 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$β$-CLIP: Text-Conditioned Contrastive Learning for Multi-Granular Vision-Language Alignment
Dec 14, 2025CLIP achieves strong zero-shot image-text retrieval by aligning global vision and text representations, yet it falls behind on fine-grained tasks even when fine-tuned on long, detailed captions. In this work, we propose $β$-CLIP, a multi-granular text-conditioned contrastive learning framework designed to achieve hierarchical alignment between multiple textual granularities-from full captions to sentences and phrases-and their corresponding visual regions. For each level of granularity, $β$-CLIP utilizes cross-attention to dynamically pool image patches, producing contextualized visual embeddings. To address the semantic overlap inherent in this hierarchy, we introduce the $β$-Contextualized Contrastive Alignment Loss ($β$-CAL). This objective parameterizes the trade-off between strict query-specific matching and relaxed intra-image contextualization, supporting both soft Cross-Entropy and hard Binary Cross-Entropy formulations. Through extensive experiments, we demonstrate that $β$-CLIP significantly improves dense alignment: achieving 91.8% T2I 92.3% I2T at R@1 on Urban1K and 30.9% on FG-OVD (Hard), setting state-of-the-art among methods trained without hard negatives. $β$-CLIP establishes a robust, adaptive baseline for dense vision-language correspondence. The code and models are released at https://github.com/fzohra/B-CLIP.
OpenTAD: A Unified Framework and Comprehensive Study of Temporal Action Detection
Feb 27, 2025Temporal action detection (TAD) is a fundamental video understanding task that aims to identify human actions and localize their temporal boundaries in videos. Although this field has achieved remarkable progress in recent years, further progress and real-world applications are impeded by the absence of a standardized framework. Currently, different methods are compared under different implementation settings, evaluation protocols, etc., making it difficult to assess the real effectiveness of a specific technique. To address this issue, we propose \textbf{OpenTAD}, a unified TAD framework consolidating 16 different TAD methods and 9 standard datasets into a modular codebase. In OpenTAD, minimal effort is required to replace one module with a different design, train a feature-based TAD model in end-to-end mode, or switch between the two. OpenTAD also facilitates straightforward benchmarking across various datasets and enables fair and in-depth comparisons among different methods. With OpenTAD, we comprehensively study how innovations in different network components affect detection performance and identify the most effective design choices through extensive experiments. This study has led to a new state-of-the-art TAD method built upon existing techniques for each component. We have made our code and models available at https://github.com/sming256/OpenTAD.
Dr$^2$Net: Dynamic Reversible Dual-Residual Networks for Memory-Efficient Finetuning
Jan 08, 2024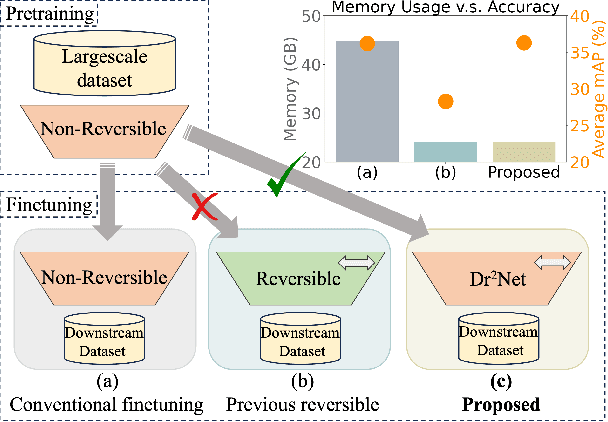

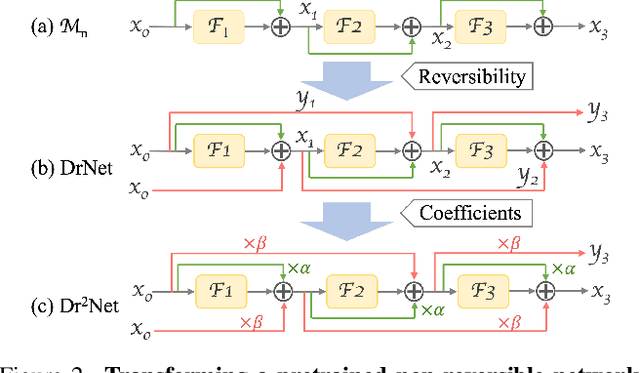
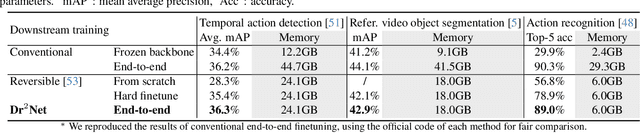
Large pretrained models are increasingly crucial in modern computer vision tasks. These models are typically used in downstream tasks by end-to-end finetuning, which is highly memory-intensive for tasks with high-resolution data, e.g., video understanding, small object detection, and point cloud analysis. In this paper, we propose Dynamic Reversible Dual-Residual Networks, or Dr$^2$Net, a novel family of network architectures that acts as a surrogate network to finetune a pretrained model with substantially reduced memory consumption. Dr$^2$Net contains two types of residual connections, one maintaining the residual structure in the pretrained models, and the other making the network reversible. Due to its reversibility, intermediate activations, which can be reconstructed from output, are cleared from memory during training. We use two coefficients on either type of residual connections respectively, and introduce a dynamic training strategy that seamlessly transitions the pretrained model to a reversible network with much higher numerical precision. We evaluate Dr$^2$Net on various pretrained models and various tasks, and show that it can reach comparable performance to conventional finetuning but with significantly less memory usage.