 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenEvolve: Self-Evolving Image Generation Agents via Tool-Orchestrated Visual Experience Distillation
May 20, 2026Open-ended image generation is no longer a simple prompt-to-image problem. High-quality generation often requires an agent to combine a model's internal generative ability with external resources. As requests become more diverse and demanding, we aim to develop a general image-generation agent that can self-evolve through trajectories and use tools more effectively across varied generation challenges. To this end, we propose GenEvolve, a self-evolving framework based on Tool-Orchestrated Visual Experience Distillation. In GenEvolve, each generation attempt is modeled as a tool-orchestrated trajectory, where the agent gathers evidence, selects references, invokes generation skills, and composes them into a prompt-reference program. Unlike existing agentic generation methods that mainly rely on image-level scalar rewards, GenEvolve compares multiple trajectories for the same request and abstracts best-worst differences into structured visual experience, provided only to a privileged teacher branch. Inspired by on-policy self-distillation, Visual Experience Distillation provides dense token-level supervision, helping the student internalize better search, knowledge activation, reference selection, and prompt construction. We further construct GenEvolve-Data and GenEvolve-Bench. Experiments on public benchmarks and GenEvolve-Bench show substantial gains over strong baselines, achieving state-of-the-art performance among current image-generation frameworks. Our website is as follows: https://ephemeral182.github.io/GenEvolve/
PosterOmni: Generalized Artistic Poster Creation via Task Distillation and Unified Reward Feedback
Feb 12, 2026Image-to-poster generation is a high-demand task requiring not only local adjustments but also high-level design understanding. Models must generate text, layout, style, and visual elements while preserving semantic fidelity and aesthetic coherence. The process spans two regimes: local editing, where ID-driven generation, rescaling, filling, and extending must preserve concrete visual entities; and global creation, where layout- and style-driven tasks rely on understanding abstract design concepts. These intertwined demands make image-to-poster a multi-dimensional process coupling entity-preserving editing with concept-driven creation under image-prompt control. To address these challenges, we propose PosterOmni, a generalized artistic poster creation framework that unlocks the potential of a base edit model for multi-task image-to-poster generation. PosterOmni integrates the two regimes, namely local editing and global creation, within a single system through an efficient data-distillation-reward pipeline: (i) constructing multi-scenario image-to-poster datasets covering six task types across entity-based and concept-based creation; (ii) distilling knowledge between local and global experts for supervised fine-tuning; and (iii) applying unified PosterOmni Reward Feedback to jointly align visual entity-preserving and aesthetic preference across all tasks. Additionally, we establish PosterOmni-Bench, a unified benchmark for evaluating both local editing and global creation. Extensive experiments show that PosterOmni significantly enhances reference adherence, global composition quality, and aesthetic harmony, outperforming all open-source baselines and even surpassing several proprietary systems.
IdentityStory: Taming Your Identity-Preserving Generator for Human-Centric Story Generation
Dec 29, 2025Recent visual generative models enable story generation with consistent characters from text, but human-centric story generation faces additional challenges, such as maintaining detailed and diverse human face consistency and coordinating multiple characters across different images. This paper presents IdentityStory, a framework for human-centric story generation that ensures consistent character identity across multiple sequential images. By taming identity-preserving generators, the framework features two key components: Iterative Identity Discovery, which extracts cohesive character identities, and Re-denoising Identity Injection, which re-denoises images to inject identities while preserving desired context. Experiments on the ConsiStory-Human benchmark demonstrate that IdentityStory outperforms existing methods, particularly in face consistency, and supports multi-character combinations. The framework also shows strong potential for applications such as infinite-length story generation and dynamic character composition.
