 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobo-GS: A Physics Consistent Spatial-Temporal Model for Robotic Arm with Hybrid Representation
Aug 27, 2024Real2Sim2Real plays a critical role in robotic arm control and reinforcement learning, yet bridging this gap remains a significant challenge due to the complex physical properties of robots and the objects they manipulate. Existing methods lack a comprehensive solution to accurately reconstruct real-world objects with spatial representations and their associated physics attributes. We propose a Real2Sim pipeline with a hybrid representation model that integrates mesh geometry, 3D Gaussian kernels, and physics attributes to enhance the digital asset representation of robotic arms. This hybrid representation is implemented through a Gaussian-Mesh-Pixel binding technique, which establishes an isomorphic mapping between mesh vertices and Gaussian models. This enables a fully differentiable rendering pipeline that can be optimized through numerical solvers, achieves high-fidelity rendering via Gaussian Splatting, and facilitates physically plausible simulation of the robotic arm's interaction with its environment using mesh-based methods. The code,full presentation and datasets will be made publicly available at our website https://robostudioapp.com
ASSIST: Interactive Scene Nodes for Scalable and Realistic Indoor Simulation
Nov 10, 2023



We present ASSIST, an object-wise neural radiance field as a panoptic representation for compositional and realistic simulation. Central to our approach is a novel scene node data structure that stores the information of each object in a unified fashion, allowing online interaction in both intra- and cross-scene settings. By incorporating a differentiable neural network along with the associated bounding box and semantic features, the proposed structure guarantees user-friendly interaction on independent objects to scale up novel view simulation. Objects in the scene can be queried, added, duplicated, deleted, transformed, or swapped simply through mouse/keyboard controls or language instructions. Experiments demonstrate the efficacy of the proposed method, where scaled realistic simulation can be achieved through interactive editing and compositional rendering, with color images, depth images, and panoptic segmentation masks generated in a 3D consistent manner.
MARS: An Instance-aware, Modular and Realistic Simulator for Autonomous Driving
Jul 27, 2023Nowadays, autonomous cars can drive smoothly in ordinary cases, and it is widely recognized that realistic sensor simulation will play a critical role in solving remaining corner cases by simulating them. To this end, we propose an autonomous driving simulator based upon neural radiance fields (NeRFs). Compared with existing works, ours has three notable features: (1) Instance-aware. Our simulator models the foreground instances and background environments separately with independent networks so that the static (e.g., size and appearance) and dynamic (e.g., trajectory) properties of instances can be controlled separately. (2) Modular. Our simulator allows flexible switching between different modern NeRF-related backbones, sampling strategies, input modalities, etc. We expect this modular design to boost academic progress and industrial deployment of NeRF-based autonomous driving simulation. (3) Realistic. Our simulator set new state-of-the-art photo-realism results given the best module selection. Our simulator will be open-sourced while most of our counterparts are not. Project page: https://open-air-sun.github.io/mars/.
Eff-3DPSeg: 3D organ-level plant shoot segmentation using annotation-efficient point clouds
Dec 20, 2022



Reliable and automated 3D plant shoot segmentation is a core prerequisite for the extraction of plant phenotypic traits at the organ level. Combining deep learning and point clouds can provide effective ways to address the challenge. However, fully supervised deep learning methods require datasets to be point-wise annotated, which is extremely expensive and time-consuming. In our work, we proposed a novel weakly supervised framework, Eff-3DPSeg, for 3D plant shoot segmentation. First, high-resolution point clouds of soybean were reconstructed using a low-cost photogrammetry system, and the Meshlab-based Plant Annotator was developed for plant point cloud annotation. Second, a weakly-supervised deep learning method was proposed for plant organ segmentation. The method contained: (1) Pretraining a self-supervised network using Viewpoint Bottleneck loss to learn meaningful intrinsic structure representation from the raw point clouds; (2) Fine-tuning the pre-trained model with about only 0.5% points being annotated to implement plant organ segmentation. After, three phenotypic traits (stem diameter, leaf width, and leaf length) were extracted. To test the generality of the proposed method, the public dataset Pheno4D was included in this study. Experimental results showed that the weakly-supervised network obtained similar segmentation performance compared with the fully-supervised setting. Our method achieved 95.1%, 96.6%, 95.8% and 92.2% in the Precision, Recall, F1-score, and mIoU for stem leaf segmentation and 53%, 62.8% and 70.3% in the AP, AP@25, and AP@50 for leaf instance segmentation. This study provides an effective way for characterizing 3D plant architecture, which will become useful for plant breeders to enhance selection processes.
