 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld In Your Hands: A Large-Scale and Open-source Ecosystem for Learning Human-centric Manipulation in the Wild
Dec 30, 2025Large-scale pre-training is fundamental for generalization in language and vision models, but data for dexterous hand manipulation remains limited in scale and diversity, hindering policy generalization. Limited scenario diversity, misaligned modalities, and insufficient benchmarking constrain current human manipulation datasets. To address these gaps, we introduce World In Your Hands (WiYH), a large-scale open-source ecosystem for human-centric manipulation learning. WiYH includes (1) the Oracle Suite, a wearable data collection kit with an auto-labeling pipeline for accurate motion capture; (2) the WiYH Dataset, featuring over 1,000 hours of multi-modal manipulation data across hundreds of skills in diverse real-world scenarios; and (3) extensive annotations and benchmarks supporting tasks from perception to action. Furthermore, experiments based on the WiYH ecosystem show that integrating WiYH's human-centric data significantly enhances the generalization and robustness of dexterous hand policies in tabletop manipulation tasks. We believe that World In Your Hands will bring new insights into human-centric data collection and policy learning to the community.
OccTENS: 3D Occupancy World Model via Temporal Next-Scale Prediction
Sep 04, 2025In this paper, we propose OccTENS, a generative occupancy world model that enables controllable, high-fidelity long-term occupancy generation while maintaining computational efficiency. Different from visual generation, the occupancy world model must capture the fine-grained 3D geometry and dynamic evolution of the 3D scenes, posing great challenges for the generative models. Recent approaches based on autoregression (AR) have demonstrated the potential to predict vehicle movement and future occupancy scenes simultaneously from historical observations, but they typically suffer from \textbf{inefficiency}, \textbf{temporal degradation} in long-term generation and \textbf{lack of controllability}. To holistically address these issues, we reformulate the occupancy world model as a temporal next-scale prediction (TENS) task, which decomposes the temporal sequence modeling problem into the modeling of spatial scale-by-scale generation and temporal scene-by-scene prediction. With a \textbf{TensFormer}, OccTENS can effectively manage the temporal causality and spatial relationships of occupancy sequences in a flexible and scalable way. To enhance the pose controllability, we further propose a holistic pose aggregation strategy, which features a unified sequence modeling for occupancy and ego-motion. Experiments show that OccTENS outperforms the state-of-the-art method with both higher occupancy quality and faster inference time.
MAG: Multi-Modal Aligned Autoregressive Co-Speech Gesture Generation without Vector Quantization
Mar 18, 2025This work focuses on full-body co-speech gesture generation. Existing methods typically employ an autoregressive model accompanied by vector-quantized tokens for gesture generation, which results in information loss and compromises the realism of the generated gestures. To address this, inspired by the natural continuity of real-world human motion, we propose MAG, a novel multi-modal aligned framework for high-quality and diverse co-speech gesture synthesis without relying on discrete tokenization. Specifically, (1) we introduce a motion-text-audio-aligned variational autoencoder (MTA-VAE), which leverages pre-trained WavCaps' text and audio embeddings to enhance both semantic and rhythmic alignment with motion, ultimately producing more realistic gestures. (2) Building on this, we propose a multimodal masked autoregressive model (MMAG) that enables autoregressive modeling in continuous motion embeddings through diffusion without vector quantization. To further ensure multi-modal consistency, MMAG incorporates a hybrid granularity audio-text fusion block, which serves as conditioning for diffusion process. Extensive experiments on two benchmark datasets demonstrate that MAG achieves stateof-the-art performance both quantitatively and qualitatively, producing highly realistic and diverse co-speech gestures.The code will be released to facilitate future research.