DisCo-Layout: Disentangling and Coordinating Semantic and Physical Refinement in a Multi-Agent Framework for 3D Indoor Layout Synthesis
Oct 02, 2025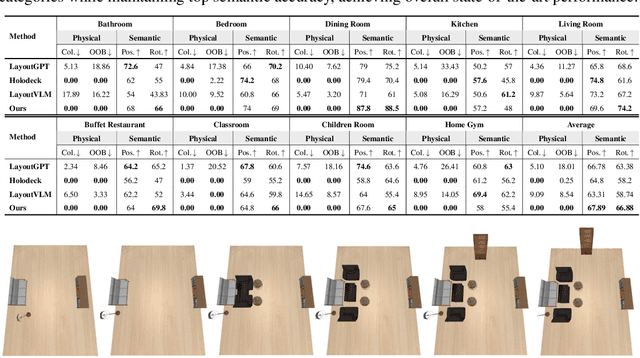
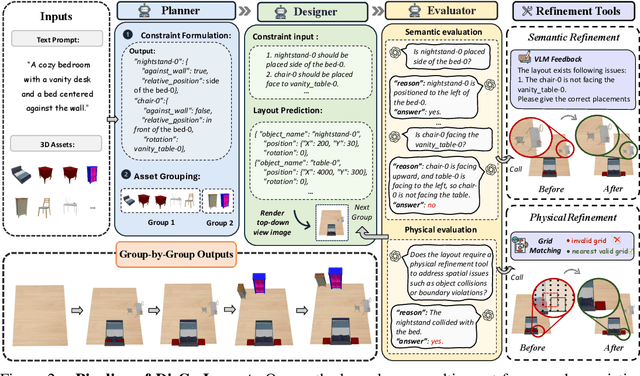
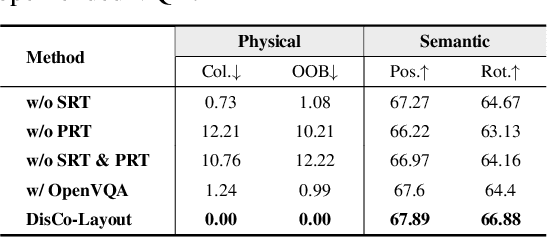
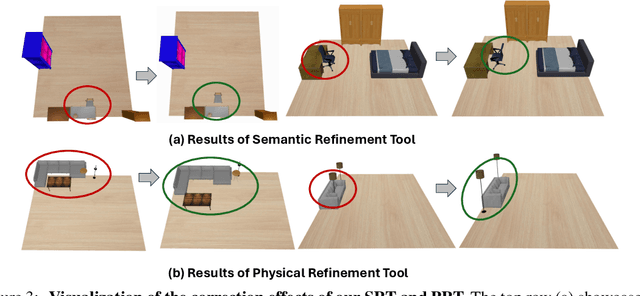
3D indoor layout synthesis is crucial for creating virtual environments. Traditional methods struggle with generalization due to fixed datasets. While recent LLM and VLM-based approaches offer improved semantic richness, they often lack robust and flexible refinement, resulting in suboptimal layouts. We develop DisCo-Layout, a novel framework that disentangles and coordinates physical and semantic refinement. For independent refinement, our Semantic Refinement Tool (SRT) corrects abstract object relationships, while the Physical Refinement Tool (PRT) resolves concrete spatial issues via a grid-matching algorithm. For collaborative refinement, a multi-agent framework intelligently orchestrates these tools, featuring a planner for placement rules, a designer for initial layouts, and an evaluator for assessment. Experiments demonstrate DisCo-Layout's state-of-the-art performance, generating realistic, coherent, and generalizable 3D indoor layouts. Our code will be publicly available.
DOMR: Establishing Cross-View Segmentation via Dense Object Matching
Aug 06, 2025Cross-view object correspondence involves matching objects between egocentric (first-person) and exocentric (third-person) views. It is a critical yet challenging task for visual understanding. In this work, we propose the Dense Object Matching and Refinement (DOMR) framework to establish dense object correspondences across views. The framework centers around the Dense Object Matcher (DOM) module, which jointly models multiple objects. Unlike methods that directly match individual object masks to image features, DOM leverages both positional and semantic relationships among objects to find correspondences. DOM integrates a proposal generation module with a dense matching module that jointly encodes visual, spatial, and semantic cues, explicitly constructing inter-object relationships to achieve dense matching among objects. Furthermore, we combine DOM with a mask refinement head designed to improve the completeness and accuracy of the predicted masks, forming the complete DOMR framework. Extensive evaluations on the Ego-Exo4D benchmark demonstrate that our approach achieves state-of-the-art performance with a mean IoU of 49.7% on Ego$\to$Exo and 55.2% on Exo$\to$Ego. These results outperform those of previous methods by 5.8% and 4.3%, respectively, validating the effectiveness of our integrated approach for cross-view understanding.
