 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePYVALE: A Fast, Scalable, Open-Source 2D Digital Image Correlation (DIC) Engine Capable of Handling Gigapixel Images
Jan 19, 2026Pyvale is an open-source software package that aims to become an all-in-one tool for sensor simulation, sensor uncertainty quantification, sensor placement optimization, and calibration/validation. Central to this is support for image-based sensors, with a dedicated Digital Image Correlation (DIC) module designed for both standalone use and integration within broader experimental design workflows. The design philosophy behind the DIC engine in Pyvale prioritizes a user-friendly Python interface with performant compiled code under the hood. This paper covers Pyvale's 2D DIC engine design, implementation, metrological performance compared to other DIC codes, and the unique ability to handle gigapixel size scanning electron microscope (SEM) images. Finally, we compare runtimes between Pyvale and other open-source DIC codes and show strong computational performance across a range of image resolutions and thread counts.
Masks make discriminative models great again!
Jul 01, 2025We present Image2GS, a novel approach that addresses the challenging problem of reconstructing photorealistic 3D scenes from a single image by focusing specifically on the image-to-3D lifting component of the reconstruction process. By decoupling the lifting problem (converting an image to a 3D model representing what is visible) from the completion problem (hallucinating content not present in the input), we create a more deterministic task suitable for discriminative models. Our method employs visibility masks derived from optimized 3D Gaussian splats to exclude areas not visible from the source view during training. This masked training strategy significantly improves reconstruction quality in visible regions compared to strong baselines. Notably, despite being trained only on masked regions, Image2GS remains competitive with state-of-the-art discriminative models trained on full target images when evaluated on complete scenes. Our findings highlight the fundamental struggle discriminative models face when fitting unseen regions and demonstrate the advantages of addressing image-to-3D lifting as a distinct problem with specialized techniques.
SimVS: Simulating World Inconsistencies for Robust View Synthesis
Dec 10, 2024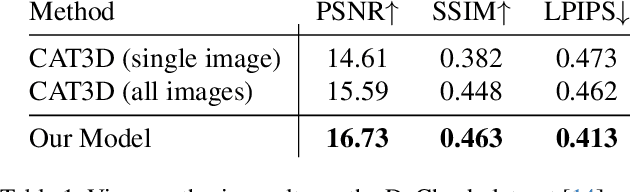



Novel-view synthesis techniques achieve impressive results for static scenes but struggle when faced with the inconsistencies inherent to casual capture settings: varying illumination, scene motion, and other unintended effects that are difficult to model explicitly. We present an approach for leveraging generative video models to simulate the inconsistencies in the world that can occur during capture. We use this process, along with existing multi-view datasets, to create synthetic data for training a multi-view harmonization network that is able to reconcile inconsistent observations into a consistent 3D scene. We demonstrate that our world-simulation strategy significantly outperforms traditional augmentation methods in handling real-world scene variations, thereby enabling highly accurate static 3D reconstructions in the presence of a variety of challenging inconsistencies. Project page: https://alextrevithick.github.io/simvs
CAT4D: Create Anything in 4D with Multi-View Video Diffusion Models
Nov 27, 2024



We present CAT4D, a method for creating 4D (dynamic 3D) scenes from monocular video. CAT4D leverages a multi-view video diffusion model trained on a diverse combination of datasets to enable novel view synthesis at any specified camera poses and timestamps. Combined with a novel sampling approach, this model can transform a single monocular video into a multi-view video, enabling robust 4D reconstruction via optimization of a deformable 3D Gaussian representation. We demonstrate competitive performance on novel view synthesis and dynamic scene reconstruction benchmarks, and highlight the creative capabilities for 4D scene generation from real or generated videos. See our project page for results and interactive demos: \url{cat-4d.github.io}.
EM Distillation for One-step Diffusion Models
May 27, 2024



While diffusion models can learn complex distributions, sampling requires a computationally expensive iterative process. Existing distillation methods enable efficient sampling, but have notable limitations, such as performance degradation with very few sampling steps, reliance on training data access, or mode-seeking optimization that may fail to capture the full distribution. We propose EM Distillation (EMD), a maximum likelihood-based approach that distills a diffusion model to a one-step generator model with minimal loss of perceptual quality. Our approach is derived through the lens of Expectation-Maximization (EM), where the generator parameters are updated using samples from the joint distribution of the diffusion teacher prior and inferred generator latents. We develop a reparametrized sampling scheme and a noise cancellation technique that together stabilizes the distillation process. We further reveal an interesting connection of our method with existing methods that minimize mode-seeking KL. EMD outperforms existing one-step generative methods in terms of FID scores on ImageNet-64 and ImageNet-128, and compares favorably with prior work on distilling text-to-image diffusion models.
CAT3D: Create Anything in 3D with Multi-View Diffusion Models
May 16, 2024



