 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReVeal: A Physics-Informed Neural Network for High-Fidelity Radio Environment Mapping
Feb 27, 2025Accurately mapping the radio environment (e.g., identifying wireless signal strength at specific frequency bands and geographic locations) is crucial for efficient spectrum sharing, enabling secondary users (SUs) to access underutilized spectrum bands while protecting primary users (PUs). However, current models are either not generalizable due to shadowing, interference, and fading or are computationally too expensive, limiting real-world applicability. To address the shortcomings of existing models, we derive a second-order partial differential equation (PDE) for the Received Signal Strength Indicator (RSSI) based on a statistical model used in the literature. We then propose ReVeal (Re-constructor and Visualizer of Spectrum Landscape), a novel Physics-Informed Neural Network (PINN) that integrates the PDE residual into a neural network loss function to accurately model the radio environment based on sparse RF sensor measurements. ReVeal is validated using real-world measurement data from the rural and suburban areas of the ARA testbed and benchmarked against existing methods.ReVeal outperforms the existing methods in predicting the radio environment; for instance, with a root mean square error (RMSE) of only 1.95 dB, ReVeal achieves an accuracy that is an order of magnitude higher than existing methods such as the 3GPP and ITU-R channel models, ray-tracing, and neural networks. ReVeal achieves both high accuracy and low computational complexity while only requiring sparse RF sampling, for instance, only requiring 30 training sample points across an area of 514 square kilometers.
OpenEP: Open-Ended Future Event Prediction
Aug 14, 2024Future event prediction (FEP) is a long-standing and crucial task in the world, as understanding the evolution of events enables early risk identification, informed decision-making, and strategic planning. Existing work typically treats event prediction as classification tasks and confines the outcomes of future events to a fixed scope, such as yes/no questions, candidate set, and taxonomy, which is difficult to include all possible outcomes of future events. In this paper, we introduce OpenEP (an Open-Ended Future Event Prediction task), which generates flexible and diverse predictions aligned with real-world scenarios. This is mainly reflected in two aspects: firstly, the predictive questions are diverse, covering different stages of event development and perspectives; secondly, the outcomes are flexible, without constraints on scope or format. To facilitate the study of this task, we construct OpenEPBench, an open-ended future event prediction dataset. For question construction, we pose questions from seven perspectives, including location, time, event development, event outcome, event impact, event response, and other, to facilitate an in-depth analysis and understanding of the comprehensive evolution of events. For outcome construction, we collect free-form text containing the outcomes as ground truth to provide semantically complete and detail-enriched outcomes. Furthermore, we propose StkFEP, a stakeholder-enhanced future event prediction framework, that incorporates event characteristics for open-ended settings. Our method extracts stakeholders involved in events to extend questions to gather diverse information. We also collect historically events that are relevant and similar to the question to reveal potential evolutionary patterns. Experiment results indicate that accurately predicting future events in open-ended settings is challenging for existing LLMs.
Wireless Spectrum in Rural Farmlands: Status, Challenges and Opportunities
Jul 05, 2024



Due to factors such as low population density and expansive geographical distances, network deployment falls behind in rural regions, leading to a broadband divide. Wireless spectrum serves as the blood and flesh of wireless communications. Shared white spaces such as those in the TVWS and CBRS spectrum bands offer opportunities to expand connectivity, innovate, and provide affordable access to high-speed Internet in under-served areas without additional cost to expensive licensed spectrum. However, the current methods to utilize these white spaces are inefficient due to very conservative models and spectrum policies, causing under-utilization of valuable spectrum resources. This hampers the full potential of innovative wireless technologies that could benefit farmers, small Internet Service Providers (ISPs) or Mobile Network Operators (MNOs) operating in rural regions. This study explores the challenges faced by farmers and service providers when using shared spectrum bands to deploy their networks while ensuring maximum system performance and minimizing interference with other users. Additionally, we discuss how spatiotemporal spectrum models, in conjunction with database-driven spectrum-sharing solutions, can enhance the allocation and management of spectrum resources, ultimately improving the efficiency and reliability of wireless networks operating in shared spectrum bands.