PosterCraft: Rethinking High-Quality Aesthetic Poster Generation in a Unified Framework
Jun 12, 2025
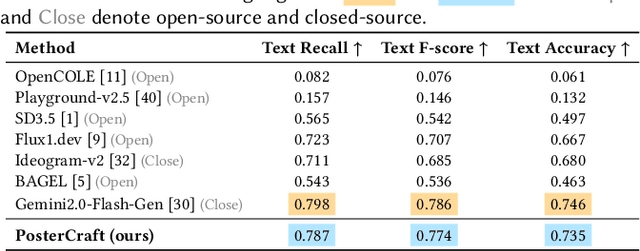
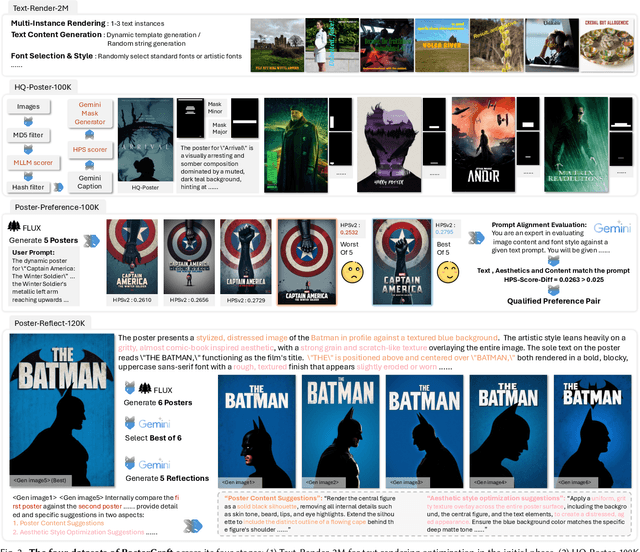
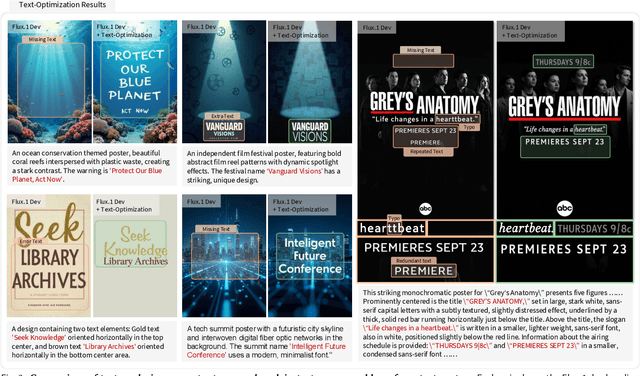
Generating aesthetic posters is more challenging than simple design images: it requires not only precise text rendering but also the seamless integration of abstract artistic content, striking layouts, and overall stylistic harmony. To address this, we propose PosterCraft, a unified framework that abandons prior modular pipelines and rigid, predefined layouts, allowing the model to freely explore coherent, visually compelling compositions. PosterCraft employs a carefully designed, cascaded workflow to optimize the generation of high-aesthetic posters: (i) large-scale text-rendering optimization on our newly introduced Text-Render-2M dataset; (ii) region-aware supervised fine-tuning on HQ-Poster100K; (iii) aesthetic-text-reinforcement learning via best-of-n preference optimization; and (iv) joint vision-language feedback refinement. Each stage is supported by a fully automated data-construction pipeline tailored to its specific needs, enabling robust training without complex architectural modifications. Evaluated on multiple experiments, PosterCraft significantly outperforms open-source baselines in rendering accuracy, layout coherence, and overall visual appeal-approaching the quality of SOTA commercial systems. Our code, models, and datasets can be found in the Project page: https://ephemeral182.github.io/PosterCraft
LayoutCoT: Unleashing the Deep Reasoning Potential of Large Language Models for Layout Generation
Apr 15, 2025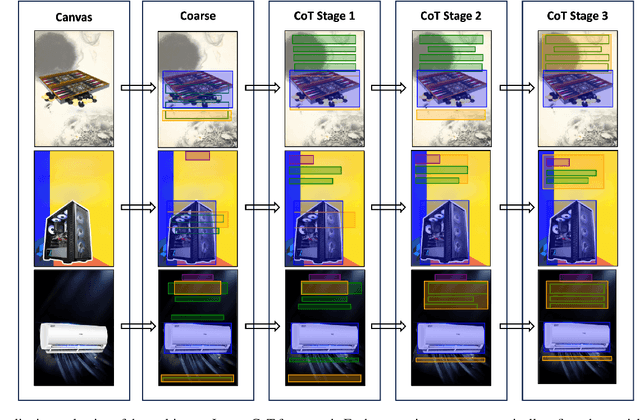
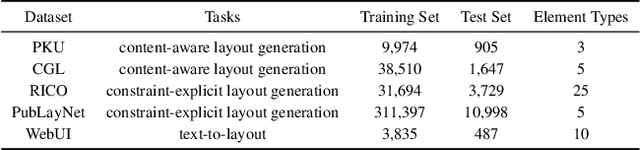
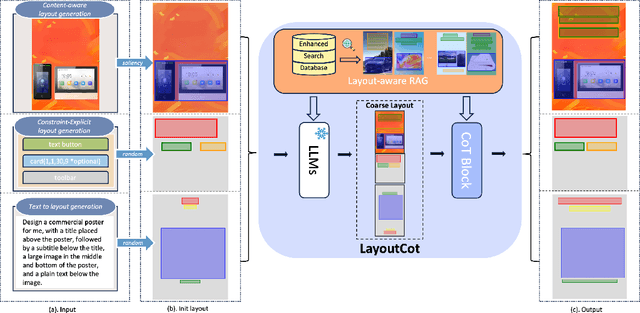
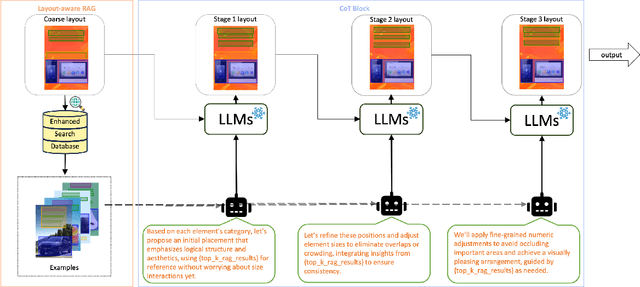
