 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoAuto-R1: Video Auto Reasoning via Thinking Once, Answering Twice
Jan 08, 2026Chain-of-thought (CoT) reasoning has emerged as a powerful tool for multimodal large language models on video understanding tasks. However, its necessity and advantages over direct answering remain underexplored. In this paper, we first demonstrate that for RL-trained video models, direct answering often matches or even surpasses CoT performance, despite CoT producing step-by-step analyses at a higher computational cost. Motivated by this, we propose VideoAuto-R1, a video understanding framework that adopts a reason-when-necessary strategy. During training, our approach follows a Thinking Once, Answering Twice paradigm: the model first generates an initial answer, then performs reasoning, and finally outputs a reviewed answer. Both answers are supervised via verifiable rewards. During inference, the model uses the confidence score of the initial answer to determine whether to proceed with reasoning. Across video QA and grounding benchmarks, VideoAuto-R1 achieves state-of-the-art accuracy with significantly improved efficiency, reducing the average response length by ~3.3x, e.g., from 149 to just 44 tokens. Moreover, we observe a low rate of thinking-mode activation on perception-oriented tasks, but a higher rate on reasoning-intensive tasks. This suggests that explicit language-based reasoning is generally beneficial but not always necessary.
Mixture of States: Routing Token-Level Dynamics for Multimodal Generation
Nov 15, 2025We introduce MoS (Mixture of States), a novel fusion paradigm for multimodal diffusion models that merges modalities using flexible, state-based interactions. The core of MoS is a learnable, token-wise router that creates denoising timestep- and input-dependent interactions between modalities' hidden states, precisely aligning token-level features with the diffusion trajectory. This router sparsely selects the top-$k$ hidden states and is trained with an $ε$-greedy strategy, efficiently selecting contextual features with minimal learnable parameters and negligible computational overhead. We validate our design with text-to-image generation (MoS-Image) and editing (MoS-Editing), which achieve state-of-the-art results. With only 3B to 5B parameters, our models match or surpass counterparts up to $4\times$ larger. These findings establish MoS as a flexible and compute-efficient paradigm for scaling multimodal diffusion models.
BOLT: Boost Large Vision-Language Model Without Training for Long-form Video Understanding
Mar 27, 2025



