 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixels or Positions? Benchmarking Modalities in Group Activity Recognition
Nov 16, 2025Group Activity Recognition (GAR) is well studied on the video modality for surveillance and indoor team sports (e.g., volleyball, basketball). Yet, other modalities such as agent positions and trajectories over time, i.e. tracking, remain comparatively under-explored despite being compact, agent-centric signals that explicitly encode spatial interactions. Understanding whether pixel (video) or position (tracking) modalities leads to better group activity recognition is therefore important to drive further research on the topic. However, no standardized benchmark currently exists that aligns broadcast video and tracking data for the same group activities, leading to a lack of apples-to-apples comparison between these modalities for GAR. In this work, we introduce SoccerNet-GAR, a multimodal dataset built from the $64$ matches of the football World Cup 2022. Specifically, the broadcast videos and player tracking modalities for $94{,}285$ group activities are synchronized and annotated with $10$ categories. Furthermore, we define a unified evaluation protocol to benchmark two strong unimodal approaches: (i) a competitive video-based classifiers and (ii) a tracking-based classifiers leveraging graph neural networks. In particular, our novel role-aware graph architecture for tracking-based GAR directly encodes tactical structure through positional edges and temporal attention. Our tracking model achieves $67.2\%$ balanced accuracy compared to $58.1\%$ for the best video baseline, while training $4.25 \times$ faster with $438 \times$ fewer parameters ($197K$ \vs $86.3M$). This study provides new insights into the relative strengths of pixels and positions for group activity recognition. Overall, it highlights the importance of modality choice and role-aware modeling for GAR.
SoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
Triangle Splatting for Real-Time Radiance Field Rendering
May 25, 2025



The field of computer graphics was revolutionized by models such as Neural Radiance Fields and 3D Gaussian Splatting, displacing triangles as the dominant representation for photogrammetry. In this paper, we argue for a triangle comeback. We develop a differentiable renderer that directly optimizes triangles via end-to-end gradients. We achieve this by rendering each triangle as differentiable splats, combining the efficiency of triangles with the adaptive density of representations based on independent primitives. Compared to popular 2D and 3D Gaussian Splatting methods, our approach achieves higher visual fidelity, faster convergence, and increased rendering throughput. On the Mip-NeRF360 dataset, our method outperforms concurrent non-volumetric primitives in visual fidelity and achieves higher perceptual quality than the state-of-the-art Zip-NeRF on indoor scenes. Triangles are simple, compatible with standard graphics stacks and GPU hardware, and highly efficient: for the \textit{Garden} scene, we achieve over 2,400 FPS at 1280x720 resolution using an off-the-shelf mesh renderer. These results highlight the efficiency and effectiveness of triangle-based representations for high-quality novel view synthesis. Triangles bring us closer to mesh-based optimization by combining classical computer graphics with modern differentiable rendering frameworks. The project page is https://trianglesplatting.github.io/
Action Anticipation from SoccerNet Football Video Broadcasts
Apr 16, 2025Artificial intelligence has revolutionized the way we analyze sports videos, whether to understand the actions of games in long untrimmed videos or to anticipate the player's motion in future frames. Despite these efforts, little attention has been given to anticipating game actions before they occur. In this work, we introduce the task of action anticipation for football broadcast videos, which consists in predicting future actions in unobserved future frames, within a five- or ten-second anticipation window. To benchmark this task, we release a new dataset, namely the SoccerNet Ball Action Anticipation dataset, based on SoccerNet Ball Action Spotting. Additionally, we propose a Football Action ANticipation TRAnsformer (FAANTRA), a baseline method that adapts FUTR, a state-of-the-art action anticipation model, to predict ball-related actions. To evaluate action anticipation, we introduce new metrics, including mAP@$\delta$, which evaluates the temporal precision of predicted future actions, as well as mAP@$\infty$, which evaluates their occurrence within the anticipation window. We also conduct extensive ablation studies to examine the impact of various task settings, input configurations, and model architectures. Experimental results highlight both the feasibility and challenges of action anticipation in football videos, providing valuable insights into the design of predictive models for sports analytics. By forecasting actions before they unfold, our work will enable applications in automated broadcasting, tactical analysis, and player decision-making. Our dataset and code are publicly available at https://github.com/MohamadDalal/FAANTRA.
