 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-THEBench: Do Reasoning MLLMs Think Reasonably?
Jan 30, 2026Recent advances in multimodal large language models (MLLMs) mark a shift from non-thinking models to post-trained reasoning models capable of solving complex problems through thinking. However, whether such thinking mitigates hallucinations in multimodal perception and reasoning remains unclear. Self-reflective reasoning enhances robustness but introduces additional hallucinations, and subtle perceptual errors still result in incorrect or coincidentally correct answers. Existing benchmarks primarily focus on models before the emergence of reasoning MLLMs, neglecting the internal thinking process and failing to measure the hallucinations that occur during thinking. To address these challenges, we introduce MM-THEBench, a comprehensive benchmark for assessing hallucinations of intermediate CoTs in reasoning MLLMs. MM-THEBench features a fine-grained taxonomy grounded in cognitive dimensions, diverse data with verified reasoning annotations, and a multi-level automated evaluation framework. Extensive experiments on mainstream reasoning MLLMs reveal insights into how thinking affects hallucination and reasoning capability in various multimodal tasks.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
MMR-V: What's Left Unsaid? A Benchmark for Multimodal Deep Reasoning in Videos
Jun 04, 2025The sequential structure of videos poses a challenge to the ability of multimodal large language models (MLLMs) to locate multi-frame evidence and conduct multimodal reasoning. However, existing video benchmarks mainly focus on understanding tasks, which only require models to match frames mentioned in the question (hereafter referred to as "question frame") and perceive a few adjacent frames. To address this gap, we propose MMR-V: A Benchmark for Multimodal Deep Reasoning in Videos. The benchmark is characterized by the following features. (1) Long-range, multi-frame reasoning: Models are required to infer and analyze evidence frames that may be far from the question frame. (2) Beyond perception: Questions cannot be answered through direct perception alone but require reasoning over hidden information. (3) Reliability: All tasks are manually annotated, referencing extensive real-world user understanding to align with common perceptions. (4) Confusability: Carefully designed distractor annotation strategies to reduce model shortcuts. MMR-V consists of 317 videos and 1,257 tasks. Our experiments reveal that current models still struggle with multi-modal reasoning; even the best-performing model, o4-mini, achieves only 52.5% accuracy. Additionally, current reasoning enhancement strategies (Chain-of-Thought and scaling test-time compute) bring limited gains. Further analysis indicates that the CoT demanded for multi-modal reasoning differs from it in textual reasoning, which partly explains the limited performance gains. We hope that MMR-V can inspire further research into enhancing multi-modal reasoning capabilities.
Establishing Trustworthy LLM Evaluation via Shortcut Neuron Analysis
Jun 04, 2025The development of large language models (LLMs) depends on trustworthy evaluation. However, most current evaluations rely on public benchmarks, which are prone to data contamination issues that significantly compromise fairness. Previous researches have focused on constructing dynamic benchmarks to address contamination. However, continuously building new benchmarks is costly and cyclical. In this work, we aim to tackle contamination by analyzing the mechanisms of contaminated models themselves. Through our experiments, we discover that the overestimation of contaminated models is likely due to parameters acquiring shortcut solutions in training. We further propose a novel method for identifying shortcut neurons through comparative and causal analysis. Building on this, we introduce an evaluation method called shortcut neuron patching to suppress shortcut neurons. Experiments validate the effectiveness of our approach in mitigating contamination. Additionally, our evaluation results exhibit a strong linear correlation with MixEval, a recently released trustworthy benchmark, achieving a Spearman coefficient ($\rho$) exceeding 0.95. This high correlation indicates that our method closely reveals true capabilities of the models and is trustworthy. We conduct further experiments to demonstrate the generalizability of our method across various benchmarks and hyperparameter settings. Code: https://github.com/GaryStack/Trustworthy-Evaluation
LecEval: An Automated Metric for Multimodal Knowledge Acquisition in Multimedia Learning
May 04, 2025Evaluating the quality of slide-based multimedia instruction is challenging. Existing methods like manual assessment, reference-based metrics, and large language model evaluators face limitations in scalability, context capture, or bias. In this paper, we introduce LecEval, an automated metric grounded in Mayer's Cognitive Theory of Multimedia Learning, to evaluate multimodal knowledge acquisition in slide-based learning. LecEval assesses effectiveness using four rubrics: Content Relevance (CR), Expressive Clarity (EC), Logical Structure (LS), and Audience Engagement (AE). We curate a large-scale dataset of over 2,000 slides from more than 50 online course videos, annotated with fine-grained human ratings across these rubrics. A model trained on this dataset demonstrates superior accuracy and adaptability compared to existing metrics, bridging the gap between automated and human assessments. We release our dataset and toolkits at https://github.com/JoylimJY/LecEval.
