address these challenges, we propose RLTHF, a human-AI hybrid framework that combines LLM-based initial alignment with selective human annotations to achieve full-human annotation alignment with minimal effort. RLTHF identifies hard-to-annotate samples mislabeled by LLMs using a reward model's reward distribution and iteratively enhances alignment by integrating strategic human corrections while leveraging LLM's correctly labeled samples. Evaluations on HH-RLHF and TL;DR datasets show that RLTHF reaches full-human annotation-level alignment with only 6-7% of the human annotation effort. Furthermore, models trained on RLTHF's curated datasets for downstream tasks outperform those trained on fully human-annotated datasets, underscoring the effectiveness of RLTHF's strategic data curation.
Wireless Spectrum in Rural Farmlands: Status, Challenges and Opportunities
Jul 05, 2024



Due to factors such as low population density and expansive geographical distances, network deployment falls behind in rural regions, leading to a broadband divide. Wireless spectrum serves as the blood and flesh of wireless communications. Shared white spaces such as those in the TVWS and CBRS spectrum bands offer opportunities to expand connectivity, innovate, and provide affordable access to high-speed Internet in under-served areas without additional cost to expensive licensed spectrum. However, the current methods to utilize these white spaces are inefficient due to very conservative models and spectrum policies, causing under-utilization of valuable spectrum resources. This hampers the full potential of innovative wireless technologies that could benefit farmers, small Internet Service Providers (ISPs) or Mobile Network Operators (MNOs) operating in rural regions. This study explores the challenges faced by farmers and service providers when using shared spectrum bands to deploy their networks while ensuring maximum system performance and minimizing interference with other users. Additionally, we discuss how spatiotemporal spectrum models, in conjunction with database-driven spectrum-sharing solutions, can enhance the allocation and management of spectrum resources, ultimately improving the efficiency and reliability of wireless networks operating in shared spectrum bands.
No Size Fits All: Automated Radio Configuration for LPWANs
Sep 10, 2021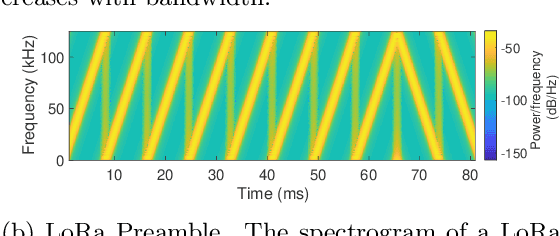

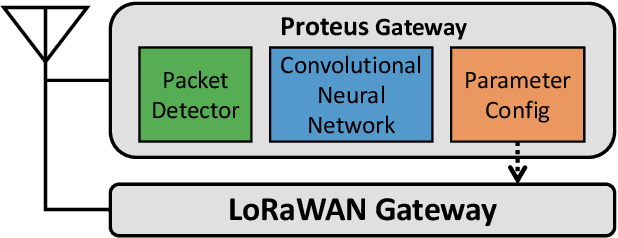
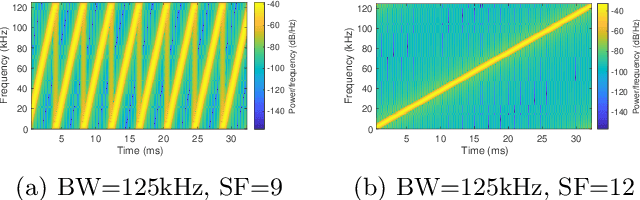
Low power long-range networks like LoRa have become increasingly mainstream for Internet of Things deployments. Given the versatility of applications that these protocols enable, they support many data rates and bandwidths. Yet, for a given network that supports hundreds of devices over multiple miles, the network operator typically needs to specify the same configuration or among a small subset of configurations for all the client devices to communicate with the gateway. This one-size-fits-all approach is highly inefficient in large networks. We propose an alternative approach -- we allow network devices to transmit at any data rate they choose. The gateway uses the first few symbols in the preamble to classify the correct data rate, switches its configuration, and then decodes the data. Our design leverages the inherent asymmetry in outdoor IoT deployments where the clients are power-starved and resource-constrained, but the gateway is not. Our gateway design, Proteus, runs a neural network architecture and is backward compatible with existing LoRa protocols. Our experiments reveal that Proteus can identify the correct configuration with over 97% accuracy in both indoor and outdoor deployments. Our network architecture leads to a 3.8 to 11 times increase in throughput for our LoRa testbed.