 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemember to be Curious: Episodic Context and Persistent Worlds for 3D Exploration
May 21, 2026Exploration is a prerequisite for learning useful behaviors in sparse-reward, long-horizon tasks, particularly within 3D environments. Curiosity-driven reinforcement learning addresses this via intrinsic rewards derived from the mismatch between the agent's predictive model of the world and reality. However, translating this intrinsic motivation to complex, photorealistic environments remains difficult, as agents can become trapped in local loops and receive fresh rewards for revisiting forgotten states. In this work, we demonstrate that this failure stems from a lack of spatial persistence and episodic context. We show that effective curiosity requires a model of the world that is persistent and continuously updated, paired with an agent that maintains an episodic trajectory history to navigate toward novel regions. We achieve this using an online 3D reconstruction as a persistent model of the world, while the agent policy is parameterized as a sequence model over RGB observations to maintain episodic context. This design enables effective exploration during training while allowing the agent to navigate using solely RGB frames at deployment. Trained purely via curiosity on HM3D, our agent outperforms RL-based active mapping baselines and generalizes zero-shot to Gibson and AI-generated worlds. Our end-to-end policy enables efficient adaptation to downstream tasks, such as apple picking and image-goal navigation, outperforming from-scratch baselines. Please see video results at https://recuriosity.github.io/.
Power Foam: Unifying Real-Time Differentiable Ray Tracing and Rasterization
Apr 27, 2026We introduce a differentiable 3D representation that unifies the ray tracing capabilities of foam-based ray tracing with the efficiency of modern rasterization pipelines. While prior foam representations enable constant-time ray traversal through an explicit volumetric partition of space, their potentially unbounded cells hinder efficient tile-based rasterization. We address this limitation by generalizing Voronoi foams to bounded power diagrams with controllable cell extents, enabling spatially bounded primitives without requiring expensive Delaunay triangulations during training. We further introduce an oriented surface formulation that explicitly models interfaces between interior and exterior regions, and decouple geometry from appearance by embedding differentiable texture directly on these surfaces. Together, these contributions yield a representation that preserves state-of-the-art ray tracing efficiency while achieving rasterization performance competitive with current generation 3DGS, providing a practical path toward unified real-time differentiable rendering.
Free-Range Gaussians: Non-Grid-Aligned Generative 3D Gaussian Reconstruction
Apr 06, 2026We present Free-Range Gaussians, a multi-view reconstruction method that predicts non-pixel, non-voxel-aligned 3D Gaussians from as few as four images. This is done through flow matching over Gaussian parameters. Our generative formulation of reconstruction allows the model to be supervised with non-grid-aligned 3D data, and enables it to synthesize plausible content in unobserved regions. Thus, it improves on prior methods that produce highly redundant grid-aligned Gaussians, and suffer from holes or blurry conditional means in unobserved regions. To handle the number of Gaussians needed for high-quality results, we introduce a hierarchical patching scheme to group spatially related Gaussians into joint transformer tokens, halving the sequence length while preserving structure. We further propose a timestep-weighted rendering loss during training, and photometric gradient guidance and classifier-free guidance at inference to improve fidelity. Experiments on Objaverse and Google Scanned Objects show consistent improvements over pixel and voxel-aligned methods while using significantly fewer Gaussians, with large gains when input views leave parts of the object unobserved.
