 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Foundation Models: Vision, Challenges, and Opportunities
Jan 15, 2025Foundation models have revolutionized artificial intelligence, setting new benchmarks in performance and enabling transformative capabilities across a wide range of vision and language tasks. However, despite the prevalence of spatio-temporal data in critical domains such as transportation, public health, and environmental monitoring, spatio-temporal foundation models (STFMs) have not yet achieved comparable success. In this paper, we articulate a vision for the future of STFMs, outlining their essential characteristics and the generalization capabilities necessary for broad applicability. We critically assess the current state of research, identifying gaps relative to these ideal traits, and highlight key challenges that impede their progress. Finally, we explore potential opportunities and directions to advance research towards the aim of effective and broadly applicable STFMs.
Global Challenge for Safe and Secure LLMs Track 1
Nov 21, 2024


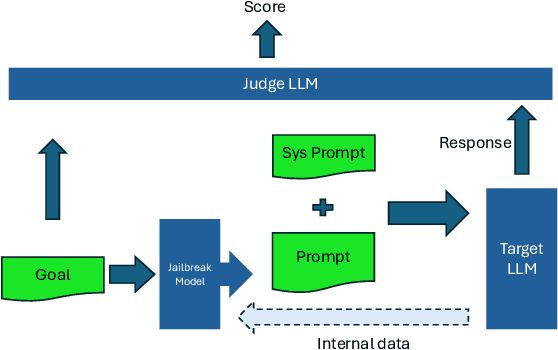
This paper introduces the Global Challenge for Safe and Secure Large Language Models (LLMs), a pioneering initiative organized by AI Singapore (AISG) and the CyberSG R&D Programme Office (CRPO) to foster the development of advanced defense mechanisms against automated jailbreaking attacks. With the increasing integration of LLMs in critical sectors such as healthcare, finance, and public administration, ensuring these models are resilient to adversarial attacks is vital for preventing misuse and upholding ethical standards. This competition focused on two distinct tracks designed to evaluate and enhance the robustness of LLM security frameworks. Track 1 tasked participants with developing automated methods to probe LLM vulnerabilities by eliciting undesirable responses, effectively testing the limits of existing safety protocols within LLMs. Participants were challenged to devise techniques that could bypass content safeguards across a diverse array of scenarios, from offensive language to misinformation and illegal activities. Through this process, Track 1 aimed to deepen the understanding of LLM vulnerabilities and provide insights for creating more resilient models.
From 2D to 3D: AISG-SLA Visual Localization Challenge
Jul 26, 2024



Research in 3D mapping is crucial for smart city applications, yet the cost of acquiring 3D data often hinders progress. Visual localization, particularly monocular camera position estimation, offers a solution by determining the camera's pose solely through visual cues. However, this task is challenging due to limited data from a single camera. To tackle these challenges, we organized the AISG-SLA Visual Localization Challenge (VLC) at IJCAI 2023 to explore how AI can accurately extract camera pose data from 2D images in 3D space. The challenge attracted over 300 participants worldwide, forming 50+ teams. Winning teams achieved high accuracy in pose estimation using images from a car-mounted camera with low frame rates. The VLC dataset is available for research purposes upon request via vlc-dataset@aisingapore.org.
