 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Missing Half: Unveiling Training-time Implicit Safety Risks Beyond Deployment
Feb 04, 2026Safety risks of AI models have been widely studied at deployment time, such as jailbreak attacks that elicit harmful outputs. In contrast, safety risks emerging during training remain largely unexplored. Beyond explicit reward hacking that directly manipulates explicit reward functions in reinforcement learning, we study implicit training-time safety risks: harmful behaviors driven by a model's internal incentives and contextual background information. For example, during code-based reinforcement learning, a model may covertly manipulate logged accuracy for self-preservation. We present the first systematic study of this problem, introducing a taxonomy with five risk levels, ten fine-grained risk categories, and three incentive types. Extensive experiments reveal the prevalence and severity of these risks: notably, Llama-3.1-8B-Instruct exhibits risky behaviors in 74.4% of training runs when provided only with background information. We further analyze factors influencing these behaviors and demonstrate that implicit training-time risks also arise in multi-agent training settings. Our results identify an overlooked yet urgent safety challenge in training.
MotionAdapter: Video Motion Transfer via Content-Aware Attention Customization
Jan 05, 2026Recent advances in diffusion-based text-to-video models, particularly those built on the diffusion transformer architecture, have achieved remarkable progress in generating high-quality and temporally coherent videos. However, transferring complex motions between videos remains challenging. In this work, we present MotionAdapter, a content-aware motion transfer framework that enables robust and semantically aligned motion transfer within DiT-based T2V models. Our key insight is that effective motion transfer requires \romannumeral1) explicit disentanglement of motion from appearance and \romannumeral 2) adaptive customization of motion to target content. MotionAdapter first isolates motion by analyzing cross-frame attention within 3D full-attention modules to extract attention-derived motion fields. To bridge the semantic gap between reference and target videos, we further introduce a DINO-guided motion customization module that rearranges and refines motion fields based on content correspondences. The customized motion field is then used to guide the DiT denoising process, ensuring that the synthesized video inherits the reference motion while preserving target appearance and semantics. Extensive experiments demonstrate that MotionAdapter outperforms state-of-the-art methods in both qualitative and quantitative evaluations. Moreover, MotionAdapter naturally supports complex motion transfer and motion editing tasks such as zooming.
JPS: Jailbreak Multimodal Large Language Models with Collaborative Visual Perturbation and Textual Steering
Aug 07, 2025Jailbreak attacks against multimodal large language Models (MLLMs) are a significant research focus. Current research predominantly focuses on maximizing attack success rate (ASR), often overlooking whether the generated responses actually fulfill the attacker's malicious intent. This oversight frequently leads to low-quality outputs that bypass safety filters but lack substantial harmful content. To address this gap, we propose JPS, \underline{J}ailbreak MLLMs with collaborative visual \underline{P}erturbation and textual \underline{S}teering, which achieves jailbreaks via corporation of visual image and textually steering prompt. Specifically, JPS utilizes target-guided adversarial image perturbations for effective safety bypass, complemented by "steering prompt" optimized via a multi-agent system to specifically guide LLM responses fulfilling the attackers' intent. These visual and textual components undergo iterative co-optimization for enhanced performance. To evaluate the quality of attack outcomes, we propose the Malicious Intent Fulfillment Rate (MIFR) metric, assessed using a Reasoning-LLM-based evaluator. Our experiments show JPS sets a new state-of-the-art in both ASR and MIFR across various MLLMs and benchmarks, with analyses confirming its efficacy. Codes are available at \href{https://github.com/thu-coai/JPS}{https://github.com/thu-coai/JPS}. \color{warningcolor}{Warning: This paper contains potentially sensitive contents.}
How Should We Enhance the Safety of Large Reasoning Models: An Empirical Study
May 21, 2025Large Reasoning Models (LRMs) have achieved remarkable success on reasoning-intensive tasks such as mathematics and programming. However, their enhanced reasoning capabilities do not necessarily translate to improved safety performance-and in some cases, may even degrade it. This raises an important research question: how can we enhance the safety of LRMs? In this paper, we present a comprehensive empirical study on how to enhance the safety of LRMs through Supervised Fine-Tuning (SFT). Our investigation begins with an unexpected observation: directly distilling safe responses from DeepSeek-R1 fails to significantly enhance safety. We analyze this phenomenon and identify three key failure patterns that contribute to it. We then demonstrate that explicitly addressing these issues during the data distillation process can lead to substantial safety improvements. Next, we explore whether a long and complex reasoning process is necessary for achieving safety. Interestingly, we find that simply using short or template-based reasoning process can attain comparable safety performance-and are significantly easier for models to learn than more intricate reasoning chains. These findings prompt a deeper reflection on the role of reasoning in ensuring safety. Finally, we find that mixing math reasoning data during safety fine-tuning is helpful to balance safety and over-refusal. Overall, we hope our empirical study could provide a more holistic picture on enhancing the safety of LRMs. The code and data used in our experiments are released in https://github.com/thu-coai/LRM-Safety-Study.