VIBUS: Data-efficient 3D Scene Parsing with VIewpoint Bottleneck and Uncertainty-Spectrum Modeling
Oct 20, 2022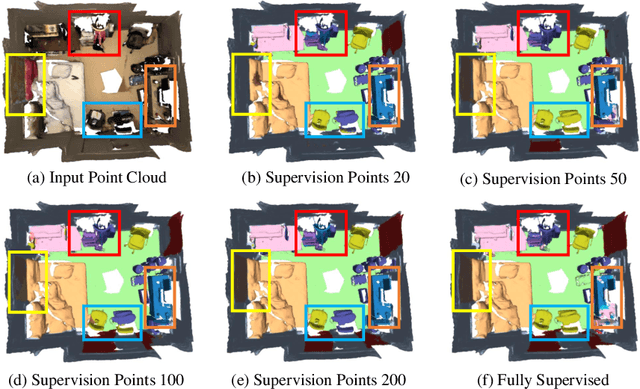
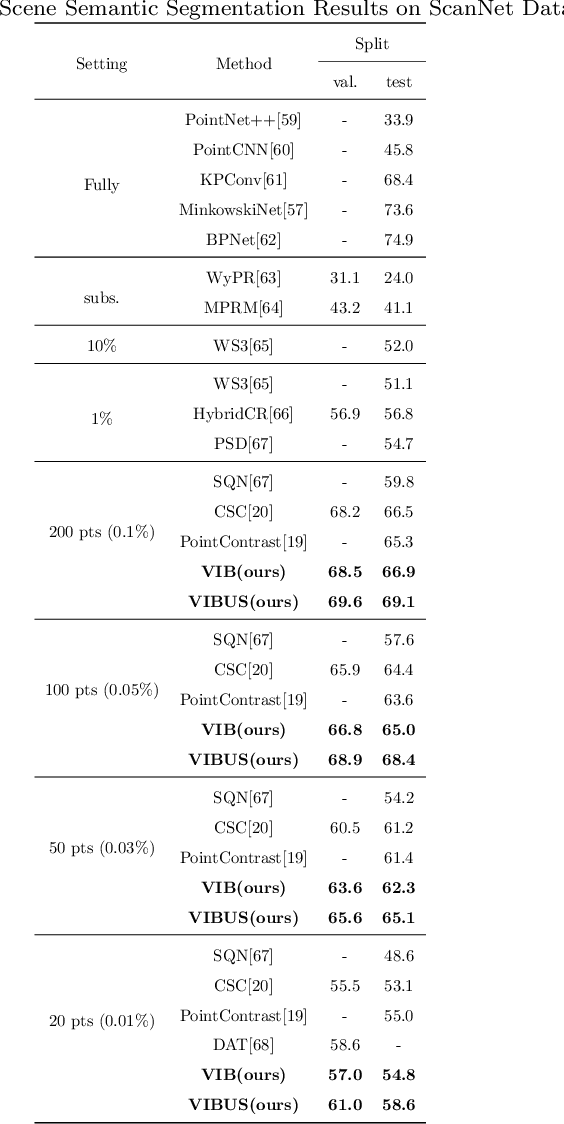
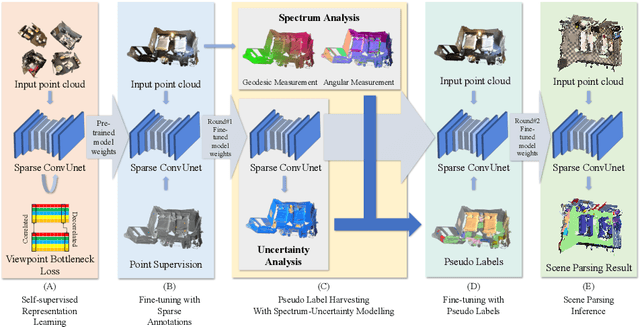
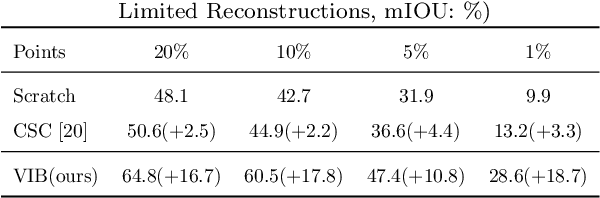
Recently, 3D scenes parsing with deep learning approaches has been a heating topic. However, current methods with fully-supervised models require manually annotated point-wise supervision which is extremely user-unfriendly and time-consuming to obtain. As such, training 3D scene parsing models with sparse supervision is an intriguing alternative. We term this task as data-efficient 3D scene parsing and propose an effective two-stage framework named VIBUS to resolve it by exploiting the enormous unlabeled points. In the first stage, we perform self-supervised representation learning on unlabeled points with the proposed Viewpoint Bottleneck loss function. The loss function is derived from an information bottleneck objective imposed on scenes under different viewpoints, making the process of representation learning free of degradation and sampling. In the second stage, pseudo labels are harvested from the sparse labels based on uncertainty-spectrum modeling. By combining data-driven uncertainty measures and 3D mesh spectrum measures (derived from normal directions and geodesic distances), a robust local affinity metric is obtained. Finite gamma/beta mixture models are used to decompose category-wise distributions of these measures, leading to automatic selection of thresholds. We evaluate VIBUS on the public benchmark ScanNet and achieve state-of-the-art results on both validation set and online test server. Ablation studies show that both Viewpoint Bottleneck and uncertainty-spectrum modeling bring significant improvements. Codes and models are publicly available at https://github.com/AIR-DISCOVER/VIBUS.