Large video-language models (VLMs) have demonstrated promising progress in various video understanding tasks. However, their effectiveness in long-form video analysis is constrained by limited context windows. Traditional approaches, such as uniform frame sampling, often inevitably allocate resources to irrelevant content, diminishing their effectiveness in real-world scenarios. In this paper, we introduce BOLT, a method to BOost Large VLMs without additional Training through a comprehensive study of frame selection strategies. First, to enable a more realistic evaluation of VLMs in long-form video understanding, we propose a multi-source retrieval evaluation setting. Our findings reveal that uniform sampling performs poorly in noisy contexts, underscoring the importance of selecting the right frames. Second, we explore several frame selection strategies based on query-frame similarity and analyze their effectiveness at inference time. Our results show that inverse transform sampling yields the most significant performance improvement, increasing accuracy on the Video-MME benchmark from 53.8% to 56.1% and MLVU benchmark from 58.9% to 63.4%. Our code is available at https://github.com/sming256/BOLT.
TimeLoc: A Unified End-to-End Framework for Precise Timestamp Localization in Long Videos
Mar 09, 2025
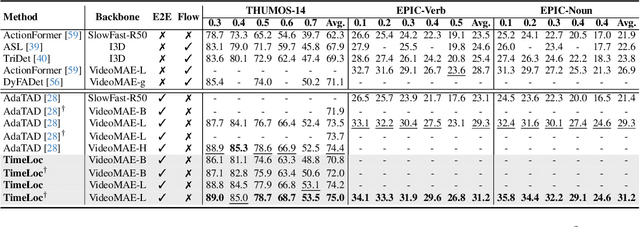
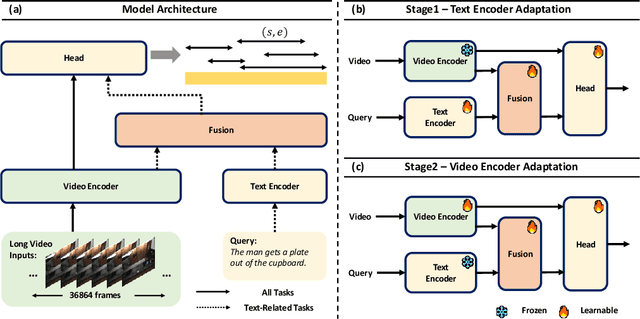
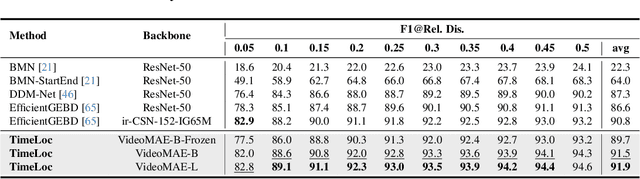
Temporal localization in untrimmed videos, which aims to identify specific timestamps, is crucial for video understanding but remains challenging. This task encompasses several subtasks, including temporal action localization, temporal video grounding, moment retrieval, and generic event boundary detection. Existing methods in each subfield are typically designed for specific tasks and lack generalizability across domains. In this paper, we propose TimeLoc, a unified end-to-end framework for timestamp localization that can handle multiple tasks. First, our approach employs a simple yet effective one-stage localization model that supports text queries as input and multiple actions as output. Second, we jointly train the video encoder and localization model in an end-to-end manner. To efficiently process long videos, we introduce temporal chunking, enabling the handling of videos with over 30k frames. Third, we find that fine-tuning pre-trained text encoders with a multi-stage training strategy further enhances text-conditioned localization. TimeLoc achieves state-of-the-art results across multiple benchmarks: +1.3% and +1.9% mAP over previous best methods on THUMOS14 and EPIC-Kitchens-100, +1.1% on Kinetics-GEBD, +2.94% mAP on QVHighlights, and significant improvements in temporal video grounding (+11.5% on TACoS and +6.7% on Charades-STA under R1@0.5). Our code and checkpoints will be released at https://github.com/sming256/TimeLoc.
OpenTAD: A Unified Framework and Comprehensive Study of Temporal Action Detection
Feb 27, 2025Temporal action detection (TAD) is a fundamental video understanding task that aims to identify human actions and localize their temporal boundaries in videos. Although this field has achieved remarkable progress in recent years, further progress and real-world applications are impeded by the absence of a standardized framework. Currently, different methods are compared under different implementation settings, evaluation protocols, etc., making it difficult to assess the real effectiveness of a specific technique. To address this issue, we propose \textbf{OpenTAD}, a unified TAD framework consolidating 16 different TAD methods and 9 standard datasets into a modular codebase. In OpenTAD, minimal effort is required to replace one module with a different design, train a feature-based TAD model in end-to-end mode, or switch between the two. OpenTAD also facilitates straightforward benchmarking across various datasets and enables fair and in-depth comparisons among different methods. With OpenTAD, we comprehensively study how innovations in different network components affect detection performance and identify the most effective design choices through extensive experiments. This study has led to a new state-of-the-art TAD method built upon existing techniques for each component. We have made our code and models available at https://github.com/sming256/OpenTAD.
Harnessing Temporal Causality for Advanced Temporal Action Detection
Jul 26, 2024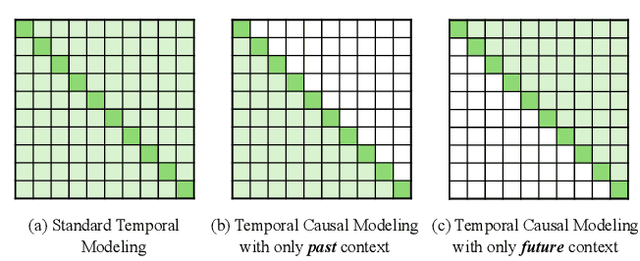

