 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge360Anything: Geometry-Free Lifting of Images and Videos to 360°
Jan 22, 2026Lifting perspective images and videos to 360° panoramas enables immersive 3D world generation. Existing approaches often rely on explicit geometric alignment between the perspective and the equirectangular projection (ERP) space. Yet, this requires known camera metadata, obscuring the application to in-the-wild data where such calibration is typically absent or noisy. We propose 360Anything, a geometry-free framework built upon pre-trained diffusion transformers. By treating the perspective input and the panorama target simply as token sequences, 360Anything learns the perspective-to-equirectangular mapping in a purely data-driven way, eliminating the need for camera information. Our approach achieves state-of-the-art performance on both image and video perspective-to-360° generation, outperforming prior works that use ground-truth camera information. We also trace the root cause of the seam artifacts at ERP boundaries to zero-padding in the VAE encoder, and introduce Circular Latent Encoding to facilitate seamless generation. Finally, we show competitive results in zero-shot camera FoV and orientation estimation benchmarks, demonstrating 360Anything's deep geometric understanding and broader utility in computer vision tasks. Additional results are available at https://360anything.github.io/.
Reconstructing Heterogeneous Biomolecules via Hierarchical Gaussian Mixtures and Part Discovery
Jun 06, 2025


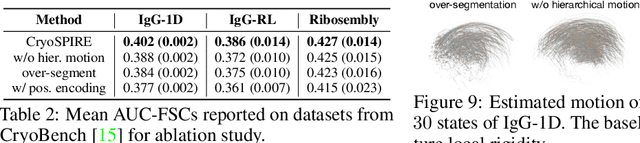
Cryo-EM is a transformational paradigm in molecular biology where computational methods are used to infer 3D molecular structure at atomic resolution from extremely noisy 2D electron microscope images. At the forefront of research is how to model the structure when the imaged particles exhibit non-rigid conformational flexibility and compositional variation where parts are sometimes missing. We introduce a novel 3D reconstruction framework with a hierarchical Gaussian mixture model, inspired in part by Gaussian Splatting for 4D scene reconstruction. In particular, the structure of the model is grounded in an initial process that infers a part-based segmentation of the particle, providing essential inductive bias in order to handle both conformational and compositional variability. The framework, called CryoSPIRE, is shown to reveal biologically meaningful structures on complex experimental datasets, and establishes a new state-of-the-art on CryoBench, a benchmark for cryo-EM heterogeneity methods.
RoMo: Robust Motion Segmentation Improves Structure from Motion
Nov 27, 2024
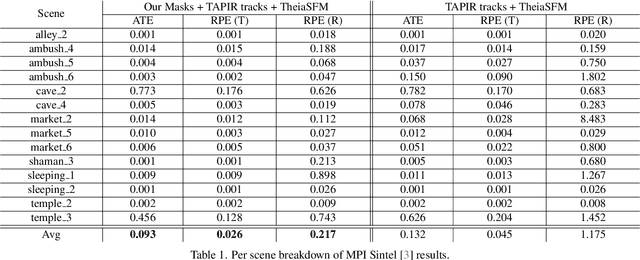