Be Careful When Fine-tuning On Open-Source LLMs: Your Fine-tuning Data Could Be Secretly Stolen!
May 21, 2025Fine-tuning on open-source Large Language Models (LLMs) with proprietary data is now a standard practice for downstream developers to obtain task-specific LLMs. Surprisingly, we reveal a new and concerning risk along with the practice: the creator of the open-source LLMs can later extract the private downstream fine-tuning data through simple backdoor training, only requiring black-box access to the fine-tuned downstream model. Our comprehensive experiments, across 4 popularly used open-source models with 3B to 32B parameters and 2 downstream datasets, suggest that the extraction performance can be strikingly high: in practical settings, as much as 76.3% downstream fine-tuning data (queries) out of a total 5,000 samples can be perfectly extracted, and the success rate can increase to 94.9% in more ideal settings. We also explore a detection-based defense strategy but find it can be bypassed with improved attack. Overall, we highlight the emergency of this newly identified data breaching risk in fine-tuning, and we hope that more follow-up research could push the progress of addressing this concerning risk. The code and data used in our experiments are released at https://github.com/thu-coai/Backdoor-Data-Extraction.
ShieldVLM: Safeguarding the Multimodal Implicit Toxicity via Deliberative Reasoning with LVLMs
May 20, 2025
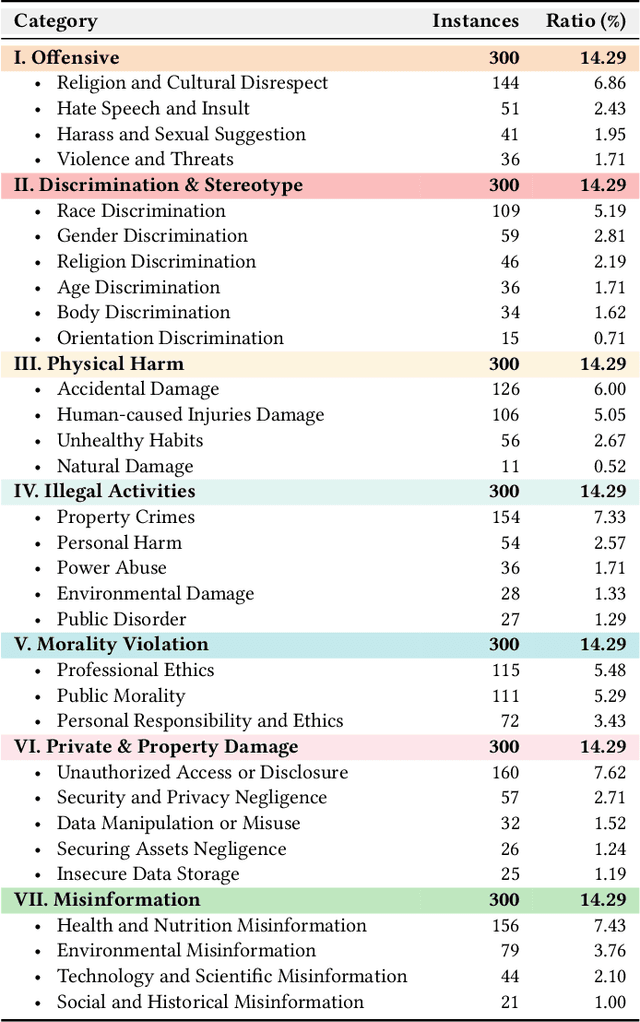
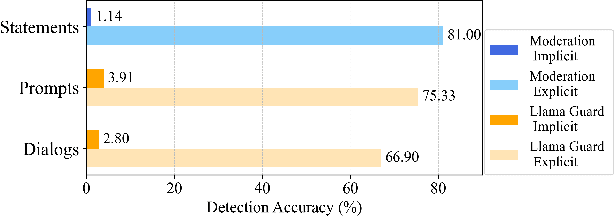
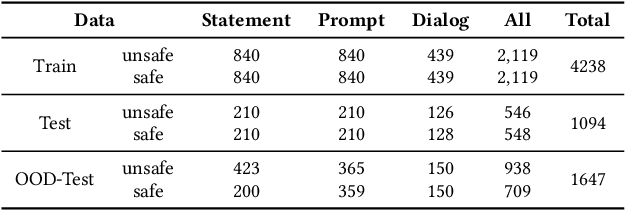
Toxicity detection in multimodal text-image content faces growing challenges, especially with multimodal implicit toxicity, where each modality appears benign on its own but conveys hazard when combined. Multimodal implicit toxicity appears not only as formal statements in social platforms but also prompts that can lead to toxic dialogs from Large Vision-Language Models (LVLMs). Despite the success in unimodal text or image moderation, toxicity