 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge360Anything: Geometry-Free Lifting of Images and Videos to 360°
Jan 22, 2026Lifting perspective images and videos to 360° panoramas enables immersive 3D world generation. Existing approaches often rely on explicit geometric alignment between the perspective and the equirectangular projection (ERP) space. Yet, this requires known camera metadata, obscuring the application to in-the-wild data where such calibration is typically absent or noisy. We propose 360Anything, a geometry-free framework built upon pre-trained diffusion transformers. By treating the perspective input and the panorama target simply as token sequences, 360Anything learns the perspective-to-equirectangular mapping in a purely data-driven way, eliminating the need for camera information. Our approach achieves state-of-the-art performance on both image and video perspective-to-360° generation, outperforming prior works that use ground-truth camera information. We also trace the root cause of the seam artifacts at ERP boundaries to zero-padding in the VAE encoder, and introduce Circular Latent Encoding to facilitate seamless generation. Finally, we show competitive results in zero-shot camera FoV and orientation estimation benchmarks, demonstrating 360Anything's deep geometric understanding and broader utility in computer vision tasks. Additional results are available at https://360anything.github.io/.
Controlling Space and Time with Diffusion Models
Jul 10, 2024We present 4DiM, a cascaded diffusion model for 4D novel view synthesis (NVS), conditioned on one or more images of a general scene, and a set of camera poses and timestamps. To overcome challenges due to limited availability of 4D training data, we advocate joint training on 3D (with camera pose), 4D (pose+time) and video (time but no pose) data and propose a new architecture that enables the same. We further advocate the calibration of SfM posed data using monocular metric depth estimators for metric scale camera control. For model evaluation, we introduce new metrics to enrich and overcome shortcomings of current evaluation schemes, demonstrating state-of-the-art results in both fidelity and pose control compared to existing diffusion models for 3D NVS, while at the same time adding the ability to handle temporal dynamics. 4DiM is also used for improved panorama stitching, pose-conditioned video to video translation, and several other tasks. For an overview see https://4d-diffusion.github.io
Video Interpolation with Diffusion Models
Apr 01, 2024We present VIDIM, a generative model for video interpolation, which creates short videos given a start and end frame. In order to achieve high fidelity and generate motions unseen in the input data, VIDIM uses cascaded diffusion models to first generate the target video at low resolution, and then generate the high-resolution video conditioned on the low-resolution generated video. We compare VIDIM to previous state-of-the-art methods on video interpolation, and demonstrate how such works fail in most settings where the underlying motion is complex, nonlinear, or ambiguous while VIDIM can easily handle such cases. We additionally demonstrate how classifier-free guidance on the start and end frame and conditioning the super-resolution model on the original high-resolution frames without additional parameters unlocks high-fidelity results. VIDIM is fast to sample from as it jointly denoises all the frames to be generated, requires less than a billion parameters per diffusion model to produce compelling results, and still enjoys scalability and improved quality at larger parameter counts.
ReconFusion: 3D Reconstruction with Diffusion Priors
Dec 05, 20233D reconstruction methods such as Neural Radiance Fields (NeRFs) excel at rendering photorealistic novel views of complex scenes. However, recovering a high-quality NeRF typically requires tens to hundreds of input images, resulting in a time-consuming capture process. We present ReconFusion to reconstruct real-world scenes using only a few photos. Our approach leverages a diffusion prior for novel view synthesis, trained on synthetic and multiview datasets, which regularizes a NeRF-based 3D reconstruction pipeline at novel camera poses beyond those captured by the set of input images. Our method synthesizes realistic geometry and texture in underconstrained regions while preserving the appearance of observed regions. We perform an extensive evaluation across various real-world datasets, including forward-facing and 360-degree scenes, demonstrating significant performance improvements over previous few-view NeRF reconstruction approaches.
Denoising Diffusion Probabilistic Models for Robust Image Super-Resolution in the Wild
Feb 15, 2023
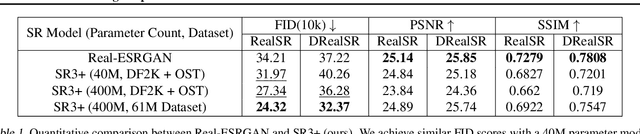
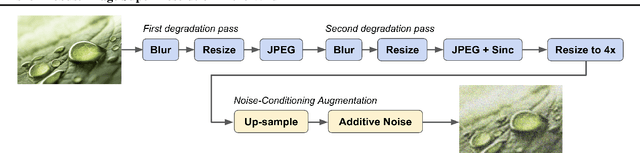
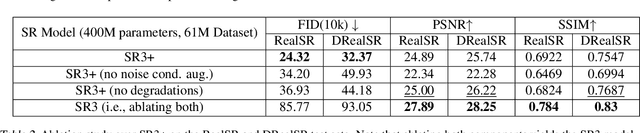
Diffusion models have shown promising results on single-image super-resolution and other image- to-image translation tasks. Despite this success, they have not outperformed state-of-the-art GAN models on the more challenging blind super-resolution task, where the input images are out of distribution, with unknown degradations. This paper introduces SR3+, a diffusion-based model for blind super-resolution, establishing a new state-of-the-art. To this end, we advocate self-supervised training with a combination of composite, parameterized degradations for self-supervised training, and noise-conditioing augmentation during training and testing. With these innovations, a large-scale convolutional architecture, and large-scale datasets, SR3+ greatly outperforms SR3. It outperforms Real-ESRGAN when trained on the same data, with a DRealSR FID score of 36.82 vs. 37.22, which further improves to FID of 32.37 with larger models, and further still with larger training sets.