Conditional layout generation aims to automatically generate visually appealing and semantically coherent layouts from user-defined constraints. While recent methods based on generative models have shown promising results, they typically require substantial amounts of training data or extensive fine-tuning, limiting their versatility and practical applicability. Alternatively, some training-free approaches leveraging in-context learning with Large Language Models (LLMs) have emerged, but they often suffer from limited reasoning capabilities and overly simplistic ranking mechanisms, which restrict their ability to generate consistently high-quality layouts. To this end, we propose LayoutCoT, a novel approach that leverages the reasoning capabilities of LLMs through a combination of Retrieval-Augmented Generation (RAG) and Chain-of-Thought (CoT) techniques. Specifically, LayoutCoT transforms layout representations into a standardized serialized format suitable for processing by LLMs. A Layout-aware RAG is used to facilitate effective retrieval and generate a coarse layout by LLMs. This preliminary layout, together with the selected exemplars, is then fed into a specially designed CoT reasoning module for iterative refinement, significantly enhancing both semantic coherence and visual quality. We conduct extensive experiments on five public datasets spanning three conditional layout generation tasks. Experimental results demonstrate that LayoutCoT achieves state-of-the-art performance without requiring training or fine-tuning. Notably, our CoT reasoning module enables standard LLMs, even those without explicit deep reasoning abilities, to outperform specialized deep-reasoning models such as deepseek-R1, highlighting the potential of our approach in unleashing the deep reasoning capabilities of LLMs for layout generation tasks.
