 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGR3EN: Generative Relighting for 3D Environments
Jan 22, 2026We present a method for relighting 3D reconstructions of large room-scale environments. Existing solutions for 3D scene relighting often require solving under-determined or ill-conditioned inverse rendering problems, and are as such unable to produce high-quality results on complex real-world scenes. Though recent progress in using generative image and video diffusion models for relighting has been promising, these techniques are either limited to 2D image and video relighting or 3D relighting of individual objects. Our approach enables controllable 3D relighting of room-scale scenes by distilling the outputs of a video-to-video relighting diffusion model into a 3D reconstruction. This side-steps the need to solve a difficult inverse rendering problem, and results in a flexible system that can relight 3D reconstructions of complex real-world scenes. We validate our approach on both synthetic and real-world datasets to show that it can faithfully render novel views of scenes under new lighting conditions.
Revealing the 3D Cosmic Web through Gravitationally Constrained Neural Fields
Apr 21, 2025



Weak gravitational lensing is the slight distortion of galaxy shapes caused primarily by the gravitational effects of dark matter in the universe. In our work, we seek to invert the weak lensing signal from 2D telescope images to reconstruct a 3D map of the universe's dark matter field. While inversion typically yields a 2D projection of the dark matter field, accurate 3D maps of the dark matter distribution are essential for localizing structures of interest and testing theories of our universe. However, 3D inversion poses significant challenges. First, unlike standard 3D reconstruction that relies on multiple viewpoints, in this case, images are only observed from a single viewpoint. This challenge can be partially addressed by observing how galaxy emitters throughout the volume are lensed. However, this leads to the second challenge: the shapes and exact locations of unlensed galaxies are unknown, and can only be estimated with a very large degree of uncertainty. This introduces an overwhelming amount of noise which nearly drowns out the lensing signal completely. Previous approaches tackle this by imposing strong assumptions about the structures in the volume. We instead propose a methodology using a gravitationally-constrained neural field to flexibly model the continuous matter distribution. We take an analysis-by-synthesis approach, optimizing the weights of the neural network through a fully differentiable physical forward model to reproduce the lensing signal present in image measurements. We showcase our method on simulations, including realistic simulated measurements of dark matter distributions that mimic data from upcoming telescope surveys. Our results show that our method can not only outperform previous methods, but importantly is also able to recover potentially surprising dark matter structures.
Generative Multiview Relighting for 3D Reconstruction under Extreme Illumination Variation
Dec 19, 2024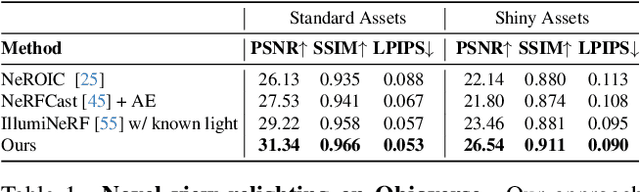
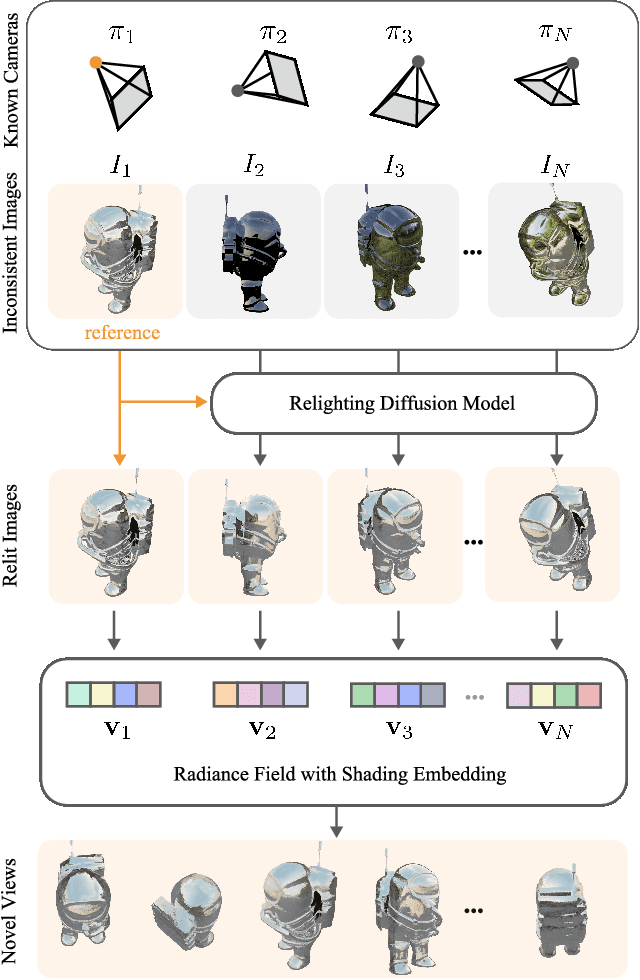
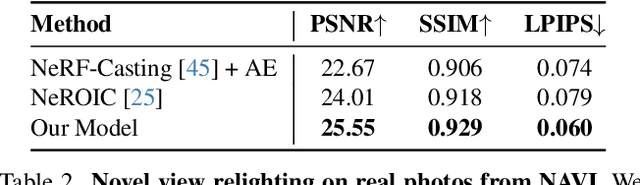