VRsketch2Gaussian: 3D VR Sketch Guided 3D Object Generation with Gaussian Splatting
Mar 16, 2025We propose VRSketch2Gaussian, a first VR sketch-guided, multi-modal, native 3D object generation framework that incorporates a 3D Gaussian Splatting representation. As part of our work, we introduce VRSS, the first large-scale paired dataset containing VR sketches, text, images, and 3DGS, bridging the gap in multi-modal VR sketch-based generation. Our approach features the following key innovations: 1) Sketch-CLIP feature alignment. We propose a two-stage alignment strategy that bridges the domain gap between sparse VR sketch embeddings and rich CLIP embeddings, facilitating both VR sketch-based retrieval and generation tasks. 2) Fine-Grained multi-modal conditioning. We disentangle the 3D generation process by using explicit VR sketches for geometric conditioning and text descriptions for appearance control. To facilitate this, we propose a generalizable VR sketch encoder that effectively aligns different modalities. 3) Efficient and high-fidelity 3D native generation. Our method leverages a 3D-native generation approach that enables fast and texture-rich 3D object synthesis. Experiments conducted on our VRSS dataset demonstrate that our method achieves high-quality, multi-modal VR sketch-based 3D generation. We believe our VRSS dataset and VRsketch2Gaussian method will be beneficial for the 3D generation community.
DOME: Taming Diffusion Model into High-Fidelity Controllable Occupancy World Model
Oct 14, 2024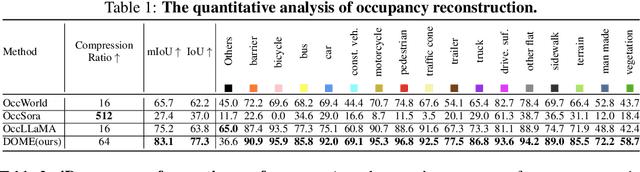

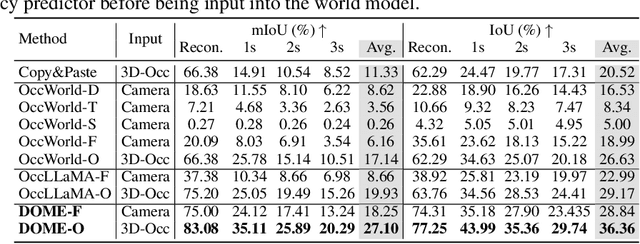
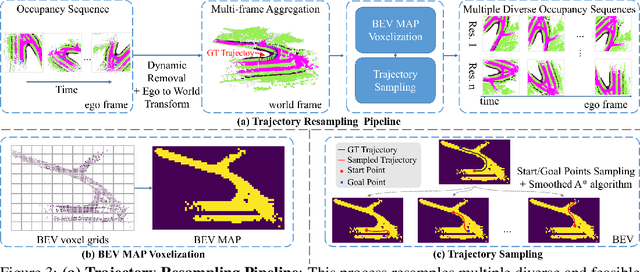
We propose DOME, a diffusion-based world model that predicts future occupancy frames based on past occupancy observations. The ability of this world model to capture the evolution of the environment is crucial for planning in autonomous driving. Compared to 2D video-based world models, the occupancy world model utilizes a native 3D representation, which features easily obtainable annotations and is modality-agnostic. This flexibility has the potential to facilitate the development of more advanced world models. Existing occupancy world models either suffer from detail loss due to discrete tokenization or rely on simplistic diffusion architectures, leading to inefficiencies and difficulties in predicting future occupancy with controllability. Our DOME exhibits two key features:(1) High-Fidelity and Long-Duration Generation. We adopt a spatial-temporal diffusion transformer to predict future occupancy frames based on historical context. This architecture efficiently captures spatial-temporal information, enabling high-fidelity details and the ability to generate predictions over long durations. (2)Fine-grained Controllability. We address the challenge of controllability in predictions by introducing a trajectory resampling method, which significantly enhances the model's ability to generate controlled predictions. Extensive experiments on the widely used nuScenes dataset demonstrate that our method surpasses existing baselines in both qualitative and quantitative evaluations, establishing a new state-of-the-art performance on nuScenes. Specifically, our approach surpasses the baseline by 10.5% in mIoU and 21.2% in IoU for occupancy reconstruction and by 36.0% in mIoU and 24.6% in IoU for 4D occupancy forecasting.
