 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Actor Critic
Dec 25, 2025Conventional Reinforcement Learning (RL) algorithms, typically focused on estimating or maximizing expected returns, face challenges when refining offline pretrained models with online experiences. This paper introduces Generative Actor Critic (GAC), a novel framework that decouples sequential decision-making by reframing \textit{policy evaluation} as learning a generative model of the joint distribution over trajectories and returns, $p(τ, y)$, and \textit{policy improvement} as performing versatile inference on this learned model. To operationalize GAC, we introduce a specific instantiation based on a latent variable model that features continuous latent plan vectors. We develop novel inference strategies for both \textit{exploitation}, by optimizing latent plans to maximize expected returns, and \textit{exploration}, by sampling latent plans conditioned on dynamically adjusted target returns. Experiments on Gym-MuJoCo and Maze2D benchmarks demonstrate GAC's strong offline performance and significantly enhanced offline-to-online improvement compared to state-of-the-art methods, even in absence of step-wise rewards.
B*: Efficient and Optimal Base Placement for Fixed-Base Manipulators
Apr 17, 2025B* is a novel optimization framework that addresses a critical challenge in fixed-base manipulator robotics: optimal base placement. Current methods rely on pre-computed kinematics databases generated through sampling to search for solutions. However, they face an inherent trade-off between solution optimality and computational efficiency when determining sampling resolution. To address these limitations, B* unifies multiple objectives without database dependence. The framework employs a two-layer hierarchical approach. The outer layer systematically manages terminal constraints through progressive tightening, particularly for base mobility, enabling feasible initialization and broad solution exploration. The inner layer addresses non-convexities in each outer-layer subproblem through sequential local linearization, converting the original problem into tractable sequential linear programming (SLP). Testing across multiple robot platforms demonstrates B*'s effectiveness. The framework achieves solution optimality five orders of magnitude better than sampling-based approaches while maintaining perfect success rates and reduced computational overhead. Operating directly in configuration space, B* enables simultaneous path planning with customizable optimization criteria. B* serves as a crucial initialization tool that bridges the gap between theoretical motion planning and practical deployment, where feasible trajectory existence is fundamental.
Scalable Language Models with Posterior Inference of Latent Thought Vectors
Feb 03, 2025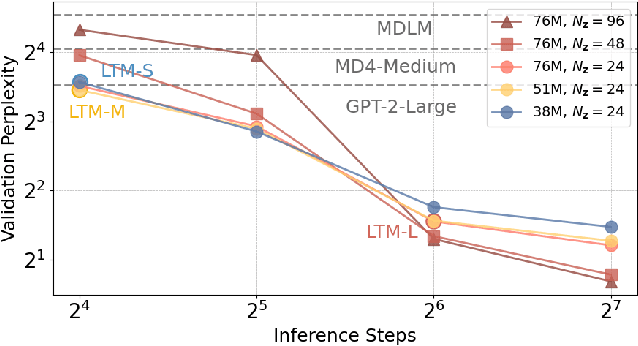
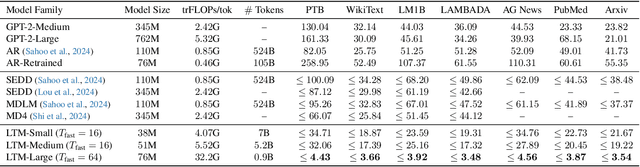
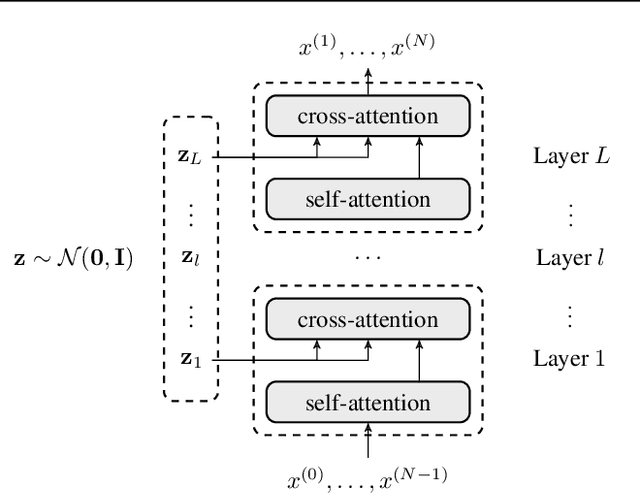
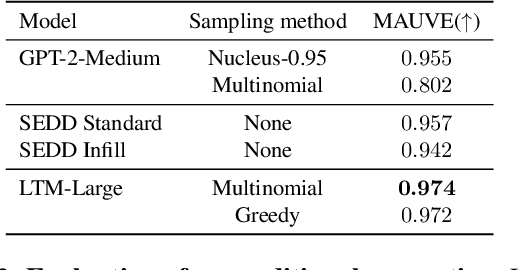
We propose a novel family of language models, Latent-Thought Language Models (LTMs), which incorporate explicit latent thought vectors that follow an explicit prior model in latent space. These latent thought vectors guide the autoregressive generation of ground tokens through a Transformer decoder. Training employs a dual-rate optimization process within the classical variational Bayes framework: fast learning of local variational parameters for the posterior distribution of latent vectors, and slow learning of global decoder parameters. Empirical studies reveal that