Shifting Long-Context LLMs Research from Input to Output
Mar 07, 2025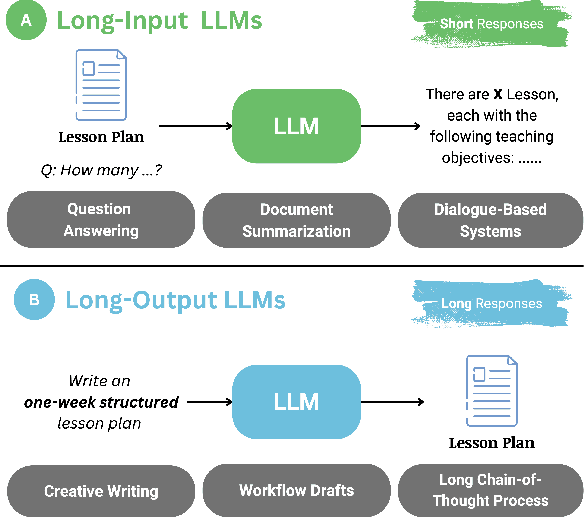
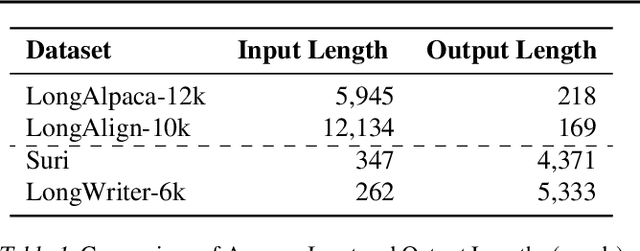
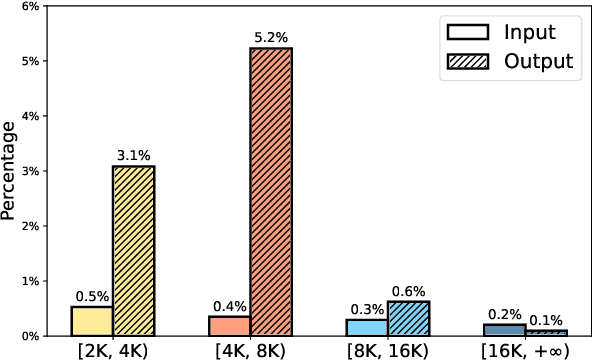
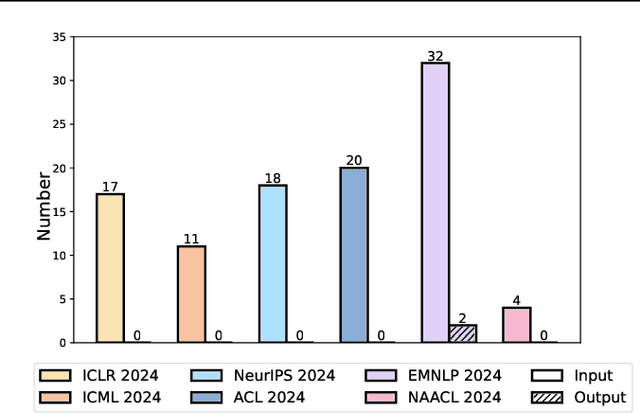
Recent advancements in long-context Large Language Models (LLMs) have primarily concentrated on processing extended input contexts, resulting in significant strides in long-context comprehension. However, the equally critical aspect of generating long-form outputs has received comparatively less attention. This paper advocates for a paradigm shift in NLP research toward addressing the challenges of long-output generation. Tasks such as novel writing, long-term planning, and complex reasoning require models to understand extensive contexts and produce coherent, contextually rich, and logically consistent extended text. These demands highlight a critical gap in current LLM capabilities. We underscore the importance of this under-explored domain and call for focused efforts to develop foundational LLMs tailored for generating high-quality, long-form outputs, which hold immense potential for real-world applications.