Reconstructing the geometry and appearance of objects from photographs taken in different environments is difficult as the illumination and therefore the object appearance vary across captured images. This is particularly challenging for more specular objects whose appearance strongly depends on the viewing direction. Some prior approaches model appearance variation across images using a per-image embedding vector, while others use physically-based rendering to recover the materials and per-image illumination. Such approaches fail at faithfully recovering view-dependent appearance given significant variation in input illumination and tend to produce mostly diffuse results. We present an approach that reconstructs objects from images taken under different illuminations by first relighting the images under a single reference illumination with a multiview relighting diffusion model and then reconstructing the object's geometry and appearance with a radiance field architecture that is robust to the small remaining inconsistencies among the relit images. We validate our proposed approach on both synthetic and real datasets and demonstrate that it greatly outperforms existing techniques at reconstructing high-fidelity appearance from images taken under extreme illumination variation. Moreover, our approach is particularly effective at recovering view-dependent "shiny" appearance which cannot be reconstructed by prior methods.
SimVS: Simulating World Inconsistencies for Robust View Synthesis
Dec 10, 2024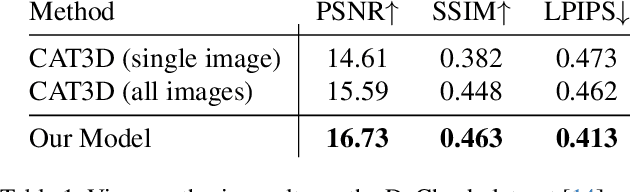



Novel-view synthesis techniques achieve impressive results for static scenes but struggle when faced with the inconsistencies inherent to casual capture settings: varying illumination, scene motion, and other unintended effects that are difficult to model explicitly. We present an approach for leveraging generative video models to simulate the inconsistencies in the world that can occur during capture. We use this process, along with existing multi-view datasets, to create synthetic data for training a multi-view harmonization network that is able to reconcile inconsistent observations into a consistent 3D scene. We demonstrate that our world-simulation strategy significantly outperforms traditional augmentation methods in handling real-world scene variations, thereby enabling highly accurate static 3D reconstructions in the presence of a variety of challenging inconsistencies. Project page: https://alextrevithick.github.io/simvs
Flash Cache: Reducing Bias in Radiance Cache Based Inverse Rendering
Sep 09, 2024State-of-the-art techniques for 3D reconstruction are largely based on volumetric scene representations, which require sampling multiple points to compute the color arriving along a ray. Using these representations for more general inverse rendering -- reconstructing geometry, materials, and lighting from observed images -- is challenging because recursively path-tracing such volumetric representations is expensive. Recent works alleviate this issue through the use of radiance caches: data structures that store the steady-state, infinite-bounce radiance arriving at any point from any direction. However, these solutions rely on approximations that introduce bias into the renderings and, more importantly, into the gradients used for optimization. We present a method that avoids these approximations while remaining computationally efficient. In particular, we leverage two techniques to reduce variance for unbiased estimators of the rendering equation: (1) an occlusion-aware importance sampler for incoming illumination and (2) a fast cache architecture that can be used as a control variate for the radiance from a high-quality, but more expensive, volumetric cache. We show that by removing these biases our approach improves the generality of radiance cache based inverse rendering, as well as increasing quality in the presence of challenging light transport effects such as specular reflections.
IllumiNeRF: 3D Relighting without Inverse Rendering
Jun 10, 2024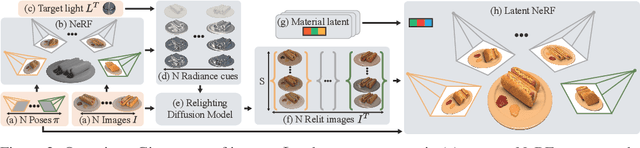



Existing methods for relightable view synthesis -- using a set of images of an object under unknown lighting to recover a 3D representation that can be rendered from novel viewpoints under a target illumination -- are based on inverse rendering, and attempt to disentangle the object geometry, materials, and lighting that explain the input images. Furthermore, this typically involves optimization through differentiable Monte Carlo rendering, which is brittle and computationally-expensive. In this work, we propose a simpler approach: we first relight each input image using an image diffusion model conditioned on lighting and then reconstruct a Neural Radiance Field (NeRF) with these relit images, from which we render novel views under the target lighting. We demonstrate that this strategy is surprisingly competitive and achieves state-of-the-art results on multiple relighting benchmarks. Please see our project page at https://illuminerf.github.io/.
NeRF-Casting: Improved View-Dependent Appearance with Consistent Reflections
May 23, 2024