LTMs possess additional scaling dimensions beyond traditional LLMs, yielding a structured design space. Higher sample efficiency can be achieved by increasing training compute per token, with further gains possible by trading model size for more inference steps. Designed based on these scaling properties, LTMs demonstrate superior sample and parameter efficiency compared to conventional autoregressive models and discrete diffusion models. They significantly outperform these counterparts in validation perplexity and zero-shot language modeling. Additionally, LTMs exhibit emergent few-shot in-context reasoning capabilities that scale with model and latent size, and achieve competitive performance in conditional and unconditional text generation.
EM Distillation for One-step Diffusion Models
May 27, 2024



While diffusion models can learn complex distributions, sampling requires a computationally expensive iterative process. Existing distillation methods enable efficient sampling, but have notable limitations, such as performance degradation with very few sampling steps, reliance on training data access, or mode-seeking optimization that may fail to capture the full distribution. We propose EM Distillation (EMD), a maximum likelihood-based approach that distills a diffusion model to a one-step generator model with minimal loss of perceptual quality. Our approach is derived through the lens of Expectation-Maximization (EM), where the generator parameters are updated using samples from the joint distribution of the diffusion teacher prior and inferred generator latents. We develop a reparametrized sampling scheme and a noise cancellation technique that together stabilizes the distillation process. We further reveal an interesting connection of our method with existing methods that minimize mode-seeking KL. EMD outperforms existing one-step generative methods in terms of FID scores on ImageNet-64 and ImageNet-128, and compares favorably with prior work on distilling text-to-image diffusion models.
Latent Plan Transformer: Planning as Latent Variable Inference
Feb 07, 2024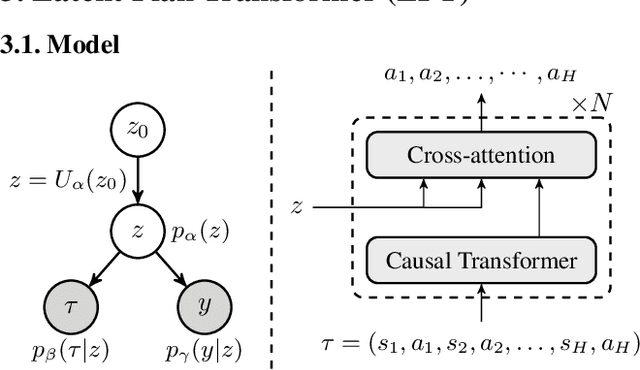
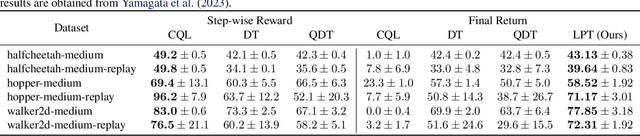

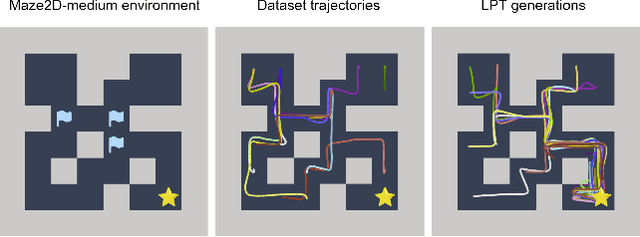
In tasks aiming for long-term returns, planning becomes necessary. We study generative modeling for planning with datasets repurposed from offline reinforcement learning. Specifically, we identify temporal consistency in the absence of step-wise rewards as one key technical challenge. We introduce the Latent Plan Transformer (LPT), a novel model that leverages a latent space to connect a Transformer-based trajectory generator and the final return. LPT can be learned with maximum likelihood estimation on trajectory-return pairs. In learning, posterior sampling of the latent variable naturally gathers sub-trajectories to form a consistent abstraction despite the finite context. During test time, the latent variable is inferred from an expected return before policy execution, realizing the idea of planning as inference. It then guides the autoregressive policy throughout the episode, functioning as a plan. Our experiments demonstrate that LPT can discover improved decisions from suboptimal trajectories. It achieves competitive performance across several benchmarks, including Gym-Mujoco, Maze2D, and Connect Four, exhibiting capabilities of nuanced credit assignments, trajectory stitching, and adaptation to environmental contingencies. These results validate that latent variable inference can be a strong alternative to step-wise reward prompting.