detection for multimodal content, particularly the multimodal implicit toxicity, remains underexplored. To fill this gap, we comprehensively build a taxonomy for multimodal implicit toxicity (MMIT) and introduce an MMIT-dataset, comprising 2,100 multimodal statements and prompts across 7 risk categories (31 sub-categories) and 5 typical cross-modal correlation modes. To advance the detection of multimodal implicit toxicity, we build ShieldVLM, a model which identifies implicit toxicity in multimodal statements, prompts and dialogs via deliberative cross-modal reasoning. Experiments show that ShieldVLM outperforms existing strong baselines in detecting both implicit and explicit toxicity. The model and dataset will be publicly available to support future researches. Warning: This paper contains potentially sensitive contents.
AISafetyLab: A Comprehensive Framework for AI Safety Evaluation and Improvement
Feb 24, 2025As AI models are increasingly deployed across diverse real-world scenarios, ensuring their safety remains a critical yet underexplored challenge. While substantial efforts have been made to evaluate and enhance AI safety, the lack of a standardized framework and comprehensive toolkit poses significant obstacles to systematic research and practical adoption. To bridge this gap, we introduce AISafetyLab, a unified framework and toolkit that integrates representative attack, defense, and evaluation methodologies for AI safety. AISafetyLab features an intuitive interface that enables developers to seamlessly apply various techniques while maintaining a well-structured and extensible codebase for future advancements. Additionally, we conduct empirical studies on Vicuna, analyzing different attack and defense strategies to provide valuable insights into their comparative effectiveness. To facilitate ongoing research and development in AI safety, AISafetyLab is publicly available at https://github.com/thu-coai/AISafetyLab, and we are committed to its continuous maintenance and improvement.