There has been extensive progress in the reconstruction and generation of 4D scenes from monocular casually-captured video. While these tasks rely heavily on known camera poses, the problem of finding such poses using structure-from-motion (SfM) often depends on robustly separating static from dynamic parts of a video. The lack of a robust solution to this problem limits the performance of SfM camera-calibration pipelines. We propose a novel approach to video-based motion segmentation to identify the components of a scene that are moving w.r.t. a fixed world frame. Our simple but effective iterative method, RoMo, combines optical flow and epipolar cues with a pre-trained video segmentation model. It outperforms unsupervised baselines for motion segmentation as well as supervised baselines trained from synthetic data. More importantly, the combination of an off-the-shelf SfM pipeline with our segmentation masks establishes a new state-of-the-art on camera calibration for scenes with dynamic content, outperforming existing methods by a substantial margin.
High-Resolution Frame Interpolation with Patch-based Cascaded Diffusion
Oct 15, 2024Despite the recent progress, existing frame interpolation methods still struggle with processing extremely high resolution input and handling challenging cases such as repetitive textures, thin objects, and large motion. To address these issues, we introduce a patch-based cascaded pixel diffusion model for frame interpolation, HiFI, that excels in these scenarios while achieving competitive performance on standard benchmarks. Cascades, which generate a series of images from low- to high-resolution, can help significantly with large or complex motion that require both global context for a coarse solution and detailed context for high resolution output. However, contrary to prior work on cascaded diffusion models which perform diffusion on increasingly large resolutions, we use a single model that always performs diffusion at the same resolution and upsamples by processing patches of the inputs and the prior solution. We show that this technique drastically reduces memory usage at inference time and also allows us to use a single model at test time, solving both frame interpolation and spatial up-sampling, saving training cost. We show that HiFI helps significantly with high resolution and complex repeated textures that require global context. HiFI demonstrates comparable or beyond state-of-the-art performance on multiple benchmarks (Vimeo, Xiph, X-Test, SEPE-8K). On our newly introduced dataset that focuses on particularly challenging cases, HiFI also significantly outperforms other baselines on these cases. Please visit our project page for video results: https://hifi-diffusion.github.io
Controlling Space and Time with Diffusion Models
Jul 10, 2024We present 4DiM, a cascaded diffusion model for 4D novel view synthesis (NVS), conditioned on one or more images of a general scene, and a set of camera poses and timestamps. To overcome challenges due to limited availability of 4D training data, we advocate joint training on 3D (with camera pose), 4D (pose+time) and video (time but no pose) data and propose a new architecture that enables the same. We further advocate the calibration of SfM posed data using monocular metric depth estimators for metric scale camera control. For model evaluation, we introduce new metrics to enrich and overcome shortcomings of current evaluation schemes, demonstrating state-of-the-art results in both fidelity and pose control compared to existing diffusion models for 3D NVS, while at the same time adding the ability to handle temporal dynamics. 4DiM is also used for improved panorama stitching, pose-conditioned video to video translation, and several other tasks. For an overview see https://4d-diffusion.github.io
SpotlessSplats: Ignoring Distractors in 3D Gaussian Splatting
Jun 28, 2024
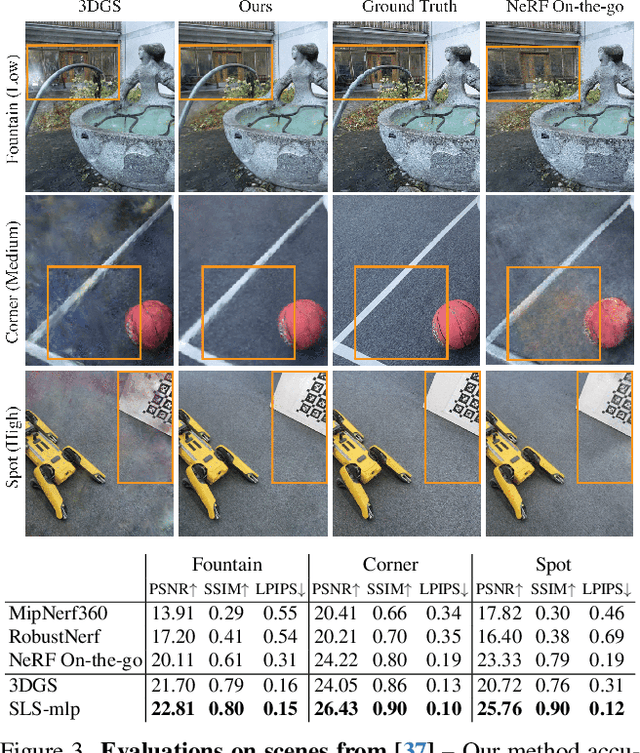

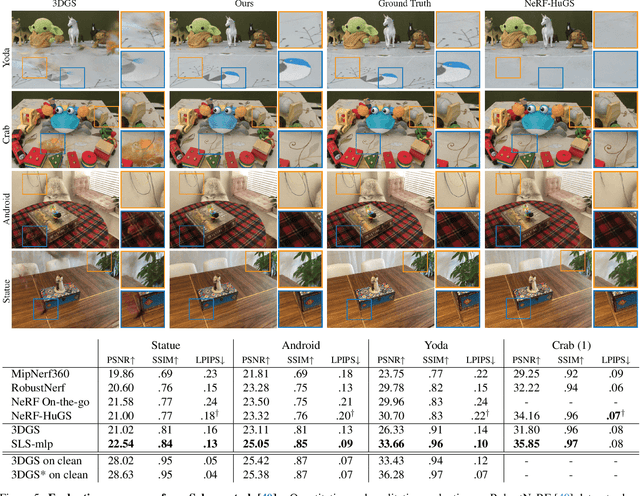
3D Gaussian Splatting (3DGS) is a promising technique for 3D reconstruction, offering efficient training and rendering speeds, making it suitable for real-time applications.However, current methods require highly controlled environments (no moving people or wind-blown elements, and consistent lighting) to meet the inter-view consistency assumption of 3DGS. This makes reconstruction of real-world captures problematic. We present SpotlessSplats, an approach that leverages pre-trained and general-purpose features coupled with robust optimization to effectively ignore transient distractors. Our method achieves state-of-the-art reconstruction quality both visually and quantitatively, on casual captures.
Improving Ab-Initio Cryo-EM Reconstruction with Semi-Amortized Pose Inference
Jun 15, 2024
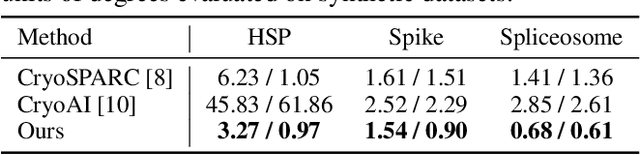