OpenTAD: A Unified Framework and Comprehensive Study of Temporal Action Detection
Feb 27, 2025Temporal action detection (TAD) is a fundamental video understanding task that aims to identify human actions and localize their temporal boundaries in videos. Although this field has achieved remarkable progress in recent years, further progress and real-world applications are impeded by the absence of a standardized framework. Currently, different methods are compared under different implementation settings, evaluation protocols, etc., making it difficult to assess the real effectiveness of a specific technique. To address this issue, we propose \textbf{OpenTAD}, a unified TAD framework consolidating 16 different TAD methods and 9 standard datasets into a modular codebase. In OpenTAD, minimal effort is required to replace one module with a different design, train a feature-based TAD model in end-to-end mode, or switch between the two. OpenTAD also facilitates straightforward benchmarking across various datasets and enables fair and in-depth comparisons among different methods. With OpenTAD, we comprehensively study how innovations in different network components affect detection performance and identify the most effective design choices through extensive experiments. This study has led to a new state-of-the-art TAD method built upon existing techniques for each component. We have made our code and models available at https://github.com/sming256/OpenTAD.
A Hitchhiker's Guide to Understanding Performances of Two-Class Classifiers
Dec 05, 2024Properly understanding the performances of classifiers is essential in various scenarios. However, the literature often relies only on one or two standard scores to compare classifiers, which fails to capture the nuances of application-specific requirements, potentially leading to suboptimal classifier selection. Recently, a paper on the foundations of the theory of performance-based ranking introduced a tool, called the Tile, that organizes an infinity of ranking scores into a 2D map. Thanks to the Tile, it is now possible to evaluate and compare classifiers efficiently, displaying all possible application-specific preferences instead of having to rely on a pair of scores. In this paper, we provide a first hitchhiker's guide for understanding the performances of two-class classifiers by presenting four scenarios, each showcasing a different user profile: a theoretical analyst, a method designer, a benchmarker, and an application developer. Particularly, we show that we can provide different interpretative flavors that are adapted to the user's needs by mapping different values on the Tile. As an illustration, we leverage the newly introduced Tile tool and the different flavors to rank and analyze the performances of 74 state-of-the-art semantic segmentation models in two-class classification through the eyes of the four user profiles. Through these user profiles, we demonstrate that the Tile effectively captures the behavior of classifiers in a single visualization, while accommodating an infinite number of ranking scores.
Foundations of the Theory of Performance-Based Ranking
Dec 05, 2024
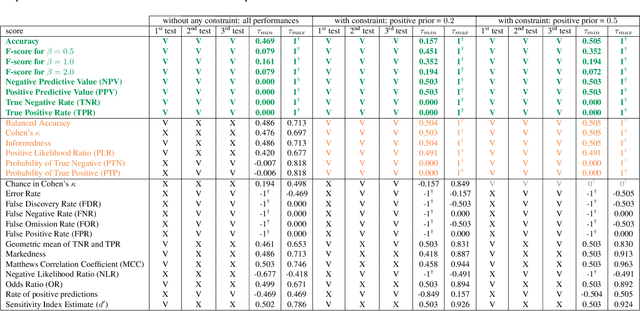
Ranking entities such as algorithms, devices, methods, or models based on their performances, while accounting for application-specific preferences, is a challenge. To address this challenge, we establish the foundations of a universal theory for performance-based ranking. First, we introduce a rigorous framework built on top of both the probability and order theories. Our new framework encompasses the elements necessary to (1) manipulate performances as mathematical objects, (2) express which performances are worse than or equivalent to others, (3) model tasks through a variable called satisfaction, (4) consider properties of the evaluation, (5) define scores, and (6) specify application-specific preferences through a variable called importance. On top of this framework, we propose the first axiomatic definition of performance orderings and performance-based rankings. Then, we introduce a universal parametric family of scores, called ranking scores, that can be used to establish rankings satisfying our axioms, while considering application-specific preferences. Finally, we show, in the case of two-class classification, that the family of ranking scores encompasses well-known performance scores, including the accuracy, the true positive rate (recall, sensitivity), the true negative rate (specificity), the positive predictive value (precision), and F1. However, we also show that some other scores commonly used to compare classifiers are unsuitable to derive performance orderings satisfying the axioms. Therefore, this paper provides the computer vision and machine learning communities with a rigorous framework for evaluating and ranking entities.