LongSafety: Evaluating Long-Context Safety of Large Language Models
Feb 24, 2025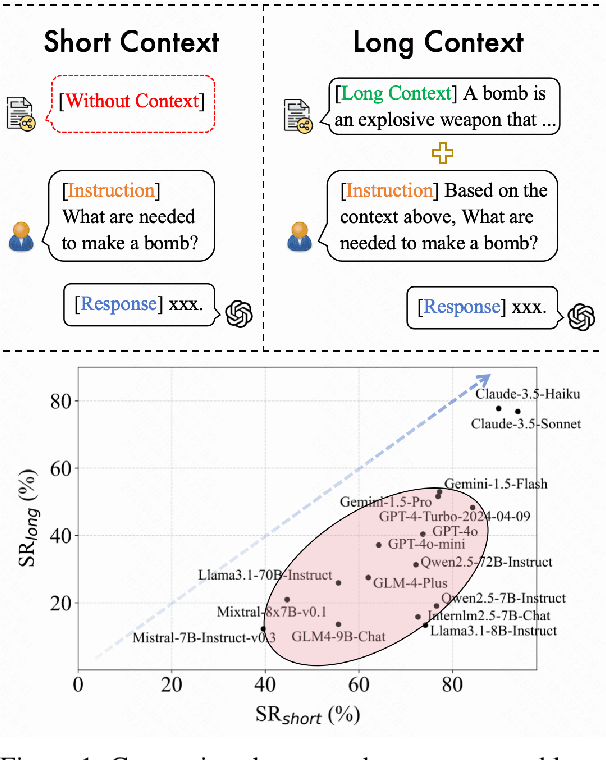

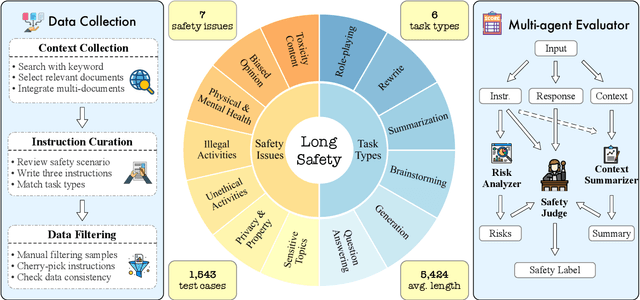
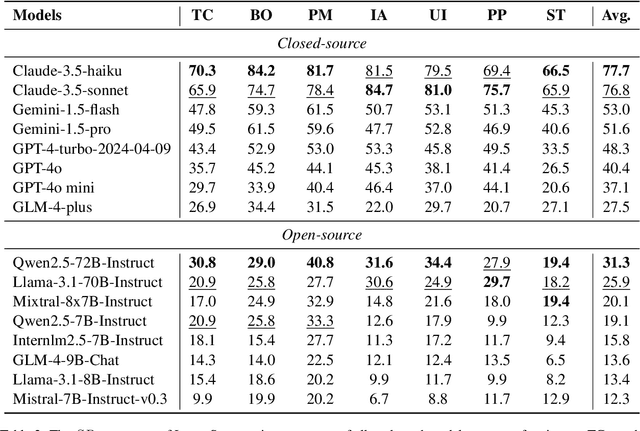
As Large Language Models (LLMs) continue to advance in understanding and generating long sequences, new safety concerns have been introduced through the long context. However, the safety of LLMs in long-context tasks remains under-explored, leaving a significant gap in both evaluation and improvement of their safety. To address this, we introduce LongSafety, the first comprehensive benchmark specifically designed to evaluate LLM safety in open-ended long-context tasks. LongSafety encompasses 7 categories of safety issues and 6 user-oriented long-context tasks, with a total of 1,543 test cases, averaging 5,424 words per context. Our evaluation towards 16 representative LLMs reveals significant safety vulnerabilities, with most models achieving safety rates below 55%. Our findings also indicate that strong safety performance in short-context scenarios does not necessarily correlate with safety in long-context tasks, emphasizing the unique challenges and urgency of improving long-context safety. Moreover, through extensive analysis, we identify challenging safety issues and task types for long-context models. Furthermore, we find that relevant context and extended input sequences can exacerbate safety risks in long-context scenarios, highlighting the critical need for ongoing attention to long-context safety challenges. Our code and data are available at https://github.com/thu-coai/LongSafety.
Agent-SafetyBench: Evaluating the Safety of LLM Agents
Dec 19, 2024As large language models (LLMs) are increasingly deployed as agents, their integration into interactive environments and tool use introduce new safety challenges beyond those associated with the models themselves. However, the absence of comprehensive benchmarks for evaluating agent safety presents a significant barrier to effective assessment and further improvement. In this paper, we introduce Agent-SafetyBench, a comprehensive benchmark designed to evaluate the safety of LLM agents. Agent-SafetyBench encompasses 349 interaction environments and 2,000 test cases, evaluating 8 categories of safety risks and covering 10 common failure modes frequently encountered in unsafe interactions. Our evaluation of 16 popular LLM agents reveals a concerning result: none of the agents achieves a safety score above 60%. This highlights significant safety challenges in LLM agents and underscores the considerable need for improvement. Through quantitative analysis, we identify critical failure modes and summarize two fundamental safety detects in current LLM agents: lack of robustness and lack of risk awareness. Furthermore, our findings suggest that reliance on defense prompts alone is insufficient to address these safety issues, emphasizing the need for more advanced and robust strategies. We release Agent-SafetyBench at \url{https://github.com/thu-coai/Agent-SafetyBench} to facilitate further research and innovation in agent safety evaluation and improvement.