Pointly-supervised 3D Scene Parsing with Viewpoint Bottleneck
Sep 17, 2021
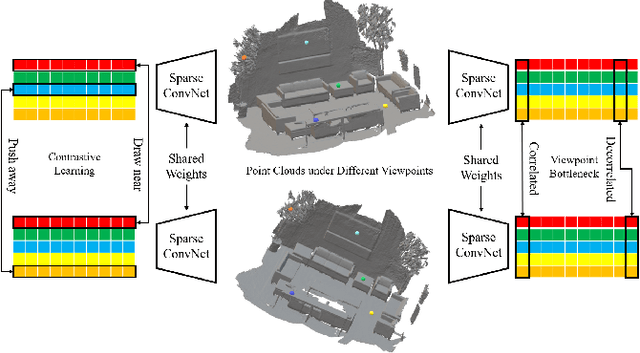


Semantic understanding of 3D point clouds is important for various robotics applications. Given that point-wise semantic annotation is expensive, in this paper, we address the challenge of learning models with extremely sparse labels. The core problem is how to leverage numerous unlabeled points. To this end, we propose a self-supervised 3D representation learning framework named viewpoint bottleneck. It optimizes a mutual-information based objective, which is applied on point clouds under different viewpoints. A principled analysis shows that viewpoint bottleneck leads to an elegant surrogate loss function that is suitable for large-scale point cloud data. Compared with former arts based upon contrastive learning, viewpoint bottleneck operates on the feature dimension instead of the sample dimension. This paradigm shift has several advantages: It is easy to implement and tune, does not need negative samples and performs better on our goal down-streaming task. We evaluate our method on the public benchmark ScanNet, under the pointly-supervised setting. We achieve the best quantitative results among comparable solutions. Meanwhile we provide an extensive qualitative inspection on various challenging scenes. They demonstrate that our models can produce fairly good scene parsing results for robotics applications. Our code, data and models will be made public.