Cryo-Electron Microscopy (cryo-EM) is an increasingly popular experimental technique for estimating the 3D structure of macromolecular complexes such as proteins based on 2D images. These images are notoriously noisy, and the pose of the structure in each image is unknown \textit{a priori}. Ab-initio 3D reconstruction from 2D images entails estimating the pose in addition to the structure. In this work, we propose a new approach to this problem. We first adopt a multi-head architecture as a pose encoder to infer multiple plausible poses per-image in an amortized fashion. This approach mitigates the high uncertainty in pose estimation by encouraging exploration of pose space early in reconstruction. Once uncertainty is reduced, we refine poses in an auto-decoding fashion. In particular, we initialize with the most likely pose and iteratively update it for individual images using stochastic gradient descent (SGD). Through evaluation on synthetic datasets, we demonstrate that our method is able to handle multi-modal pose distributions during the amortized inference stage, while the later, more flexible stage of direct pose optimization yields faster and more accurate convergence of poses compared to baselines. Finally, on experimental data, we show that our approach is faster than state-of-the-art cryoAI and achieves higher-resolution reconstruction.
Greedy Growing Enables High-Resolution Pixel-Based Diffusion Models
May 27, 2024



We address the long-standing problem of how to learn effective pixel-based image diffusion models at scale, introducing a remarkably simple greedy growing method for stable training of large-scale, high-resolution models. without the needs for cascaded super-resolution components. The key insight stems from careful pre-training of core components, namely, those responsible for text-to-image alignment {\it vs.} high-resolution rendering. We first demonstrate the benefits of scaling a {\it Shallow UNet}, with no down(up)-sampling enc(dec)oder. Scaling its deep core layers is shown to improve alignment, object structure, and composition. Building on this core model, we propose a greedy algorithm that grows the architecture into high-resolution end-to-end models, while preserving the integrity of the pre-trained representation, stabilizing training, and reducing the need for large high-resolution datasets. This enables a single stage model capable of generating high-resolution images without the need of a super-resolution cascade. Our key results rely on public datasets and show that we are able to train non-cascaded models up to 8B parameters with no further regularization schemes. Vermeer, our full pipeline model trained with internal datasets to produce 1024x1024 images, without cascades, is preferred by 44.0% vs. 21.4% human evaluators over SDXL.
A Personalized Video-Based Hand Taxonomy: Application for Individuals with Spinal Cord Injury
Mar 26, 2024Hand function is critical for our interactions and quality of life. Spinal cord injuries (SCI) can impair hand function, reducing independence. A comprehensive evaluation of function in home and community settings requires a hand grasp taxonomy for individuals with impaired hand function. Developing such a taxonomy is challenging due to unrepresented grasp types in standard taxonomies, uneven data distribution across injury levels, and limited data. This study aims to automatically identify the dominant distinct hand grasps in egocentric video using semantic clustering. Egocentric video recordings collected in the homes of 19 individual with cervical SCI were used to cluster grasping actions with semantic significance. A deep learning model integrating posture and appearance data was employed to create a personalized hand taxonomy. Quantitative analysis reveals a cluster purity of 67.6% +- 24.2% with with 18.0% +- 21.8% redundancy. Qualitative assessment revealed meaningful clusters in video content. This methodology provides a flexible and effective strategy to analyze hand function in the wild. It offers researchers and clinicians an efficient tool for evaluating hand function, aiding sensitive assessments and tailored intervention plans.
Zero-Shot Metric Depth with a Field-of-View Conditioned Diffusion Model
Dec 20, 2023While methods for monocular depth estimation have made significant strides on standard benchmarks, zero-shot metric depth estimation remains unsolved. Challenges include the joint modeling of indoor and outdoor scenes, which often exhibit significantly different distributions of RGB and depth, and the depth-scale ambiguity due to unknown camera intrinsics. Recent work has proposed specialized multi-head architectures for jointly modeling indoor and outdoor scenes. In contrast, we advocate a generic, task-agnostic diffusion model, with several advancements such as log-scale depth parameterization to enable joint modeling of indoor and outdoor scenes, conditioning on the field-of-view (FOV) to handle scale ambiguity and synthetically augmenting FOV during training to generalize beyond the limited camera intrinsics in training datasets. Furthermore, by employing a more diverse training mixture than is common, and an efficient diffusion parameterization, our method, DMD (Diffusion for Metric Depth) achieves a 25\% reduction in relative error (REL) on zero-shot indoor and 33\% reduction on zero-shot outdoor datasets over the current SOTA using only a small number of denoising steps. For an overview see https://diffusion-vision.github.io/dmd