FullCircle: Effortless 3D Reconstruction from Casual 360$^\circ$ Captures
Mar 23, 2026Radiance fields have emerged as powerful tools for 3D scene reconstruction. However, casual capture remains challenging due to the narrow field of view of perspective cameras, which limits viewpoint coverage and feature correspondences necessary for reliable camera calibration and reconstruction. While commercially available 360$^\circ$ cameras offer significantly broader coverage than perspective cameras for the same capture effort, existing 360$^\circ$ reconstruction methods require special capture protocols and pre-processing steps that undermine the promise of radiance fields: effortless workflows to capture and reconstruct 3D scenes. We propose a practical pipeline for reconstructing 3D scenes directly from raw 360$^\circ$ camera captures. We require no special capture protocols or pre-processing, and exhibit robustness to a prevalent source of reconstruction errors: the human operator that is visible in all 360$^\circ$ imagery. To facilitate evaluation, we introduce a multi-tiered dataset of scenes captured as raw dual-fisheye images, establishing a benchmark for robust casual 360$^\circ$ reconstruction. Our method significantly outperforms not only vanilla 3DGS for 360$^\circ$ cameras but also robust perspective baselines when perspective cameras are simulated from the same capture, demonstrating the advantages of 360$^\circ$ capture for casual reconstruction. Additional results are available at: https://theialab.github.io/fullcircle
Grow with the Flow: 4D Reconstruction of Growing Plants with Gaussian Flow Fields
Feb 09, 2026Modeling the time-varying 3D appearance of plants during their growth poses unique challenges: unlike many dynamic scenes, plants generate new geometry over time as they expand, branch, and differentiate. Recent motion modeling techniques are ill-suited to this problem setting. For example, deformation fields cannot introduce new geometry, and 4D Gaussian splatting constrains motion to a linear trajectory in space and time and cannot track the same set of Gaussians over time. Here, we introduce a 3D Gaussian flow field representation that models plant growth as a time-varying derivative over Gaussian parameters -- position, scale, orientation, color, and opacity -- enabling nonlinear and continuous-time growth dynamics. To initialize a sufficient set of Gaussian primitives, we reconstruct the mature plant and learn a process of reverse growth, effectively simulating the plant's developmental history in reverse. Our approach achieves superior image quality and geometric accuracy compared to prior methods on multi-view timelapse datasets of plant growth, providing a new approach for appearance modeling of growing 3D structures.
Untwisting RoPE: Frequency Control for Shared Attention in DiTs
Feb 04, 2026Positional encodings are essential to transformer-based generative models, yet their behavior in multimodal and attention-sharing settings is not fully understood. In this work, we present a principled analysis of Rotary Positional Embeddings (RoPE), showing that RoPE naturally decomposes into frequency components with distinct positional sensitivities. We demonstrate that this frequency structure explains why shared-attention mechanisms, where a target image is generated while attending to tokens from a reference image, can lead to reference copying, in which the model reproduces content from the reference instead of extracting only its stylistic cues. Our analysis reveals that the high-frequency components of RoPE dominate the attention computation, forcing queries to attend mainly to spatially aligned reference tokens and thereby inducing this unintended copying behavior. Building on these insights, we introduce a method for selectively modulating RoPE frequency bands so that attention reflects semantic similarity rather than strict positional alignment. Applied to modern transformer-based diffusion architectures, where all tokens share attention, this modulation restores stable and meaningful shared attention. As a result, it enables effective control over the degree of style transfer versus content copying, yielding a proper style-aligned generation process in which stylistic attributes are transferred without duplicating reference content.
360Anything: Geometry-Free Lifting of Images and Videos to 360°
Jan 22, 2026Lifting perspective images and videos to 360° panoramas enables immersive 3D world generation. Existing approaches often rely on explicit geometric alignment between the perspective and the equirectangular projection (ERP) space. Yet, this requires known camera metadata, obscuring the application to in-the-wild data where such calibration is typically absent or noisy. We propose 360Anything, a geometry-free framework built upon pre-trained diffusion transformers. By treating the perspective input and the panorama target simply as token sequences, 360Anything learns the perspective-to-equirectangular mapping in a purely data-driven way, eliminating the need for camera information. Our approach achieves state-of-the-art performance on both image and video perspective-to-360° generation, outperforming prior works that use ground-truth camera information. We also trace the root cause of the seam artifacts at ERP boundaries to zero-padding in the VAE encoder, and introduce Circular Latent Encoding to facilitate seamless generation. Finally, we show competitive results in zero-shot camera FoV and orientation estimation benchmarks, demonstrating 360Anything's deep geometric understanding and broader utility in computer vision tasks. Additional results are available at https://360anything.github.io/.