ASSIST: Interactive Scene Nodes for Scalable and Realistic Indoor Simulation
Nov 10, 2023



We present ASSIST, an object-wise neural radiance field as a panoptic representation for compositional and realistic simulation. Central to our approach is a novel scene node data structure that stores the information of each object in a unified fashion, allowing online interaction in both intra- and cross-scene settings. By incorporating a differentiable neural network along with the associated bounding box and semantic features, the proposed structure guarantees user-friendly interaction on independent objects to scale up novel view simulation. Objects in the scene can be queried, added, duplicated, deleted, transformed, or swapped simply through mouse/keyboard controls or language instructions. Experiments demonstrate the efficacy of the proposed method, where scaled realistic simulation can be achieved through interactive editing and compositional rendering, with color images, depth images, and panoptic segmentation masks generated in a 3D consistent manner.
Learning Energy-Based Prior Model with Diffusion-Amortized MCMC
Oct 05, 2023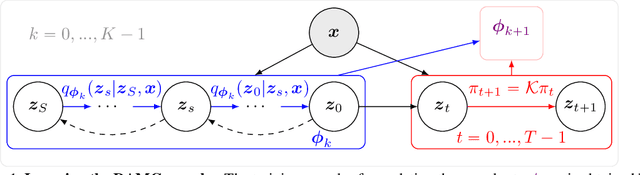
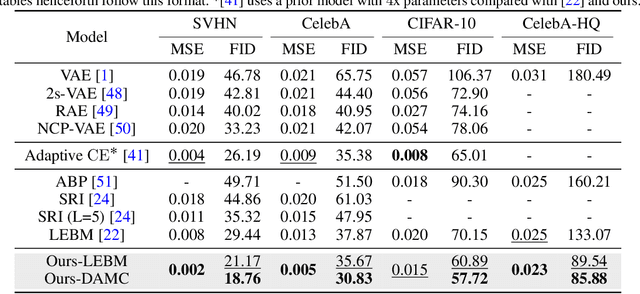

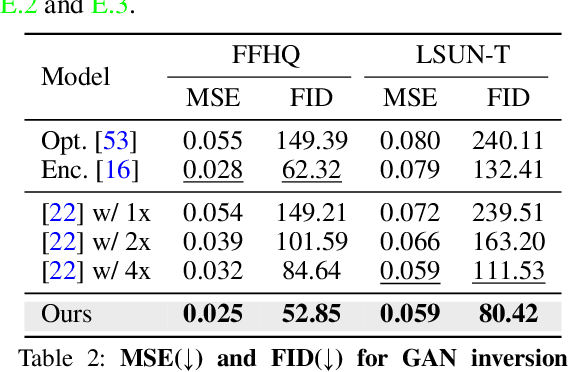
Latent space Energy-Based Models (EBMs), also known as energy-based priors, have drawn growing interests in the field of generative modeling due to its flexibility in the formulation and strong modeling power of the latent space. However, the common practice of learning latent space EBMs with non-convergent short-run MCMC for prior and posterior sampling is hindering the model from further progress; the degenerate MCMC sampling quality in practice often leads to degraded generation quality and instability in training, especially with highly multi-modal and/or high-dimensional target distributions. To remedy this sampling issue, in this paper we introduce a simple but effective diffusion-based amortization method for long-run MCMC sampling and develop a novel learning algorithm for the latent space EBM based on it. We provide theoretical evidence that the learned amortization of MCMC is a valid long-run MCMC sampler. Experiments on several image modeling benchmark datasets demonstrate the superior performance of our method compared with strong counterparts