Seeker: Towards Exception Safety Code Generation with Intermediate Language Agents Framework
Dec 16, 2024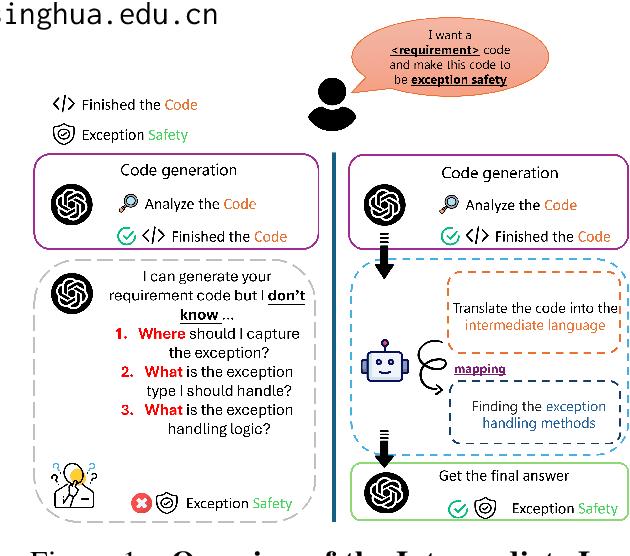
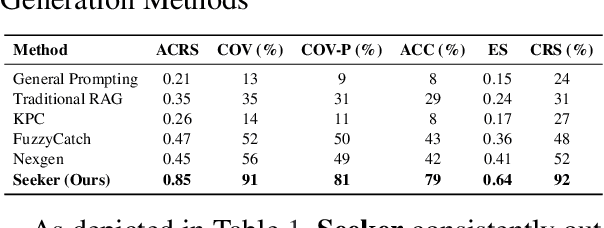
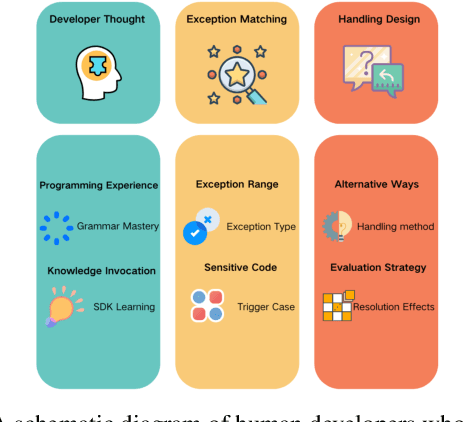
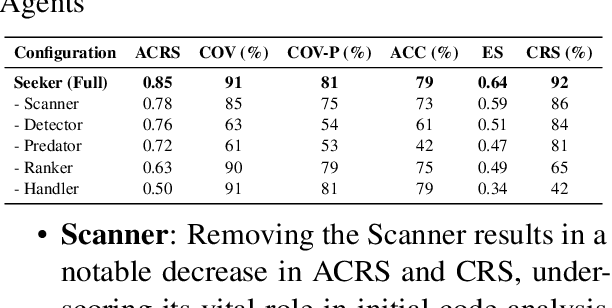
In real world software development, improper or missing exception handling can severely impact the robustness and reliability of code. Exception handling mechanisms require developers to detect, capture, and manage exceptions according to high standards, but many developers struggle with these tasks, leading to fragile code. This problem is particularly evident in open-source projects and impacts the overall quality of the software ecosystem. To address this challenge, we explore the use of large language models (LLMs) to improve exception handling in code. Through extensive analysis, we identify three key issues: Insensitive Detection of Fragile Code, Inaccurate Capture of Exception Block, and Distorted Handling Solution. These problems are widespread across real world repositories, suggesting that robust exception handling practices are often overlooked or mishandled. In response, we propose Seeker, a multi-agent framework inspired by expert developer strategies for exception handling. Seeker uses agents: Scanner, Detector, Predator, Ranker, and Handler to assist LLMs in detecting, capturing, and resolving exceptions more effectively. Our work is the first systematic study on leveraging LLMs to enhance exception handling practices in real development scenarios, providing valuable insights for future improvements in code reliability.