Novel View Synthesis with Diffusion Models
Oct 06, 2022
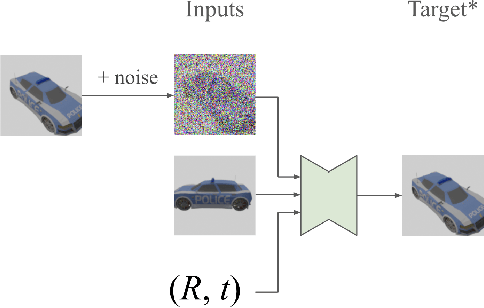
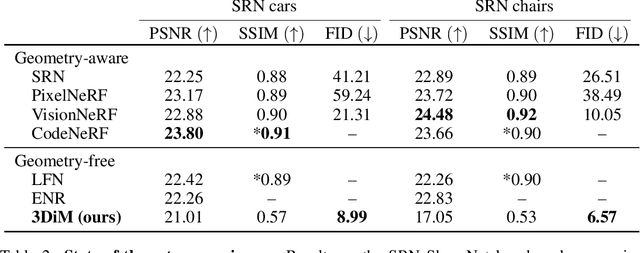
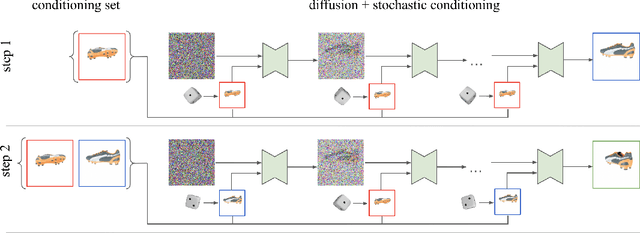
We present 3DiM, a diffusion model for 3D novel view synthesis, which is able to translate a single input view into consistent and sharp completions across many views. The core component of 3DiM is a pose-conditional image-to-image diffusion model, which takes a source view and its pose as inputs, and generates a novel view for a target pose as output. 3DiM can generate multiple views that are 3D consistent using a novel technique called stochastic conditioning. The output views are generated autoregressively, and during the generation of each novel view, one selects a random conditioning view from the set of available views at each denoising step. We demonstrate that stochastic conditioning significantly improves the 3D consistency of a naive sampler for an image-to-image diffusion model, which involves conditioning on a single fixed view. We compare 3DiM to prior work on the SRN ShapeNet dataset, demonstrating that 3DiM's generated completions from a single view achieve much higher fidelity, while being approximately 3D consistent. We also introduce a new evaluation methodology, 3D consistency scoring, to measure the 3D consistency of a generated object by training a neural field on the model's output views. 3DiM is geometry free, does not rely on hyper-networks or test-time optimization for novel view synthesis, and allows a single model to easily scale to a large number of scenes.
Learning Fast Samplers for Diffusion Models by Differentiating Through Sample Quality
Feb 11, 2022



Diffusion models have emerged as an expressive family of generative models rivaling GANs in sample quality and autoregressive models in likelihood scores. Standard diffusion models typically require hundreds of forward passes through the model to generate a single high-fidelity sample. We introduce Differentiable Diffusion Sampler Search (DDSS): a method that optimizes fast samplers for any pre-trained diffusion model by differentiating through sample quality scores. We also present Generalized Gaussian Diffusion Models (GGDM), a family of flexible non-Markovian samplers for diffusion models. We show that optimizing the degrees of freedom of GGDM samplers by maximizing sample quality scores via gradient descent leads to improved sample quality. Our optimization procedure backpropagates through the sampling process using the reparametrization trick and gradient rematerialization. DDSS achieves strong results on unconditional image generation across various datasets (e.g., FID scores on LSUN church 128x128 of 11.6 with only 10 inference steps, and 4.82 with 20 steps, compared to 51.1 and 14.9 with strongest DDPM/DDIM baselines). Our method is compatible with any pre-trained diffusion model without fine-tuning or re-training required.