Spherical Voronoi: Directional Appearance as a Differentiable Partition of the Sphere
Dec 16, 2025
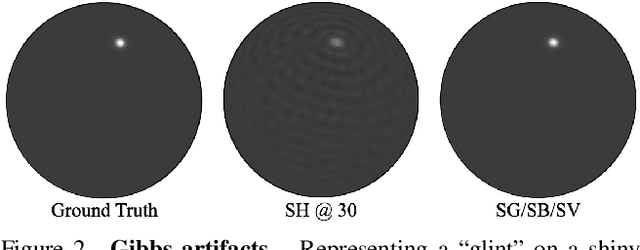
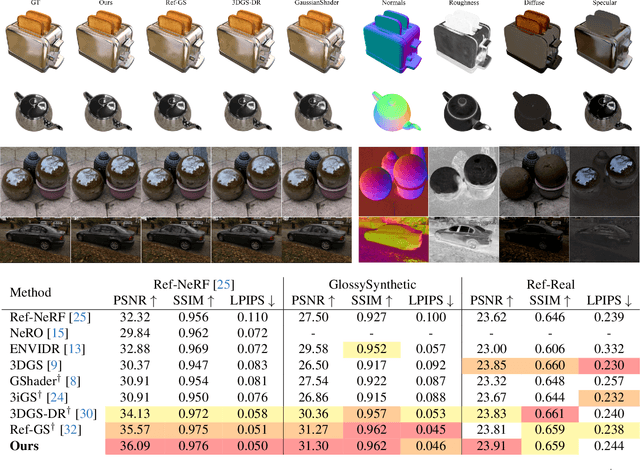
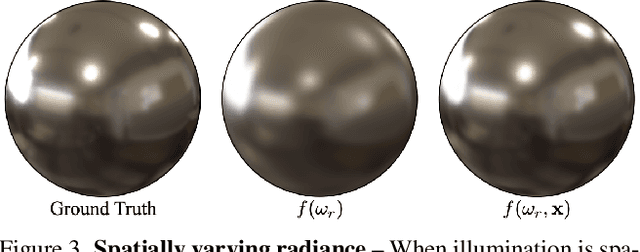
Radiance field methods (e.g. 3D Gaussian Splatting) have emerged as a powerful paradigm for novel view synthesis, yet their appearance modeling often relies on Spherical Harmonics (SH), which impose fundamental limitations. SH struggle with high-frequency signals, exhibit Gibbs ringing artifacts, and fail to capture specular reflections - a key component of realistic rendering. Although alternatives like spherical Gaussians offer improvements, they add significant optimization complexity. We propose Spherical Voronoi (SV) as a unified framework for appearance representation in 3D Gaussian Splatting. SV partitions the directional domain into learnable regions with smooth boundaries, providing an intuitive and stable parameterization for view-dependent effects. For diffuse appearance, SV achieves competitive results while keeping optimization simpler than existing alternatives. For reflections - where SH fail - we leverage SV as learnable reflection probes, taking reflected directions as input following principles from classical graphics. This formulation attains state-of-the-art results on synthetic and real-world datasets, demonstrating that SV offers a principled, efficient, and general solution for appearance modeling in explicit 3D representations.
Nexels: Neurally-Textured Surfels for Real-Time Novel View Synthesis with Sparse Geometries
Dec 15, 2025Though Gaussian splatting has achieved impressive results in novel view synthesis, it requires millions of primitives to model highly textured scenes, even when the geometry of the scene is simple. We propose a representation that goes beyond point-based rendering and decouples geometry and appearance in order to achieve a compact representation. We use surfels for geometry and a combination of a global neural field and per-primitive colours for appearance. The neural field textures a fixed number of primitives for each pixel, ensuring that the added compute is low. Our representation matches the perceptual quality of 3D Gaussian splatting while using $9.7\times$ fewer primitives and $5.5\times$ less memory on outdoor scenes and using $31\times$ fewer primitives and $3.7\times$ less memory on indoor scenes. Our representation also renders twice as fast as existing textured primitives while improving upon their visual quality.
Hierarchical Transformers for Unsupervised 3D Shape Abstraction
Oct 31, 2025We introduce HiT, a novel hierarchical neural field representation for 3D shapes that learns general hierarchies in a coarse-to-fine manner across different shape categories in an unsupervised setting. Our key contribution is a hierarchical transformer (HiT), where each level learns parent-child relationships of the tree hierarchy using a compressed codebook. This codebook enables the network to automatically identify common substructures across potentially diverse shape categories. Unlike previous works that constrain the task to a fixed hierarchical structure (e.g., binary), we impose no such restriction, except for limiting the total number of nodes at each tree level. This flexibility allows our method to infer the hierarchical structure directly from data, over multiple shape categories, and representing more general and complex hierarchies than prior approaches. When trained at scale with a reconstruction loss, our model captures meaningful containment relationships between parent and child nodes. We demonstrate its effectiveness through an unsupervised shape segmentation task over all 55 ShapeNet categories, where our method successfully segments shapes into multiple levels of granularity.