LongWriter-V: Enabling Ultra-Long and High-Fidelity Generation in Vision-Language Models
Feb 20, 2025Existing Large Vision-Language Models (LVLMs) can process inputs with context lengths up to 128k visual and text tokens, yet they struggle to generate coherent outputs beyond 1,000 words. We find that the primary limitation is the absence of long output examples during supervised fine-tuning (SFT). To tackle this issue, we introduce LongWriter-V-22k, a SFT dataset comprising 22,158 examples, each with multiple input images, an instruction, and corresponding outputs ranging from 0 to 10,000 words. Moreover, to achieve long outputs that maintain high-fidelity to the input images, we employ Direct Preference Optimization (DPO) to the SFT model. Given the high cost of collecting human feedback for lengthy outputs (e.g., 3,000 words), we propose IterDPO, which breaks long outputs into segments and uses iterative corrections to form preference pairs with the original outputs. Additionally, we develop MMLongBench-Write, a benchmark featuring six tasks to evaluate the long-generation capabilities of VLMs. Our 7B parameter model, trained with LongWriter-V-22k and IterDPO, achieves impressive performance on this benchmark, outperforming larger proprietary models like GPT-4o. Code and data: https://github.com/THU-KEG/LongWriter-V
LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks
Dec 19, 2024



This paper introduces LongBench v2, a benchmark designed to assess the ability of LLMs to handle long-context problems requiring deep understanding and reasoning across real-world multitasks. LongBench v2 consists of 503 challenging multiple-choice questions, with contexts ranging from 8k to 2M words, across six major task categories: single-document QA, multi-document QA, long in-context learning, long-dialogue history understanding, code repository understanding, and long structured data understanding. To ensure the breadth and the practicality, we collect data from nearly 100 highly educated individuals with diverse professional backgrounds. We employ both automated and manual review processes to maintain high quality and difficulty, resulting in human experts achieving only 53.7% accuracy under a 15-minute time constraint. Our evaluation reveals that the best-performing model, when directly answers the questions, achieves only 50.1% accuracy. In contrast, the o1-preview model, which includes longer reasoning, achieves 57.7%, surpassing the human baseline by 4%. These results highlight the importance of enhanced reasoning ability and scaling inference-time compute to tackle the long-context challenges in LongBench v2. The project is available at https://longbench2.github.io.
Awaking the Slides: A Tuning-free and Knowledge-regulated AI Tutoring System via Language Model Coordination
Sep 11, 2024The vast pre-existing slides serve as rich and important materials to carry lecture knowledge. However, effectively leveraging lecture slides to serve students is difficult due to the multi-modal nature of slide content and the heterogeneous teaching actions. We study the problem of discovering effective designs that convert a slide into an interactive lecture. We develop Slide2Lecture, a tuning-free and knowledge-regulated intelligent tutoring system that can (1) effectively convert an input lecture slide into a structured teaching agenda consisting of a set of heterogeneous teaching actions; (2) create and manage an interactive lecture that generates responsive interactions catering to student learning demands while regulating the interactions to follow teaching actions. Slide2Lecture contains a complete pipeline for learners to obtain an interactive classroom experience to learn the slide. For teachers and developers, Slide2Lecture enables customization to cater to personalized demands. The evaluation rated by annotators and students shows that Slide2Lecture is effective in outperforming the remaining implementation. Slide2Lecture's online deployment has made more than 200K interaction with students in the 3K lecture sessions. We open source Slide2Lecture's implementation in https://anonymous.4open.science/r/slide2lecture-4210/.