Learning to Efficiently Sample from Diffusion Probabilistic Models
Jun 07, 2021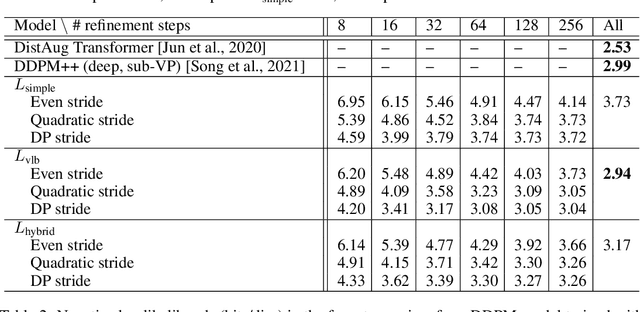
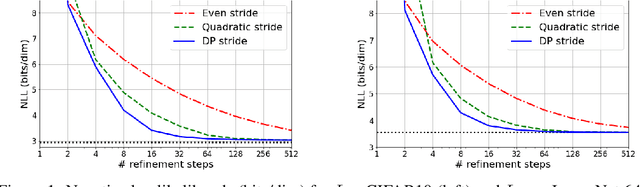

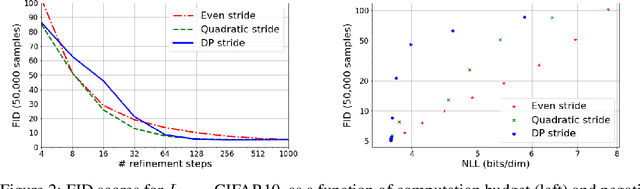
Denoising Diffusion Probabilistic Models (DDPMs) have emerged as a powerful family of generative models that can yield high-fidelity samples and competitive log-likelihoods across a range of domains, including image and speech synthesis. Key advantages of DDPMs include ease of training, in contrast to generative adversarial networks, and speed of generation, in contrast to autoregressive models. However, DDPMs typically require hundreds-to-thousands of steps to generate a high fidelity sample, making them prohibitively expensive for high dimensional problems. Fortunately, DDPMs allow trading generation speed for sample quality through adjusting the number of refinement steps as a post process. Prior work has been successful in improving generation speed through handcrafting the time schedule by trial and error. We instead view the selection of the inference time schedules as an optimization problem, and introduce an exact dynamic programming algorithm that finds the optimal discrete time schedules for any pre-trained DDPM. Our method exploits the fact that ELBO can be decomposed into separate KL terms, and given any computation budget, discovers the time schedule that maximizes the training ELBO exactly. Our method is efficient, has no hyper-parameters of its own, and can be applied to any pre-trained DDPM with no retraining. We discover inference time schedules requiring as few as 32 refinement steps, while sacrificing less than 0.1 bits per dimension compared to the default 4,000 steps used on ImageNet 64x64 [Ho et al., 2020; Nichol and Dhariwal, 2021].
Utilizing Character and Word Embeddings for Text Normalization with Sequence-to-Sequence Models
Sep 05, 2018
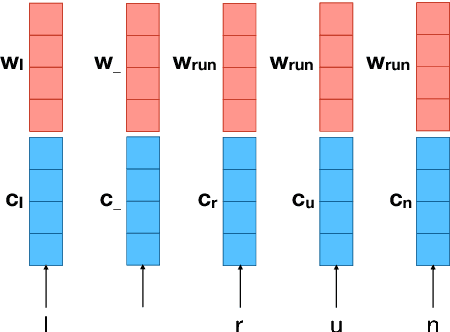
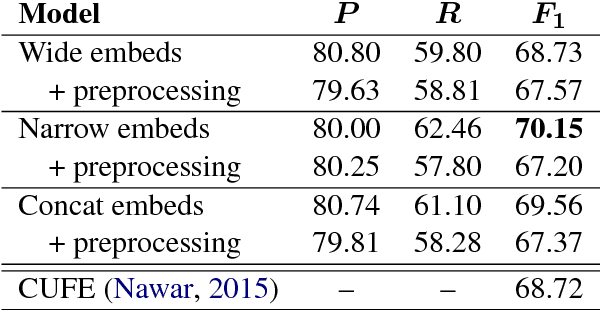
Text normalization is an important enabling technology for several NLP tasks. Recently, neural-network-based approaches have outperformed well-established models in this task. However, in languages other than English, there has been little exploration in this direction. Both the scarcity of annotated data and the complexity of the language increase the difficulty of the problem. To address these challenges, we use a sequence-to-sequence model with character-based attention, which in addition to its self-learned character embeddings, uses word embeddings pre-trained with an approach that also models subword information. This provides the neural model with access to more linguistic information especially suitable for text normalization, without large parallel corpora. We show that providing the model with word-level features bridges the gap for the neural network approach to achieve a state-of-the-art F1 score on a standard Arabic language correction shared task dataset.