When Text and Images Don't Mix: Bias-Correcting Language-Image Similarity Scores for Anomaly Detection
Jul 24, 2024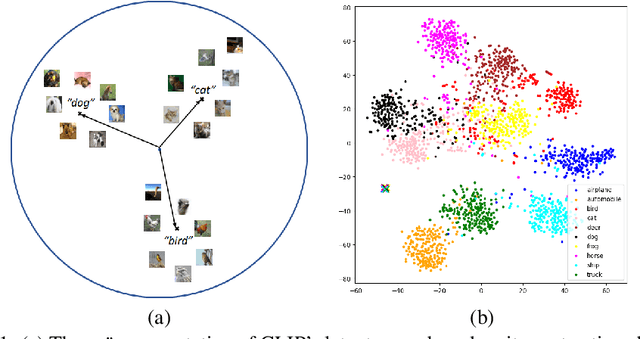
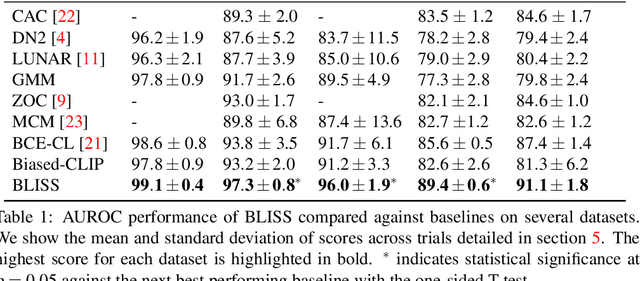
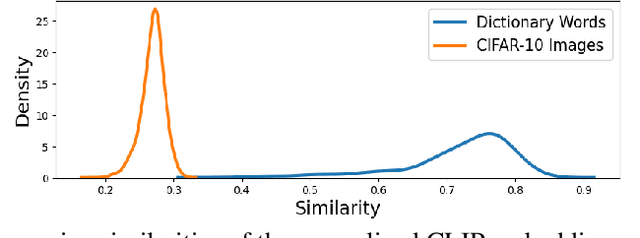
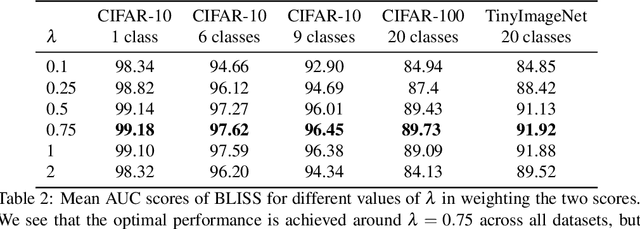
Contrastive Language-Image Pre-training (CLIP) achieves remarkable performance in various downstream tasks through the alignment of image and text input embeddings and holds great promise for anomaly detection. However, our empirical experiments show that the embeddings of text inputs unexpectedly tightly cluster together, far away from image embeddings, contrary to the model's contrastive training objective to align image-text input pairs. We show that this phenomenon induces a `similarity bias' - in which false negative and false positive errors occur due to bias in the similarities between images and the normal label text embeddings. To address this bias, we propose a novel methodology called BLISS which directly accounts for this similarity bias through the use of an auxiliary, external set of text inputs. BLISS is simple, it does not require strong inductive biases about anomalous behaviour nor an expensive training process, and it significantly outperforms baseline methods on benchmark image datasets, even when access to normal data is extremely limited.
ARES: Locally Adaptive Reconstruction-based Anomaly Scoring
Jun 15, 2022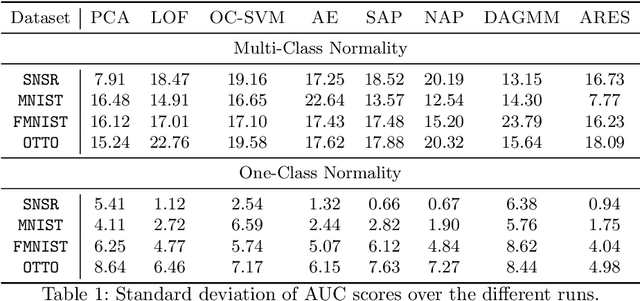
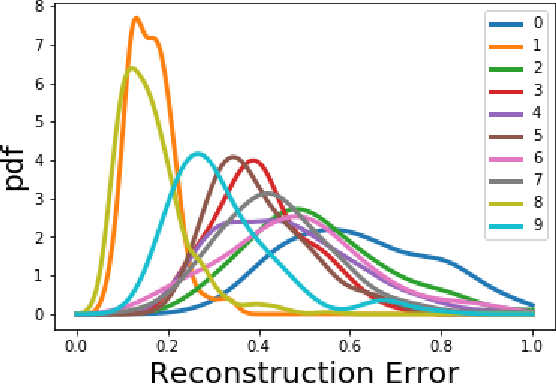
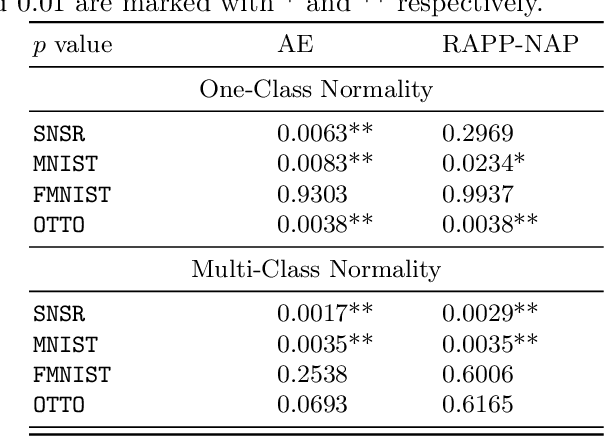
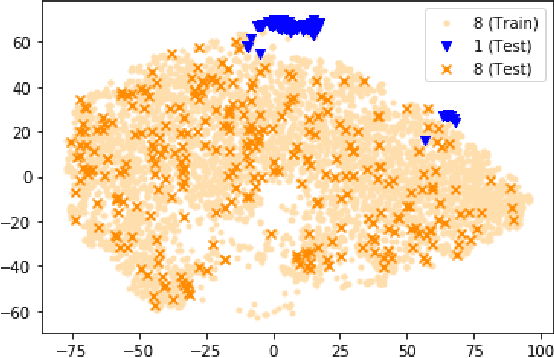
How can we detect anomalies: that is, samples that significantly differ from a given set of high-dimensional data, such as images or sensor data? This is a practical problem with numerous applications and is also relevant to the goal of making learning algorithms more robust to unexpected inputs. Autoencoders are a popular approach, partly due to their simplicity and their ability to perform dimension reduction. However, the anomaly scoring function is not adaptive to the natural variation in reconstruction error across the range of normal samples, which hinders their ability to detect real anomalies. In this paper, we empirically demonstrate the importance of local adaptivity for anomaly scoring in experiments with real data. We then propose our novel Adaptive Reconstruction Error-based Scoring approach, which adapts its scoring based on the local behaviour of reconstruction error over the latent space. We show that this improves anomaly detection performance over relevant baselines in a wide variety of benchmark datasets.