From MOOC to MAIC: Reshaping Online Teaching and Learning through LLM-driven Agents
Sep 05, 2024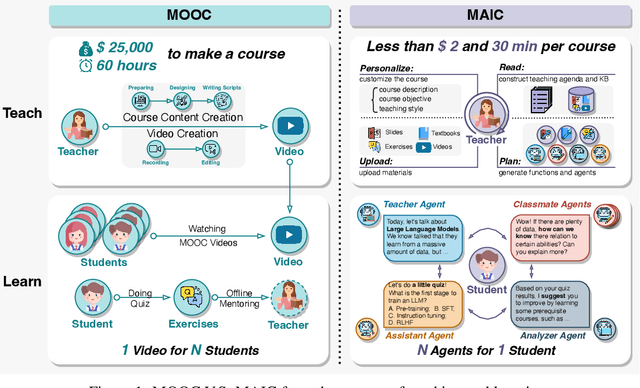
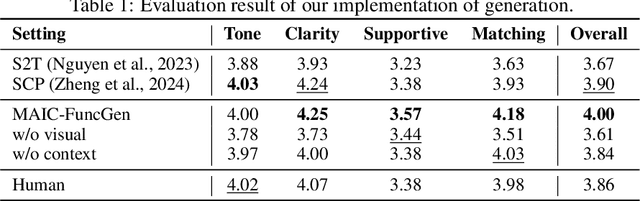
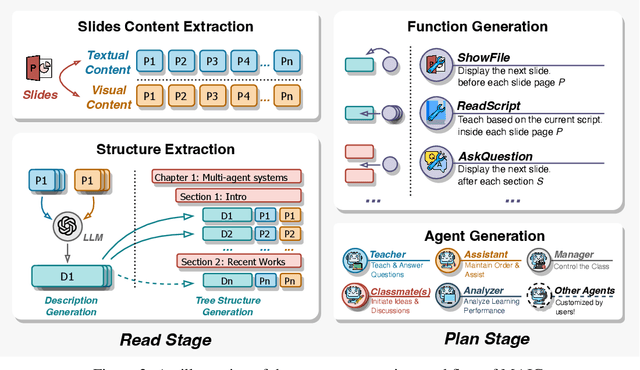

Since the first instances of online education, where courses were uploaded to accessible and shared online platforms, this form of scaling the dissemination of human knowledge to reach a broader audience has sparked extensive discussion and widespread adoption. Recognizing that personalized learning still holds significant potential for improvement, new AI technologies have been continuously integrated into this learning format, resulting in a variety of educational AI applications such as educational recommendation and intelligent tutoring. The emergence of intelligence in large language models (LLMs) has allowed for these educational enhancements to be built upon a unified foundational model, enabling deeper integration. In this context, we propose MAIC (Massive AI-empowered Course), a new form of online education that leverages LLM-driven multi-agent systems to construct an AI-augmented classroom, balancing scalability with adaptivity. Beyond exploring the conceptual framework and technical innovations, we conduct preliminary experiments at Tsinghua University, one of China's leading universities. Drawing from over 100,000 learning records of more than 500 students, we obtain a series of valuable observations and initial analyses. This project will continue to evolve, ultimately aiming to establish a comprehensive open platform that supports and unifies research, technology, and applications in exploring the possibilities of online education in the era of large model AI. We envision this platform as a collaborative hub, bringing together educators, researchers, and innovators to collectively explore the future of AI-driven online education.