HE-Drive: Human-Like End-to-End Driving with Vision Language Models
Oct 07, 2024In this paper, we propose HE-Drive: the first human-like-centric end-to-end autonomous driving system to generate trajectories that are both temporally consistent and comfortable. Recent studies have shown that imitation learning-based planners and learning-based trajectory scorers can effectively generate and select accuracy trajectories that closely mimic expert demonstrations. However, such trajectory planners and scorers face the dilemma of generating temporally inconsistent and uncomfortable trajectories. To solve the above problems, Our HE-Drive first extracts key 3D spatial representations through sparse perception, which then serves as conditional inputs for a Conditional Denoising Diffusion Probabilistic Models (DDPMs)-based motion planner to generate temporal consistency multi-modal trajectories. A Vision-Language Models (VLMs)-guided trajectory scorer subsequently selects the most comfortable trajectory from these candidates to control the vehicle, ensuring human-like end-to-end driving. Experiments show that HE-Drive not only achieves state-of-the-art performance (i.e., reduces the average collision rate by 71% than VAD) and efficiency (i.e., 1.9X faster than SparseDrive) on the challenging nuScenes and OpenScene datasets but also provides the most comfortable driving experience on real-world data.For more information, visit the project website: https://jmwang0117.github.io/HE-Drive/.
GaussianGrasper: 3D Language Gaussian Splatting for Open-vocabulary Robotic Grasping
Mar 14, 2024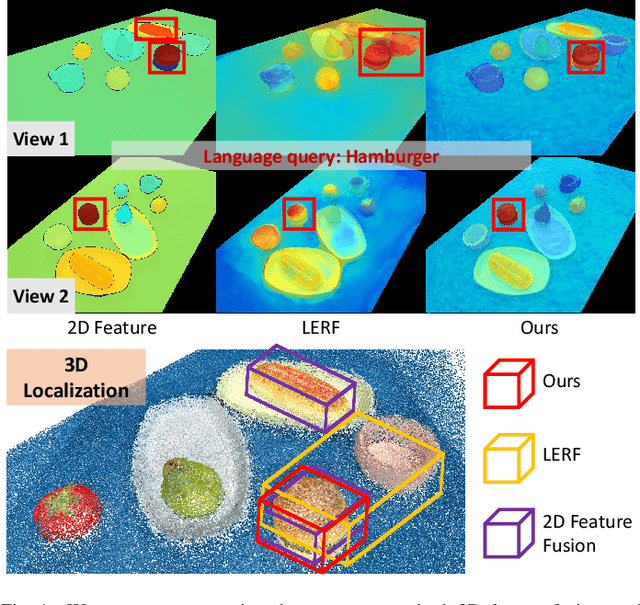
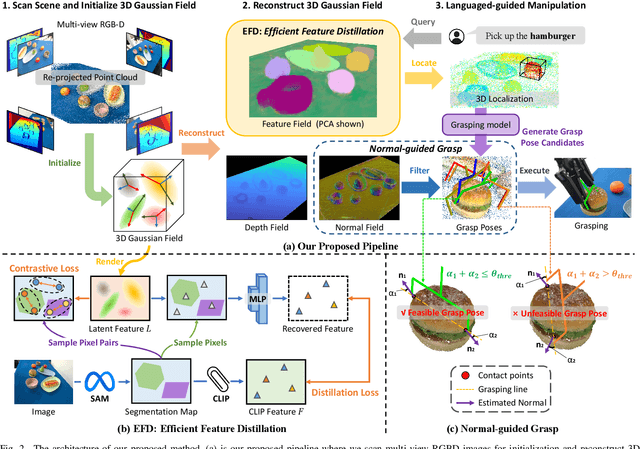
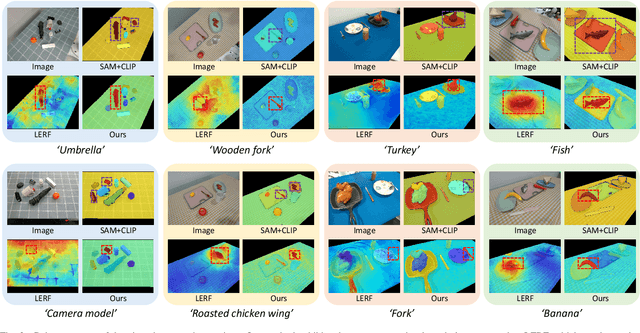

Constructing a 3D scene capable of accommodating open-ended language queries, is a pivotal pursuit, particularly within the domain of robotics. Such technology facilitates robots in executing object manipulations based on human language directives. To tackle this challenge, some research efforts have been dedicated to the development of language-embedded implicit fields. However, implicit fields (e.g. NeRF) encounter limitations due to the necessity of processing a large number of input views for reconstruction, coupled with their inherent inefficiencies in inference. Thus, we present the GaussianGrasper, which utilizes 3D Gaussian Splatting to explicitly represent the scene as a collection of Gaussian primitives. Our approach takes a limited set of RGB-D views and employs a tile-based splatting technique to create a feature field. In particular, we propose an Efficient Feature Distillation (EFD) module that employs contrastive learning to efficiently and accurately distill language embeddings derived from foundational models. With the reconstructed geometry of the Gaussian field, our method enables the pre-trained grasping model to generate collision-free grasp pose candidates. Furthermore, we propose a normal-guided grasp module to select the best grasp pose. Through comprehensive real-world experiments, we demonstrate that GaussianGrasper enables robots to accurately query and grasp objects with language instructions, providing a new solution for language-guided manipulation tasks. Data and codes can be available at https://github.com/MrSecant/GaussianGrasper.
