 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointly-supervised 3D Scene Parsing with Viewpoint Bottleneck
Paper and Code

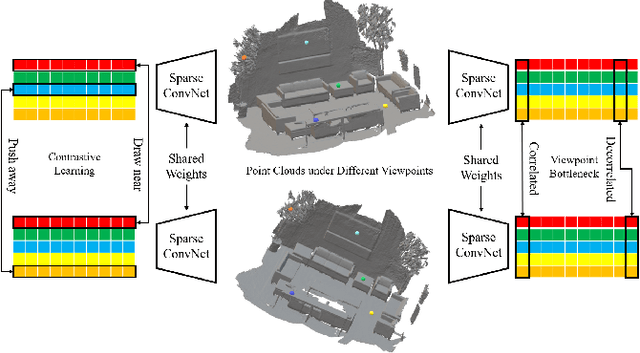


Semantic understanding of 3D point clouds is important for various robotics applications. Given that point-wise semantic annotation is expensive, in this paper, we address the challenge of learning models with extremely sparse labels. The core problem is how to leverage numerous unlabeled points. To this end, we propose a self-supervised 3D representation learning framework named viewpoint bottleneck. It optimizes a mutual-information based objective, which is applied on point clouds under different viewpoints. A principled analysis shows that viewpoint bottleneck leads to an elegant surrogate loss function that is suitable for large-scale point cloud data. Compared with former arts based upon contrastive learning, viewpoint bottleneck operates on the feature dimension instead of the sample dimension. This paradigm shift has several advantages: It is easy to implement and tune, does not need negative samples and performs better on our goal down-streaming task. We evaluate our method on the public benchmark ScanNet, under the pointly-supervised setting. We achieve the best quantitative results among comparable solutions. Meanwhile we provide an extensive qualitative inspection on various challenging scenes. They demonstrate that our models can produce fairly good scene parsing results for robotics applications. Our code, data and models will be made public.