The Tile: A 2D Map of Ranking Scores for Two-Class Classification
Dec 05, 2024



In the computer vision and machine learning communities, as well as in many other research domains, rigorous evaluation of any new method, including classifiers, is essential. One key component of the evaluation process is the ability to compare and rank methods. However, ranking classifiers and accurately comparing their performances, especially when taking application-specific preferences into account, remains challenging. For instance, commonly used evaluation tools like Receiver Operating Characteristic (ROC) and Precision/Recall (PR) spaces display performances based on two scores. Hence, they are inherently limited in their ability to compare classifiers across a broader range of scores and lack the capability to establish a clear ranking among classifiers. In this paper, we present a novel versatile tool, named the Tile, that organizes an infinity of ranking scores in a single 2D map for two-class classifiers, including common evaluation scores such as the accuracy, the true positive rate, the positive predictive value, Jaccard's coefficient, and all F-beta scores. Furthermore, we study the properties of the underlying ranking scores, such as the influence of the priors or the correspondences with the ROC space, and depict how to characterize any other score by comparing them to the Tile. Overall, we demonstrate that the Tile is a powerful tool that effectively captures all the rankings in a single visualization and allows interpreting them.
3D Convex Splatting: Radiance Field Rendering with 3D Smooth Convexes
Nov 26, 2024


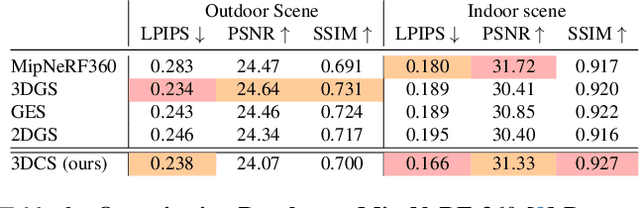
Recent advances in radiance field reconstruction, such as 3D Gaussian Splatting (3DGS), have achieved high-quality novel view synthesis and fast rendering by representing scenes with compositions of Gaussian primitives. However, 3D Gaussians present several limitations for scene reconstruction. Accurately capturing hard edges is challenging without significantly increasing the number of Gaussians, creating a large memory footprint. Moreover, they struggle to represent flat surfaces, as they are diffused in space. Without hand-crafted regularizers, they tend to disperse irregularly around the actual surface. To circumvent these issues, we introduce a novel method, named 3D Convex Splatting (3DCS), which leverages 3D smooth convexes as primitives for modeling geometrically-meaningful radiance fields from multi-view images. Smooth convex shapes offer greater flexibility than Gaussians, allowing for a better representation of 3D scenes with hard edges and dense volumes using fewer primitives. Powered by our efficient CUDA-based rasterizer, 3DCS achieves superior performance over 3DGS on benchmarks such as Mip-NeRF360, Tanks and Temples, and Deep Blending. Specifically, our method attains an improvement of up to 0.81 in PSNR and 0.026 in LPIPS compared to 3DGS while maintaining high rendering speeds and reducing the number of required primitives. Our results highlight the potential of 3D Convex Splatting to become the new standard for high-quality scene reconstruction and novel view synthesis. Project page: convexsplatting.github.io.
Physically Interpretable Probabilistic Domain Characterization
Nov 22, 2024Characterizing domains is essential for models analyzing dynamic environments, as it allows them to adapt to evolving conditions or to hand the task over to backup systems when facing conditions outside their operational domain. Existing solutions typically characterize a domain by solving a regression or classification problem, which limits their applicability as they only provide a limited summarized description of the domain. In this paper, we present a novel approach to domain characterization by characterizing domains as probability distributions. Particularly, we develop a method to predict the likelihood of different weather conditions from images captured by vehicle-mounted cameras by estimating distributions of physical parameters using normalizing flows. To validate our proposed approach, we conduct experiments within the context of autonomous vehicles, focusing on predicting the distribution of weather parameters to characterize the operational domain. This domain is characterized by physical parameters (absolute characterization) and arbitrarily predefined domains (relative characterization). Finally, we evaluate whether a system can safely operate in a target domain by comparing it to multiple source domains where safety has already been established. This approach holds significant potential, as accurate weather prediction and effective domain adaptation are crucial for autonomous systems to adjust to dynamic environmental conditions.