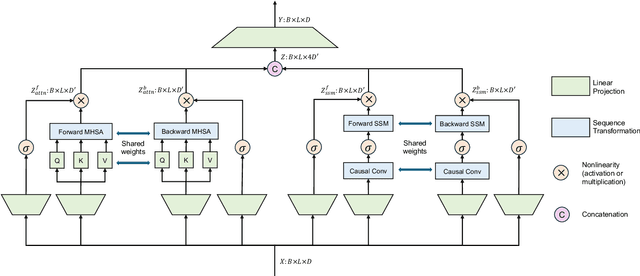

As a fundamental task in long-form video understanding, temporal action detection (TAD) aims to capture inherent temporal relations in untrimmed videos and identify candidate actions with precise boundaries. Over the years, various networks, including convolutions, graphs, and transformers, have been explored for effective temporal modeling for TAD. However, these modules typically treat past and future information equally, overlooking the crucial fact that changes in action boundaries are essentially causal events. Inspired by this insight, we propose leveraging the temporal causality of actions to enhance TAD representation by restricting the model's access to only past or future context. We introduce CausalTAD, which combines causal attention and causal Mamba to achieve state-of-the-art performance on multiple benchmarks. Notably, with CausalTAD, we ranked 1st in the Action Recognition, Action Detection, and Audio-Based Interaction Detection tracks at the EPIC-Kitchens Challenge 2024, as well as 1st in the Moment Queries track at the Ego4D Challenge 2024. Our code is available at https://github.com/sming256/OpenTAD/.
ColorMAE: Exploring data-independent masking strategies in Masked AutoEncoders
Jul 17, 2024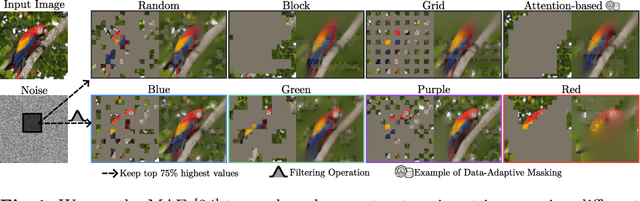

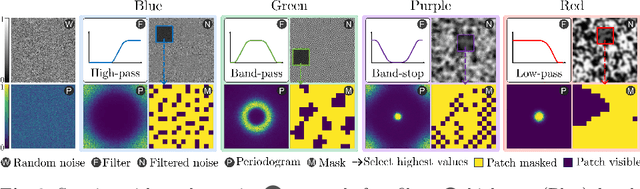

Masked AutoEncoders (MAE) have emerged as a robust self-supervised framework, offering remarkable performance across a wide range of downstream tasks. To increase the difficulty of the pretext task and learn richer visual representations, existing works have focused on replacing standard random masking with more sophisticated strategies, such as adversarial-guided and teacher-guided masking. However, these strategies depend on the input data thus commonly increasing the model complexity and requiring additional calculations to generate the mask patterns. This raises the question: Can we enhance MAE performance beyond random masking without relying on input data or incurring additional computational costs? In this work, we introduce a simple yet effective data-independent method, termed ColorMAE, which generates different binary mask patterns by filtering random noise. Drawing inspiration from color noise in image processing, we explore four types of filters to yield mask patterns with different spatial and semantic priors. ColorMAE requires no additional learnable parameters or computational overhead in the network, yet it significantly enhances the learned representations. We provide a comprehensive empirical evaluation, demonstrating our strategy's superiority in downstream tasks compared to random masking. Notably, we report an improvement of 2.72 in mIoU in semantic segmentation tasks relative to baseline MAE implementations.
Dr$^2$Net: Dynamic Reversible Dual-Residual Networks for Memory-Efficient Finetuning
Jan 08, 2024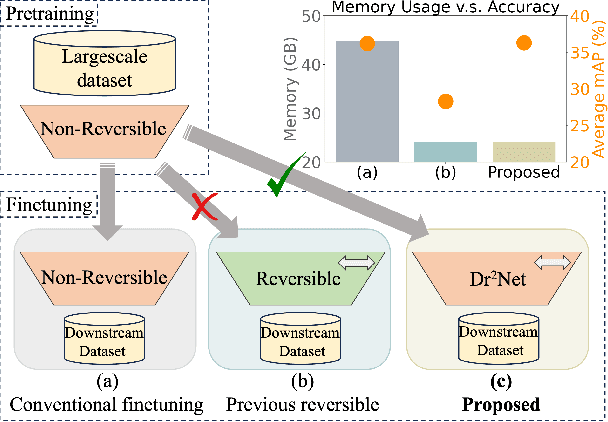