Text2Street: Controllable Text-to-image Generation for Street Views
Feb 07, 2024Text-to-image generation has made remarkable progress with the emergence of diffusion models. However, it is still a difficult task to generate images for street views based on text, mainly because the road topology of street scenes is complex, the traffic status is diverse and the weather condition is various, which makes conventional text-to-image models difficult to deal with. To address these challenges, we propose a novel controllable text-to-image framework, named \textbf{Text2Street}. In the framework, we first introduce the lane-aware road topology generator, which achieves text-to-map generation with the accurate road structure and lane lines armed with the counting adapter, realizing the controllable road topology generation. Then, the position-based object layout generator is proposed to obtain text-to-layout generation through an object-level bounding box diffusion strategy, realizing the controllable traffic object layout generation. Finally, the multiple control image generator is designed to integrate the road topology, object layout and weather description to realize controllable street-view image generation. Extensive experiments show that the proposed approach achieves controllable street-view text-to-image generation and validates the effectiveness of the Text2Street framework for street views.
ASSIST: Interactive Scene Nodes for Scalable and Realistic Indoor Simulation
Nov 10, 2023



We present ASSIST, an object-wise neural radiance field as a panoptic representation for compositional and realistic simulation. Central to our approach is a novel scene node data structure that stores the information of each object in a unified fashion, allowing online interaction in both intra- and cross-scene settings. By incorporating a differentiable neural network along with the associated bounding box and semantic features, the proposed structure guarantees user-friendly interaction on independent objects to scale up novel view simulation. Objects in the scene can be queried, added, duplicated, deleted, transformed, or swapped simply through mouse/keyboard controls or language instructions. Experiments demonstrate the efficacy of the proposed method, where scaled realistic simulation can be achieved through interactive editing and compositional rendering, with color images, depth images, and panoptic segmentation masks generated in a 3D consistent manner.