Learning non-Markovian Decision-Making from State-only Sequences
Jul 01, 2023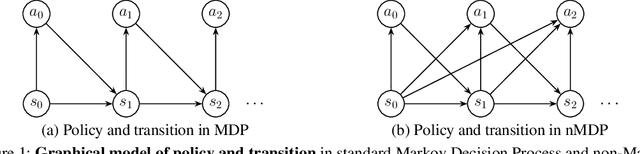

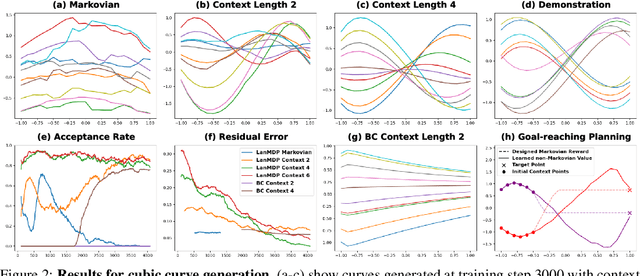

Conventional imitation learning assumes access to the actions of demonstrators, but these motor signals are often non-observable in naturalistic settings. Additionally, sequential decision-making behaviors in these settings can deviate from the assumptions of a standard Markov Decision Process (MDP). To address these challenges, we explore deep generative modeling of state-only sequences with non-Markov Decision Process (nMDP), where the policy is an energy-based prior in the latent space of the state transition generator. We develop maximum likelihood estimation to achieve model-based imitation, which involves short-run MCMC sampling from the prior and importance sampling for the posterior. The learned model enables \textit{decision-making as inference}: model-free policy execution is equivalent to prior sampling, model-based planning is posterior sampling initialized from the policy. We demonstrate the efficacy of the proposed method in a prototypical path planning task with non-Markovian constraints and show that the learned model exhibits strong performances in challenging domains from the MuJoCo suite.
Latent Diffusion Energy-Based Model for Interpretable Text Modeling
Jun 14, 2022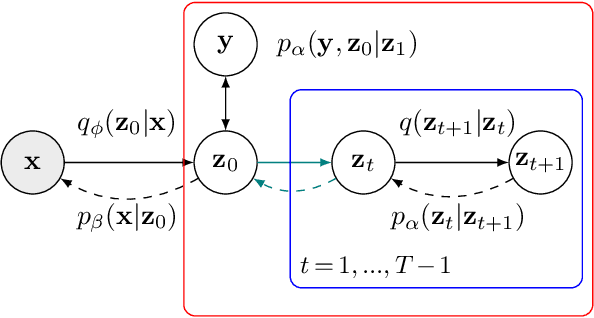
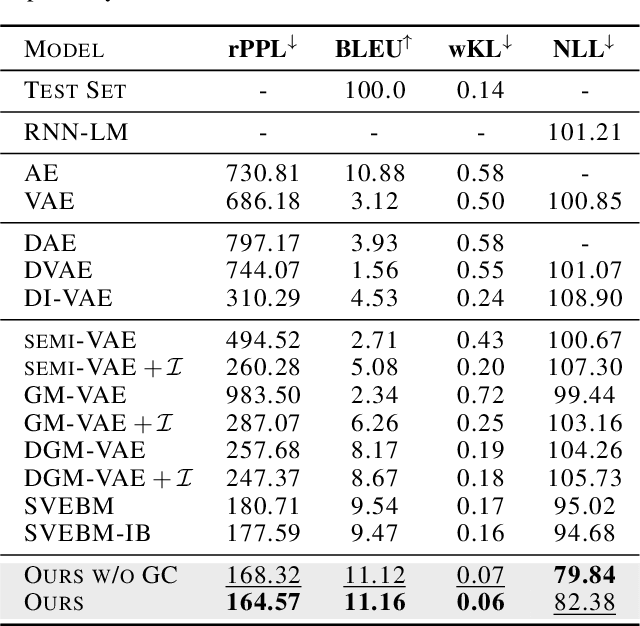
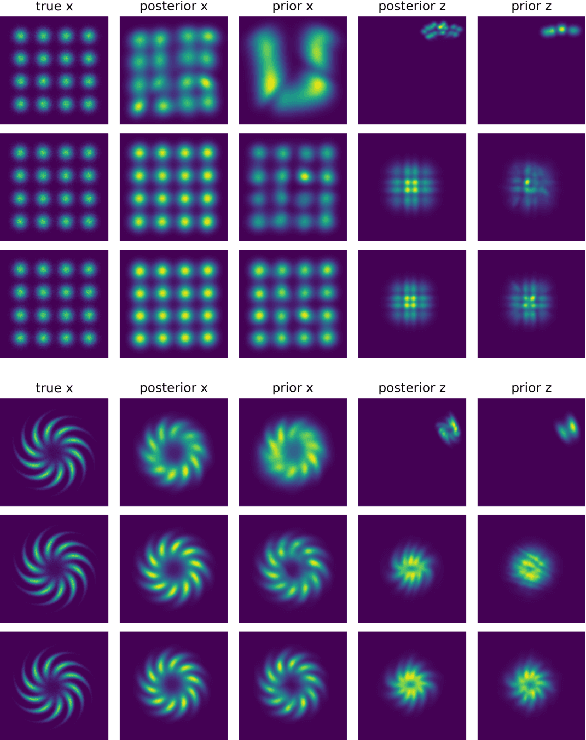

Latent space Energy-Based Models (EBMs), also known as energy-based priors, have drawn growing interests in generative modeling. Fueled by its flexibility in the formulation and strong modeling power of the latent space, recent works built upon it have made interesting attempts aiming at the interpretability of text modeling. However, latent space EBMs also inherit some flaws from EBMs in data space; the degenerate MCMC sampling quality in practice can lead to poor generation quality and instability in training, especially on data with complex latent