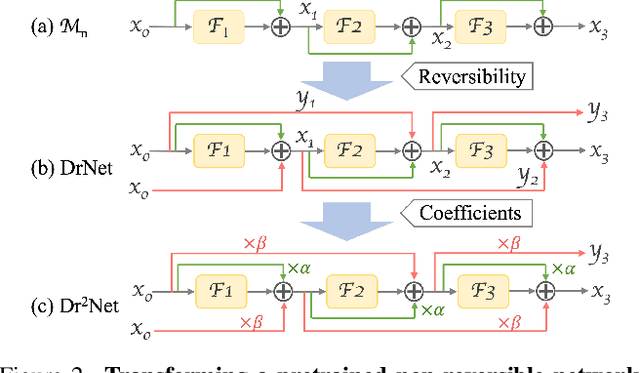
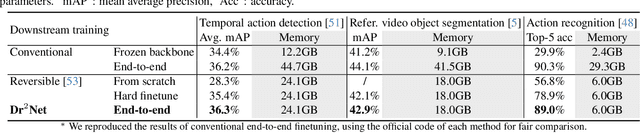
Large pretrained models are increasingly crucial in modern computer vision tasks. These models are typically used in downstream tasks by end-to-end finetuning, which is highly memory-intensive for tasks with high-resolution data, e.g., video understanding, small object detection, and point cloud analysis. In this paper, we propose Dynamic Reversible Dual-Residual Networks, or Dr$^2$Net, a novel family of network architectures that acts as a surrogate network to finetune a pretrained model with substantially reduced memory consumption. Dr$^2$Net contains two types of residual connections, one maintaining the residual structure in the pretrained models, and the other making the network reversible. Due to its reversibility, intermediate activations, which can be reconstructed from output, are cleared from memory during training. We use two coefficients on either type of residual connections respectively, and introduce a dynamic training strategy that seamlessly transitions the pretrained model to a reversible network with much higher numerical precision. We evaluate Dr$^2$Net on various pretrained models and various tasks, and show that it can reach comparable performance to conventional finetuning but with significantly less memory usage.
End-to-End Temporal Action Detection with 1B Parameters Across 1000 Frames
Nov 28, 2023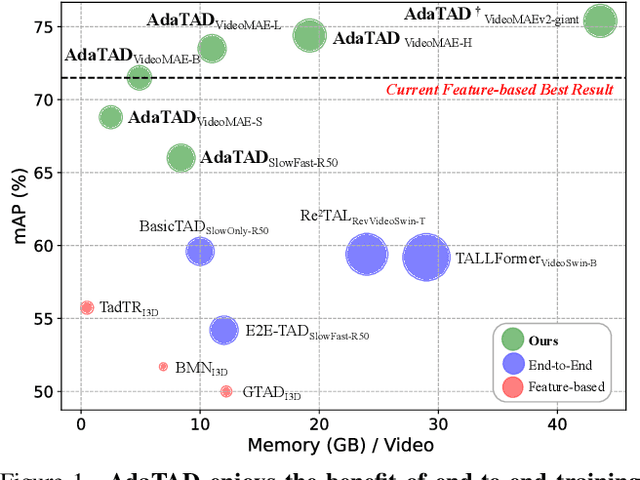



Recently, temporal action detection (TAD) has seen significant performance improvement with end-to-end training. However, due to the memory bottleneck, only models with limited scales and limited data volumes can afford end-to-end training, which inevitably restricts TAD performance. In this paper, we reduce the memory consumption for end-to-end training, and manage to scale up the TAD backbone to 1 billion parameters and the input video to 1,536 frames, leading to significant detection performance. The key to our approach lies in our proposed temporal-informative adapter (TIA), which is a novel lightweight module that reduces training memory. Using TIA, we free the humongous backbone from learning to adapt to the TAD task by only updating the parameters in TIA. TIA also leads to better TAD representation by temporally aggregating context from adjacent frames throughout the backbone. We evaluate our model across four representative datasets. Owing to our efficient design, we are able to train end-to-end on VideoMAEv2-giant and achieve 75.4% mAP on THUMOS14, being the first end-to-end model to outperform the best feature-based methods.
Mindstorms in Natural Language-Based Societies of Mind
May 26, 2023



Both Minsky's "society of mind" and Schmidhuber's "learning to think" inspire diverse societies of large multimodal neural networks (NNs) that solve problems by interviewing each other in a "mindstorm." Recent implementations of NN-based societies of minds consist of large language models (LLMs) and other NN-based experts communicating through a natural language interface. In doing so, they overcome the limitations of single LLMs, improving multimodal zero-shot reasoning. In these natural language-based societies of mind (NLSOMs), new agents -- all communicating through the same universal symbolic language -- are easily added in a modular fashion. To demonstrate the power of NLSOMs, we assemble and experiment with several of them (having up to 129 members), leveraging mindstorms in them to solve some practical AI tasks: visual question answering, image captioning, text-to-image synthesis, 3D generation, egocentric retrieval, embodied AI, and general language-based task solving. We view this as a starting point towards much larger NLSOMs with billions of agents-some of which may be humans. And with this emergence of great societies of heterogeneous minds, many new research questions have suddenly become paramount to the future of artificial intelligence. What should be the social structure of an NLSOM? What would be the (dis)advantages of having a monarchical rather than a democratic structure? How can principles of NN economies be used to maximize the total reward of a reinforcement learning NLSOM? In this work, we identify, discuss, and try to answer some of these questions.