TacoERE: Cluster-aware Compression for Event Relation Extraction
May 11, 2024
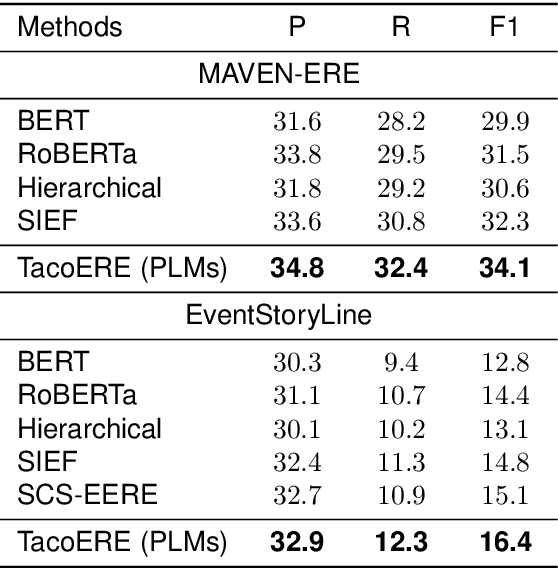
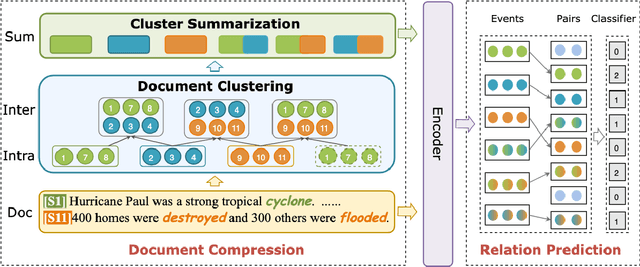
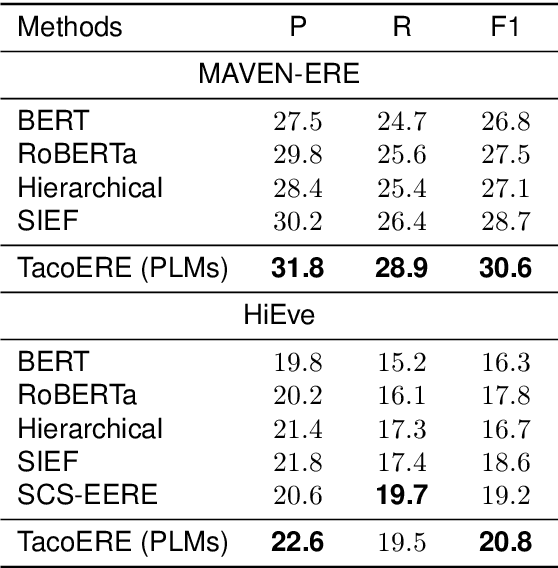
Event relation extraction (ERE) is a critical and fundamental challenge for natural language processing. Existing work mainly focuses on directly modeling the entire document, which cannot effectively handle long-range dependencies and information redundancy. To address these issues, we propose a cluster-aware compression method for improving event relation extraction (TacoERE), which explores a compression-then-extraction paradigm. Specifically, we first introduce document clustering for modeling event dependencies. It splits the document into intra- and inter-clusters, where intra-clusters aim to enhance the relations within the same cluster, while inter-clusters attempt to model the related events at arbitrary distances. Secondly, we utilize cluster summarization to simplify and highlight important text content of clusters for mitigating information redundancy and event distance. We have conducted extensive experiments on both pre-trained language models, such as RoBERTa, and large language models, such as ChatGPT and GPT-4, on three ERE datasets, i.e., MAVEN-ERE, EventStoryLine and HiEve. Experimental results demonstrate that TacoERE is an effective method for ERE.
Event GDR: Event-Centric Generative Document Retrieval
May 11, 2024



Generative document retrieval, an emerging paradigm in information retrieval, learns to build connections between documents and identifiers within a single model, garnering significant attention. However, there are still two challenges: (1) neglecting inner-content correlation during document representation; (2) lacking explicit semantic structure during identifier construction. Nonetheless, events have enriched relations and well-defined taxonomy, which could facilitate addressing the above two challenges. Inspired by this, we propose Event GDR, an event-centric generative document retrieval model, integrating event knowledge into this task. Specifically, we utilize an exchange-then-reflection method based on multi-agents for event knowledge extraction. For document representation, we employ events and relations to model the document to guarantee the comprehensiveness and inner-content correlation. For identifier construction, we map the events to well-defined event taxonomy to construct the identifiers with explicit semantic structure. Our method achieves significant improvement over the baselines on two datasets, and also hopes to provide insights for future research.