structures. Inspired by the recent efforts that leverage diffusion recovery likelihood learning as a cure for the sampling issue, we introduce a novel symbiosis between the diffusion models and latent space EBMs in a variational learning framework, coined as the latent diffusion energy-based model. We develop a geometric clustering-based regularization jointly with the information bottleneck to further improve the quality of the learned latent space. Experiments on several challenging tasks demonstrate the superior performance of our model on interpretable text modeling over strong counterparts.
Emergent Graphical Conventions in a Visual Communication Game
Dec 03, 2021
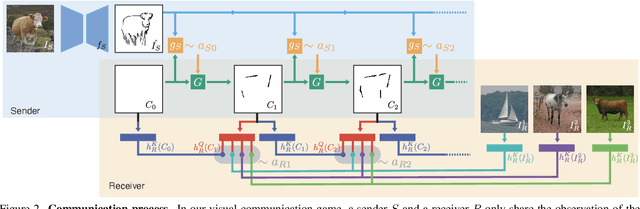
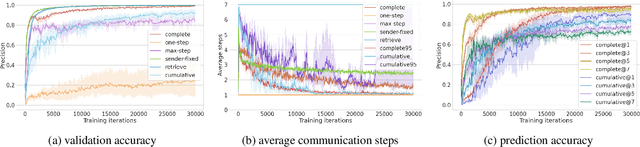
Humans communicate with graphical sketches apart from symbolic languages. While recent studies of emergent communication primarily focus on symbolic languages, their settings overlook the graphical sketches existing in human communication; they do not account for the evolution process through which symbolic sign systems emerge in the trade-off between iconicity and symbolicity. In this work, we take the very first step to model and simulate such an evolution process via two neural agents playing a visual communication game; the sender communicates with the receiver by sketching on a canvas. We devise a novel reinforcement learning method such that agents are evolved jointly towards successful communication and abstract graphical conventions. To inspect the emerged conventions, we carefully define three key properties -- iconicity, symbolicity, and semanticity -- and design evaluation methods accordingly. Our experimental results under different controls are consistent with the observation in studies of human graphical conventions. Of note, we find that evolved sketches can preserve the continuum of semantics under proper environmental pressures. More interestingly, co-evolved agents can switch between conventionalized and iconic communication based on their familiarity with referents. We hope the present research can pave the path for studying emergent communication with the unexplored modality of sketches.