COST: Contrastive One-Stage Transformer for Vision-Language Small Object Tracking
Apr 02, 2025Transformer has recently demonstrated great potential in improving vision-language (VL) tracking algorithms. However, most of the existing VL trackers rely on carefully designed mechanisms to perform the multi-stage multi-modal fusion. Additionally, direct multi-modal fusion without alignment ignores distribution discrepancy between modalities in feature space, potentially leading to suboptimal representations. In this work, we propose COST, a contrastive one-stage transformer fusion framework for VL tracking, aiming to learn semantically consistent and unified VL representations. Specifically, we introduce a contrastive alignment strategy that maximizes mutual information (MI) between a video and its corresponding language description. This enables effective cross-modal alignment, yielding semantically consistent features in the representation space. By leveraging a visual-linguistic transformer, we establish an efficient multi-modal fusion and reasoning mechanism, empirically demonstrating that a simple stack of transformer encoders effectively enables unified VL representations. Moreover, we contribute a newly collected VL tracking benchmark dataset for small object tracking, named VL-SOT500, with bounding boxes and language descriptions. Our dataset comprises two challenging subsets, VL-SOT230 and VL-SOT270, dedicated to evaluating generic and high-speed small object tracking, respectively. Small object tracking is notoriously challenging due to weak appearance and limited features, and this dataset is, to the best of our knowledge, the first to explore the usage of language cues to enhance visual representation for small object tracking. Extensive experiments demonstrate that COST achieves state-of-the-art performance on five existing VL tracking datasets, as well as on our proposed VL-SOT500 dataset. Source codes and dataset will be made publicly available.
SciVerse: Unveiling the Knowledge Comprehension and Visual Reasoning of LMMs on Multi-modal Scientific Problems
Mar 13, 2025The rapid advancement of Large Multi-modal Models (LMMs) has enabled their application in scientific problem-solving, yet their fine-grained capabilities remain under-explored. In this paper, we introduce SciVerse, a multi-modal scientific evaluation benchmark to thoroughly assess LMMs across 5,735 test instances in five distinct versions. We aim to investigate three key dimensions of LMMs: scientific knowledge comprehension, multi-modal content interpretation, and Chain-of-Thought (CoT) reasoning. To unveil whether LMMs possess sufficient scientific expertise, we first transform each problem into three versions containing different levels of knowledge required for solving, i.e., Knowledge-free, -lite, and -rich. Then, to explore how LMMs interpret multi-modal scientific content, we annotate another two versions, i.e., Vision-rich and -only, marking more question information from texts to diagrams. Comparing the results of different versions, SciVerse systematically examines the professional knowledge stock and visual perception skills of LMMs in scientific domains. In addition, to rigorously assess CoT reasoning, we propose a new scientific CoT evaluation strategy, conducting a step-wise assessment on knowledge and logical errors in model outputs. Our extensive evaluation of different LMMs on SciVerse reveals critical limitations in their scientific proficiency and provides new insights into future developments. Project page: https://sciverse-cuhk.github.io
LLaVA-ST: A Multimodal Large Language Model for Fine-Grained Spatial-Temporal Understanding
Jan 14, 2025Recent advancements in multimodal large language models (MLLMs) have shown promising results, yet existing approaches struggle to effectively handle both temporal and spatial localization simultaneously. This challenge stems from two key issues: first, incorporating spatial-temporal localization introduces a vast number of coordinate combinations, complicating the alignment of linguistic and visual coordinate representations; second, encoding fine-grained temporal and spatial information during video feature compression is inherently difficult. To address these issues, we propose LLaVA-ST, a MLLM for fine-grained spatial-temporal multimodal understanding. In LLaVA-ST, we propose Language-Aligned Positional Embedding, which embeds the textual coordinate special token into the visual space, simplifying the alignment of fine-grained spatial-temporal correspondences. Additionally, we design the Spatial-Temporal Packer, which decouples the feature compression of temporal and spatial resolutions into two distinct point-to-region attention processing streams. Furthermore, we propose ST-Align dataset with 4.3M training samples for fine-grained spatial-temporal multimodal understanding. With ST-align, we present a progressive training pipeline that aligns the visual and textual feature through sequential coarse-to-fine stages.Additionally, we introduce an ST-Align benchmark to evaluate spatial-temporal interleaved fine-grained understanding tasks, which include Spatial-Temporal Video Grounding (STVG) , Event Localization and Captioning (ELC) and Spatial Video Grounding (SVG). LLaVA-ST achieves outstanding performance on 11 benchmarks requiring fine-grained temporal, spatial, or spatial-temporal interleaving multimodal understanding. Our code, data and benchmark will be released at Our code, data and benchmark will be released at https://github.com/appletea233/LLaVA-ST .