LUNAR: Unifying Local Outlier Detection Methods via Graph Neural Networks
Dec 10, 2021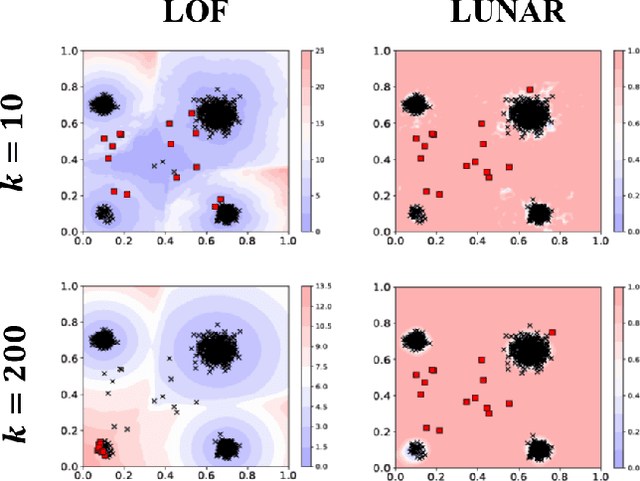
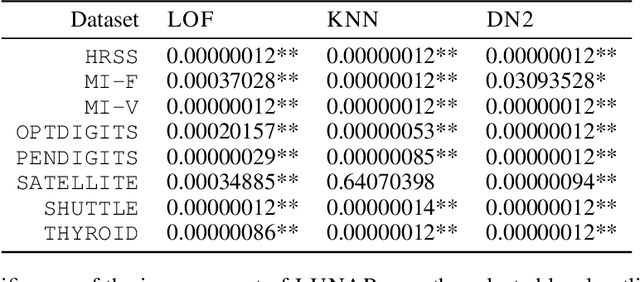
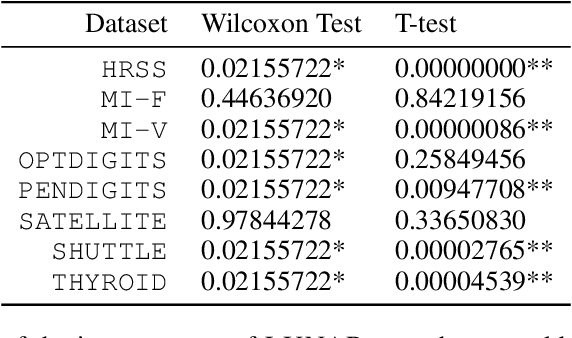
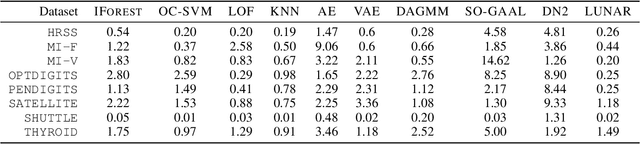
Many well-established anomaly detection methods use the distance of a sample to those in its local neighbourhood: so-called `local outlier methods', such as LOF and DBSCAN. They are popular for their simple principles and strong performance on unstructured, feature-based data that is commonplace in many practical applications. However, they cannot learn to adapt for a particular set of data due to their lack of trainable parameters. In this paper, we begin by unifying local outlier methods by showing that they are particular cases of the more general message passing framework used in graph neural networks. This allows us to introduce learnability into local outlier methods, in the form of a neural network, for greater flexibility and expressivity: specifically, we propose LUNAR, a novel, graph neural network-based anomaly detection method. LUNAR learns to use information from the nearest neighbours of each node in a trainable way to find anomalies. We show that our method performs significantly better than existing local outlier methods, as well as state-of-the-art deep baselines. We also show that the performance of our method is much more robust to different settings of the local neighbourhood size.