Knowledge-Aware Neuron Interpretation for Scene Classification
Jan 29, 2024



Although neural models have achieved remarkable performance, they still encounter doubts due to the intransparency. To this end, model prediction explanation is attracting more and more attentions. However, current methods rarely incorporate external knowledge and still suffer from three limitations: (1) Neglecting concept completeness. Merely selecting concepts may not sufficient for prediction. (2) Lacking concept fusion. Failure to merge semantically-equivalent concepts. (3) Difficult in manipulating model behavior. Lack of verification for explanation on original model. To address these issues, we propose a novel knowledge-aware neuron interpretation framework to explain model predictions for image scene classification. Specifically, for concept completeness, we present core concepts of a scene based on knowledge graph, ConceptNet, to gauge the completeness of concepts. Our method, incorporating complete concepts, effectively provides better prediction explanations compared to baselines. Furthermore, for concept fusion, we introduce a knowledge graph-based method known as Concept Filtering, which produces over 23% point gain on neuron behaviors for neuron interpretation. At last, we propose Model Manipulation, which aims to study whether the core concepts based on ConceptNet could be employed to manipulate model behavior. The results show that core concepts can effectively improve the performance of original model by over 26%.
Formalization of Robot Collision Detection Method based on Conformal Geometric Algebra
Dec 06, 2023Cooperative robots can significantly assist people in their productive activities, improving the quality of their works. Collision detection is vital to ensure the safe and stable operation of cooperative robots in productive activities. As an advanced geometric language, conformal geometric algebra can simplify the construction of the robot collision model and the calculation of collision distance. Compared with the formal method based on conformal geometric algebra, the traditional method may have some defects which are difficult to find in the modelling and calculation. We use the formal method based on conformal geometric algebra to study the collision detection problem of cooperative robots. This paper builds formal models of geometric primitives and the robot body based on the conformal geometric algebra library in HOL Light. We analyse the shortest distance between geometric primitives and prove their collision determination conditions. Based on the above contents, we construct a formal verification framework for the robot collision detection method. By the end of this paper, we apply the proposed framework to collision detection between two single-arm industrial cooperative robots. The flexibility and reliability of the proposed framework are verified by constructing a general collision model and a special collision model for two single-arm industrial cooperative robots.
MAVEN-Arg: Completing the Puzzle of All-in-One Event Understanding Dataset with Event Argument Annotation
Nov 15, 2023



Understanding events in texts is a core objective of natural language understanding, which requires detecting event occurrences, extracting event arguments, and analyzing inter-event relationships. However, due to the annotation challenges brought by task complexity, a large-scale dataset covering the full process of event understanding has long been absent. In this paper, we introduce MAVEN-Arg, which augments MAVEN datasets with event argument annotations, making the first all-in-one dataset supporting event detection, event argument extraction (EAE), and event relation extraction. As an EAE benchmark, MAVEN-Arg offers three main advantages: (1) a comprehensive schema covering 162 event types and 612 argument roles, all with expert-written definitions and examples; (2) a large data scale, containing 98,591 events and 290,613 arguments obtained with laborious human annotation; (3) the exhaustive annotation supporting all task variants of EAE, which annotates both entity and non-entity event arguments in document level. Experiments indicate that MAVEN-Arg is quite challenging for both fine-tuned EAE models and proprietary large language models (LLMs). Furthermore, to demonstrate the benefits of an all-in-one dataset, we preliminarily explore a potential application, future event prediction, with LLMs. MAVEN-Arg and our code can be obtained from https://github.com/THU-KEG/MAVEN-Argument.