Advances in 3D reconstruction have enabled high-quality 3D capture, but require a user to collect hundreds to thousands of images to create a 3D scene. We present CAT3D, a method for creating anything in 3D by simulating this real-world capture process with a multi-view diffusion model. Given any number of input images and a set of target novel viewpoints, our model generates highly consistent novel views of a scene. These generated views can be used as input to robust 3D reconstruction techniques to produce 3D representations that can be rendered from any viewpoint in real-time. CAT3D can create entire 3D scenes in as little as one minute, and outperforms existing methods for single image and few-view 3D scene creation. See our project page for results and interactive demos at https://cat3d.github.io .
Video Interpolation with Diffusion Models
Apr 01, 2024We present VIDIM, a generative model for video interpolation, which creates short videos given a start and end frame. In order to achieve high fidelity and generate motions unseen in the input data, VIDIM uses cascaded diffusion models to first generate the target video at low resolution, and then generate the high-resolution video conditioned on the low-resolution generated video. We compare VIDIM to previous state-of-the-art methods on video interpolation, and demonstrate how such works fail in most settings where the underlying motion is complex, nonlinear, or ambiguous while VIDIM can easily handle such cases. We additionally demonstrate how classifier-free guidance on the start and end frame and conditioning the super-resolution model on the original high-resolution frames without additional parameters unlocks high-fidelity results. VIDIM is fast to sample from as it jointly denoises all the frames to be generated, requires less than a billion parameters per diffusion model to produce compelling results, and still enjoys scalability and improved quality at larger parameter counts.
Disentangled 3D Scene Generation with Layout Learning
Feb 26, 2024We introduce a method to generate 3D scenes that are disentangled into their component objects. This disentanglement is unsupervised, relying only on the knowledge of a large pretrained text-to-image model. Our key insight is that objects can be discovered by finding parts of a 3D scene that, when rearranged spatially, still produce valid configurations of the same scene. Concretely, our method jointly optimizes multiple NeRFs from scratch - each representing its own object - along with a set of layouts that composite these objects into scenes. We then encourage these composited scenes to be in-distribution according to the image generator. We show that despite its simplicity, our approach successfully generates 3D scenes decomposed into individual objects, enabling new capabilities in text-to-3D content creation. For results and an interactive demo, see our project page at https://dave.ml/layoutlearning/
Inpaint3D: 3D Scene Content Generation using 2D Inpainting Diffusion
Dec 06, 2023



This paper presents a novel approach to inpainting 3D regions of a scene, given masked multi-view images, by distilling a 2D diffusion model into a learned 3D scene representation (e.g. a NeRF). Unlike 3D generative methods that explicitly condition the diffusion model on camera pose or multi-view information, our diffusion model is conditioned only on a single masked 2D image. Nevertheless, we show that this 2D diffusion model can still serve as a generative prior in a 3D multi-view reconstruction problem where we optimize a NeRF using a combination of score distillation sampling and NeRF reconstruction losses. Predicted depth is used as additional supervision to encourage accurate geometry. We compare our approach to 3D inpainting methods that focus on object removal. Because our method can generate content to fill any 3D masked region, we additionally demonstrate 3D object completion, 3D object replacement, and 3D scene completion.
ReconFusion: 3D Reconstruction with Diffusion Priors
Dec 05, 20233D reconstruction methods such as Neural Radiance Fields (NeRFs) excel at rendering photorealistic novel views of complex scenes. However, recovering a high-quality NeRF typically requires tens to hundreds of input images, resulting in a time-consuming capture process. We present ReconFusion to reconstruct real-world scenes using only a few photos. Our approach leverages a diffusion prior for novel view synthesis, trained on synthetic and multiview datasets, which regularizes a NeRF-based 3D reconstruction pipeline at novel camera poses beyond those captured by the set of input images. Our method synthesizes realistic geometry and texture in underconstrained regions while preserving the appearance of observed regions. We perform an extensive evaluation across various real-world datasets, including forward-facing and 360-degree scenes, demonstrating significant performance improvements over previous few-view NeRF reconstruction approaches.