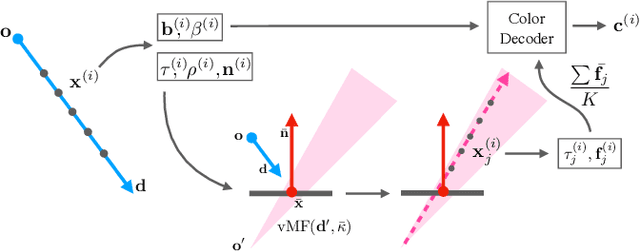

Neural Radiance Fields (NeRFs) typically struggle to reconstruct and render highly specular objects, whose appearance varies quickly with changes in viewpoint. Recent works have improved NeRF's ability to render detailed specular appearance of distant environment illumination, but are unable to synthesize consistent reflections of closer content. Moreover, these techniques rely on large computationally-expensive neural networks to model outgoing radiance, which severely limits optimization and rendering speed. We address these issues with an approach based on ray tracing: instead of querying an expensive neural network for the outgoing view-dependent radiance at points along each camera ray, our model casts reflection rays from these points and traces them through the NeRF representation to render feature vectors which are decoded into color using a small inexpensive network. We demonstrate that our model outperforms prior methods for view synthesis of scenes containing shiny objects, and that it is the only existing NeRF method that can synthesize photorealistic specular appearance and reflections in real-world scenes, while requiring comparable optimization time to current state-of-the-art view synthesis models.
Binary Opacity Grids: Capturing Fine Geometric Detail for Mesh-Based View Synthesis
Feb 19, 2024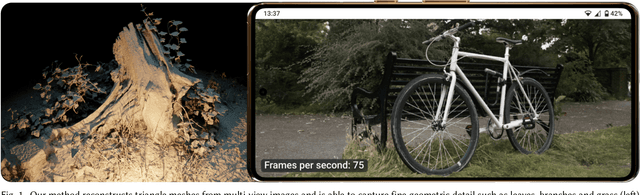



While surface-based view synthesis algorithms are appealing due to their low computational requirements, they often struggle to reproduce thin structures. In contrast, more expensive methods that model the scene's geometry as a volumetric density field (e.g. NeRF) excel at reconstructing fine geometric detail. However, density fields often represent geometry in a "fuzzy" manner, which hinders exact localization of the surface. In this work, we modify density fields to encourage them to converge towards surfaces, without compromising their ability to reconstruct thin structures. First, we employ a discrete opacity grid representation instead of a continuous density field, which allows opacity values to discontinuously transition from zero to one at the surface. Second, we anti-alias by casting multiple rays per pixel, which allows occlusion boundaries and subpixel structures to be modelled without using semi-transparent voxels. Third, we minimize the binary entropy of the opacity values, which facilitates the extraction of surface geometry by encouraging opacity values to binarize towards the end of training. Lastly, we develop a fusion-based meshing strategy followed by mesh simplification and appearance model fitting. The compact meshes produced by our model can be rendered in real-time on mobile devices and achieve significantly higher view synthesis quality compared to existing mesh-based approaches.
Nuvo: Neural UV Mapping for Unruly 3D Representations
Dec 11, 2023Existing UV mapping algorithms are designed to operate on well-behaved meshes, instead of the geometry representations produced by state-of-the-art 3D reconstruction and generation techniques. As such, applying these methods to the volume densities recovered by neural radiance fields and related techniques (or meshes triangulated from such fields) results in texture atlases that are too fragmented to be useful for tasks such as view synthesis or appearance editing. We present a UV mapping method designed to operate on geometry produced by 3D reconstruction and generation techniques. Instead of computing a mapping defined on a mesh's vertices, our method Nuvo uses a neural field to represent a continuous UV mapping, and optimizes it to be a valid and well-behaved mapping for just the set of visible points, i.e. only points that affect the scene's appearance. We show that our model is robust to the challenges posed by ill-behaved geometry, and that it produces editable UV mappings that can represent detailed appearance.
ReconFusion: 3D Reconstruction with Diffusion Priors
Dec 05, 20233D reconstruction methods such as Neural Radiance Fields (NeRFs) excel at rendering photorealistic novel views of complex scenes. However, recovering a high-quality NeRF typically requires tens to hundreds of input images, resulting in a time-consuming capture process. We present ReconFusion to reconstruct real-world scenes using only a few photos. Our approach leverages a diffusion prior for novel view synthesis, trained on synthetic and multiview datasets, which regularizes a NeRF-based 3D reconstruction pipeline at novel camera poses beyond those captured by the set of input images. Our method synthesizes realistic geometry and texture in underconstrained regions while preserving the appearance of observed regions. We perform an extensive evaluation across various real-world datasets, including forward-facing and 360-degree scenes, demonstrating significant performance improvements over previous few-view NeRF reconstruction approaches.