A Comprehensive and Reliable Feature Attribution Method: Double-sided Remove and Reconstruct (DoRaR)
Oct 27, 2023



The limited transparency of the inner decision-making mechanism in deep neural networks (DNN) and other machine learning (ML) models has hindered their application in several domains. In order to tackle this issue, feature attribution methods have been developed to identify the crucial features that heavily influence decisions made by these black box models. However, many feature attribution methods have inherent downsides. For example, one category of feature attribution methods suffers from the artifacts problem, which feeds out-of-distribution masked inputs directly through the classifier that was originally trained on natural data points. Another category of feature attribution method finds explanations by using jointly trained feature selectors and predictors. While avoiding the artifacts problem, this new category suffers from the Encoding Prediction in the Explanation (EPITE) problem, in which the predictor's decisions rely not on the features, but on the masks that selects those features. As a result, the credibility of attribution results is undermined by these downsides. In this research, we introduce the Double-sided Remove and Reconstruct (DoRaR) feature attribution method based on several improvement methods that addresses these issues. By conducting thorough testing on MNIST, CIFAR10 and our own synthetic dataset, we demonstrate that the DoRaR feature attribution method can effectively bypass the above issues and can aid in training a feature selector that outperforms other state-of-the-art feature attribution methods. Our code is available at https://github.com/dxq21/DoRaR.
KoLA: Carefully Benchmarking World Knowledge of Large Language Models
Jun 15, 2023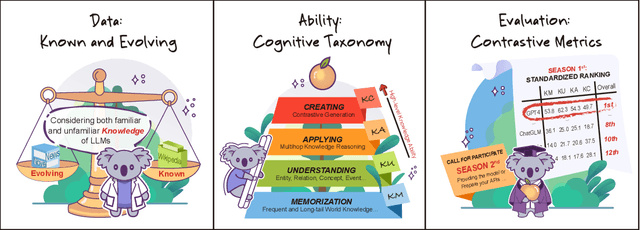
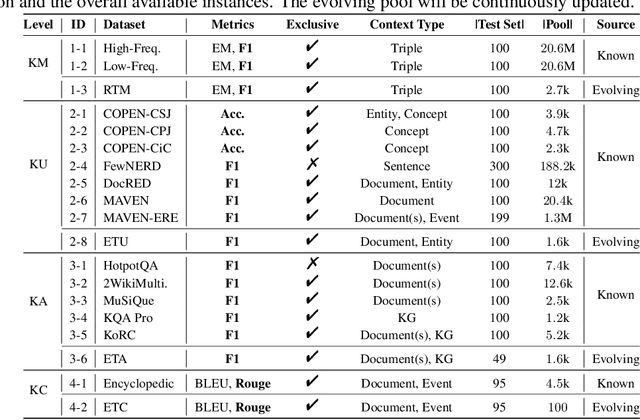
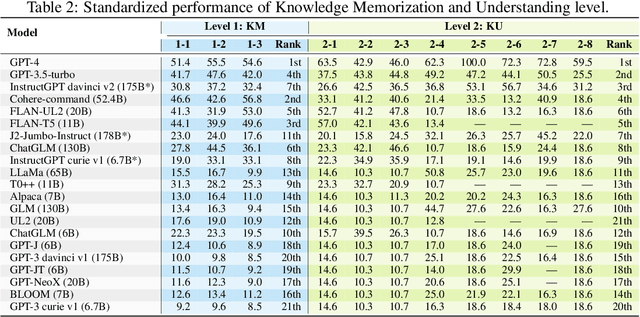

The unprecedented performance of large language models (LLMs) necessitates improvements in evaluations. Rather than merely exploring the breadth of LLM abilities, we believe meticulous and thoughtful designs are essential to thorough, unbiased, and applicable evaluations. Given the importance of world knowledge to LLMs, we construct a Knowledge-oriented LLM Assessment benchmark (KoLA), in which we carefully design three crucial factors: (1) For ability modeling, we mimic human cognition to form a four-level taxonomy of knowledge-related abilities, covering $19$ tasks. (2) For data, to ensure fair comparisons, we use both Wikipedia, a corpus prevalently pre-trained by LLMs, along with continuously collected emerging corpora, aiming to evaluate the capacity to handle unseen data and evolving knowledge. (3) For evaluation criteria, we adopt a contrastive system, including overall standard scores for better numerical comparability across tasks and models and a unique self-contrast metric for automatically evaluating knowledge hallucination. We evaluate $21$ open-source and commercial LLMs and obtain some intriguing findings. The KoLA dataset and open-participation leaderboard are publicly released at https://kola.xlore.cn and will be continuously updated to provide references for developing LLMs and knowledge-related systems.